最近三家都推出了VLA的辅助驾驶模型,一下子大家都知道了。还有一个路线是世界模型,现在路线看似出了分歧,谁都不知道哪个会最后胜利。 看了佐思汽车的文章,给大家总结下目前的状况。
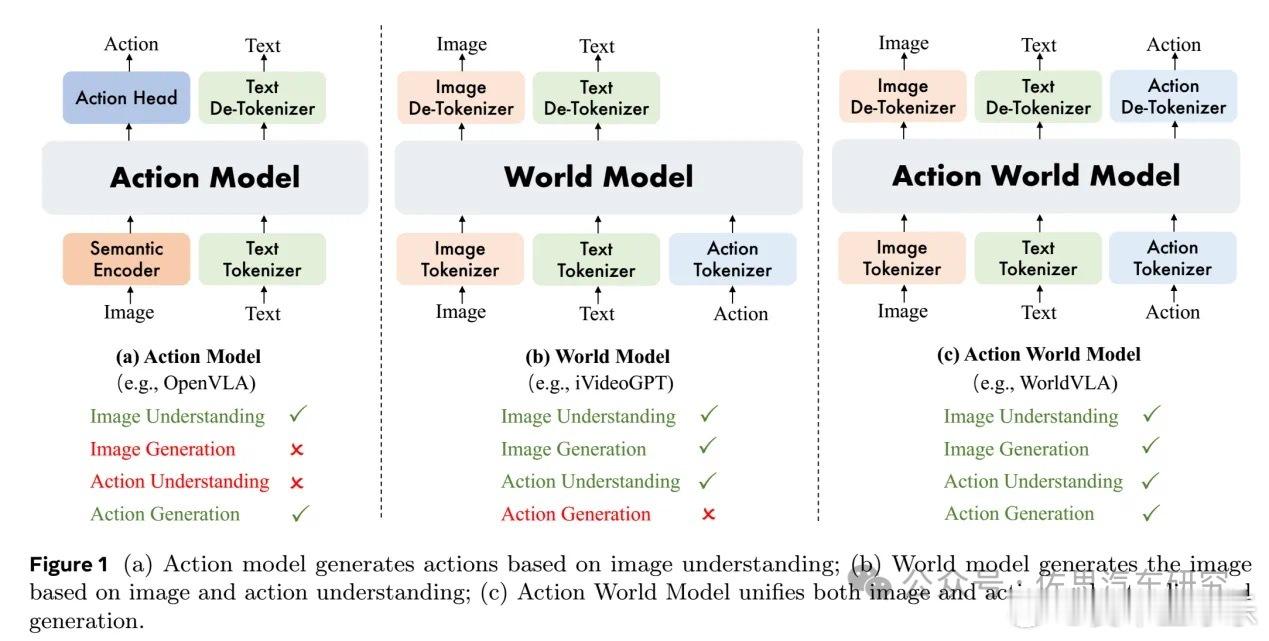
世界模型路线认为,仅凭文字与图像生成,AI无法真正理解世界。VLA中间有一个文字层,相当于我们思考和传达时候的说话,文字是一种信息的压缩方式。它们虽然能对提问给出看似合理的回答,却缺乏对物理现实的感知与推理能力。
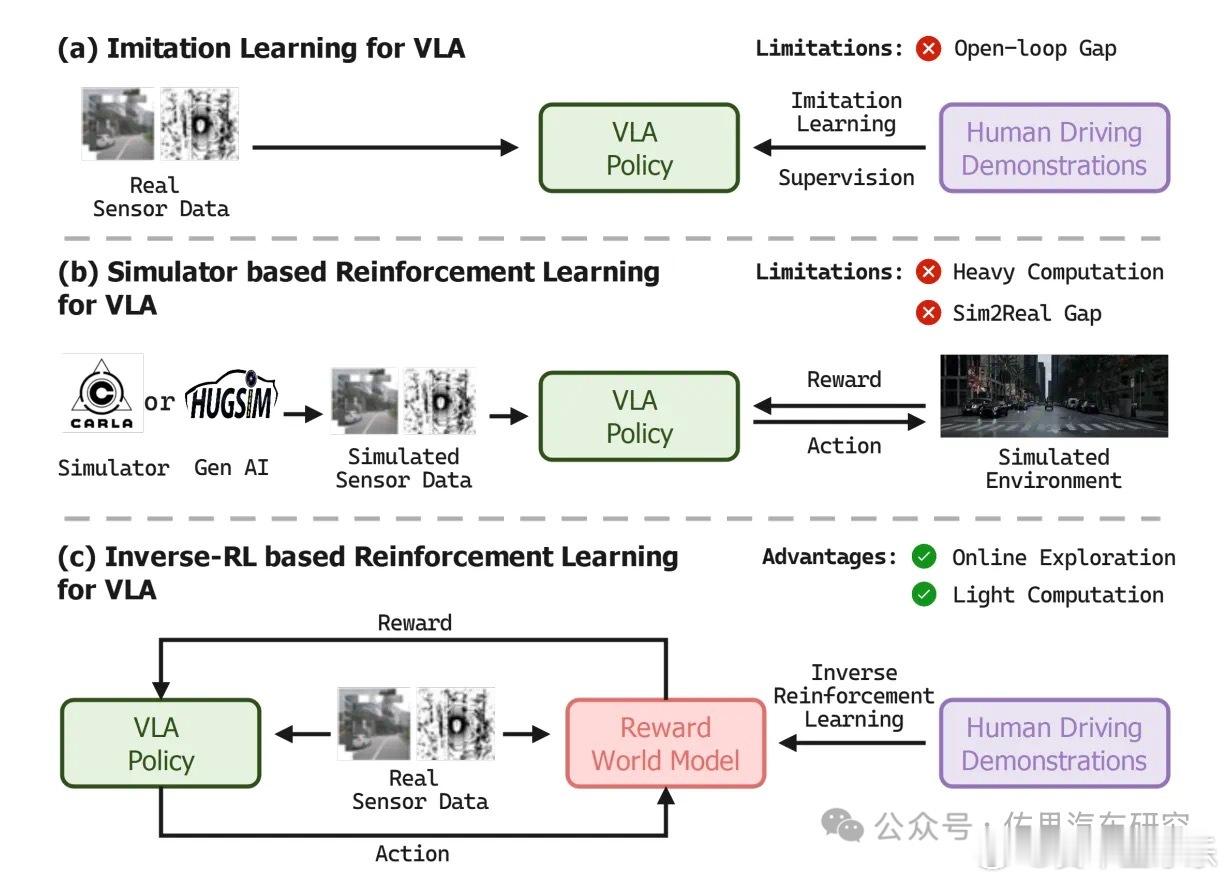
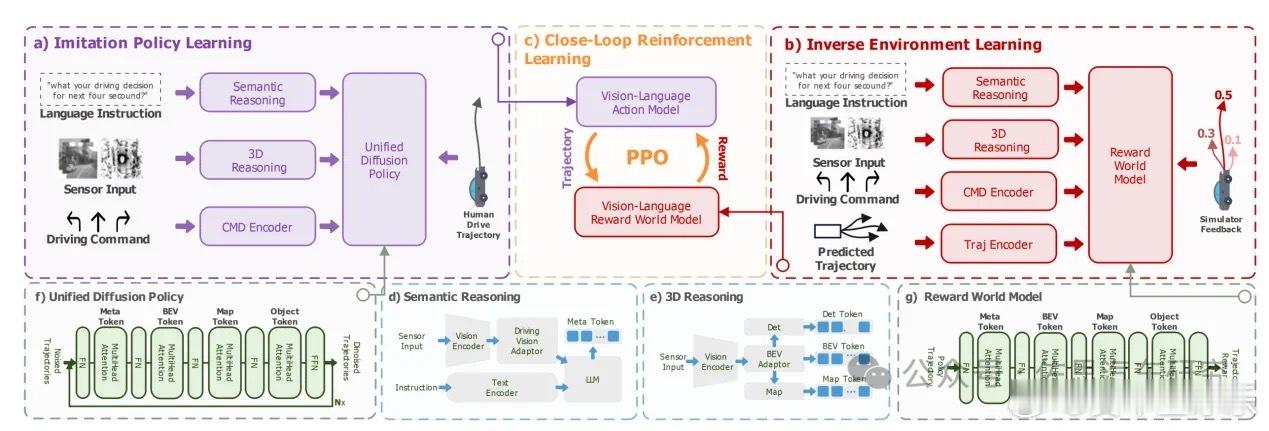
VLA最大的缺点是基于文字(语言),也就是离不开L(Language ),中间多了一个转接层,世界模型是跳过这个L,直接到Action,是真正意义上的端到端。
世界模型出现比VLA要早,模型可以看无标注的视频,推测被遮蔽的动态与结果,它优势是非逐点像素计算,运算资源需求低于VLA;训练数据无需任何标注,可以全部使用网络资源。
世界模型可以理解物理世界背后的运行规律,它可能不能总结出公式这样的规则,但它能根据规律准确预测下一步结果。
VLA最大的好处是它可以微调,可以用世界模型或者说基于模型的强化学习微调,它可以吸收世界模型的优点,而世界模型无法利用VLM/VLA的优点,当然VLA最大缺点是运算资源特别是存储带宽消耗比较多。
他们俩不是完全对立,VLA和世界模型相互增强的。世界模型和VLA,VLA大概率胜出,不过这个VLA不是纯粹VLA,是结合了世界模型增强的VLA。
汽车新知加油站VLA