[LG]《OverFill: Two-Stage Models for Efficient Language Model Decoding》W Kim, J Wang, J N Yan, M Abdelfattah... [Cornell University] (2025)
OverFill:面向高效语言模型解码的两阶段模型创新方案
• 传统大语言模型推理分为prefill(计算密集)和decode(内存密集)两阶段,现有模型对两阶段采用同一架构,未区分优化。
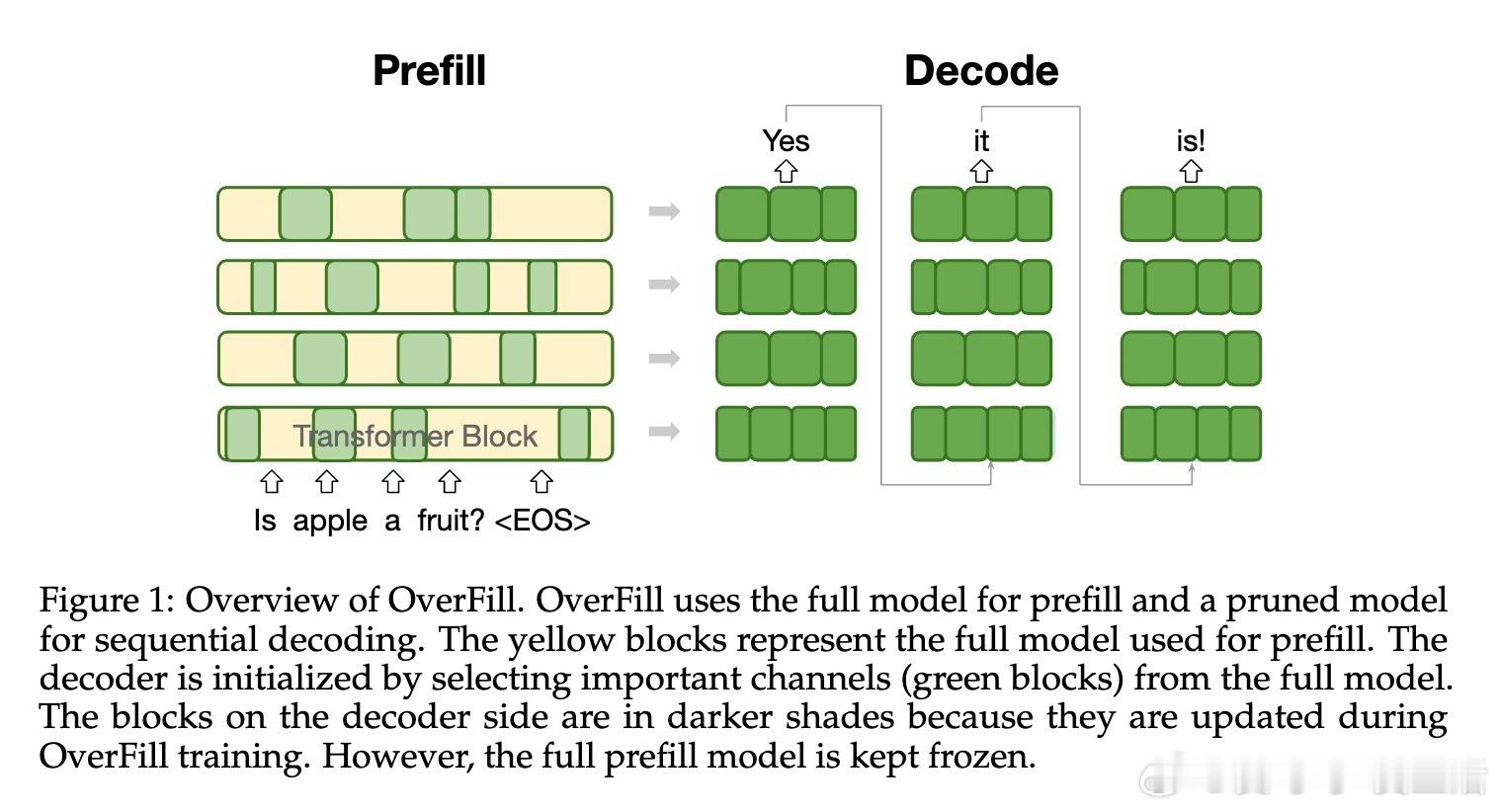
• OverFill提出prefill阶段使用完整模型,decode阶段采用兼容剪枝后的轻量模型,有效减少解码时的参数加载和内存占用。
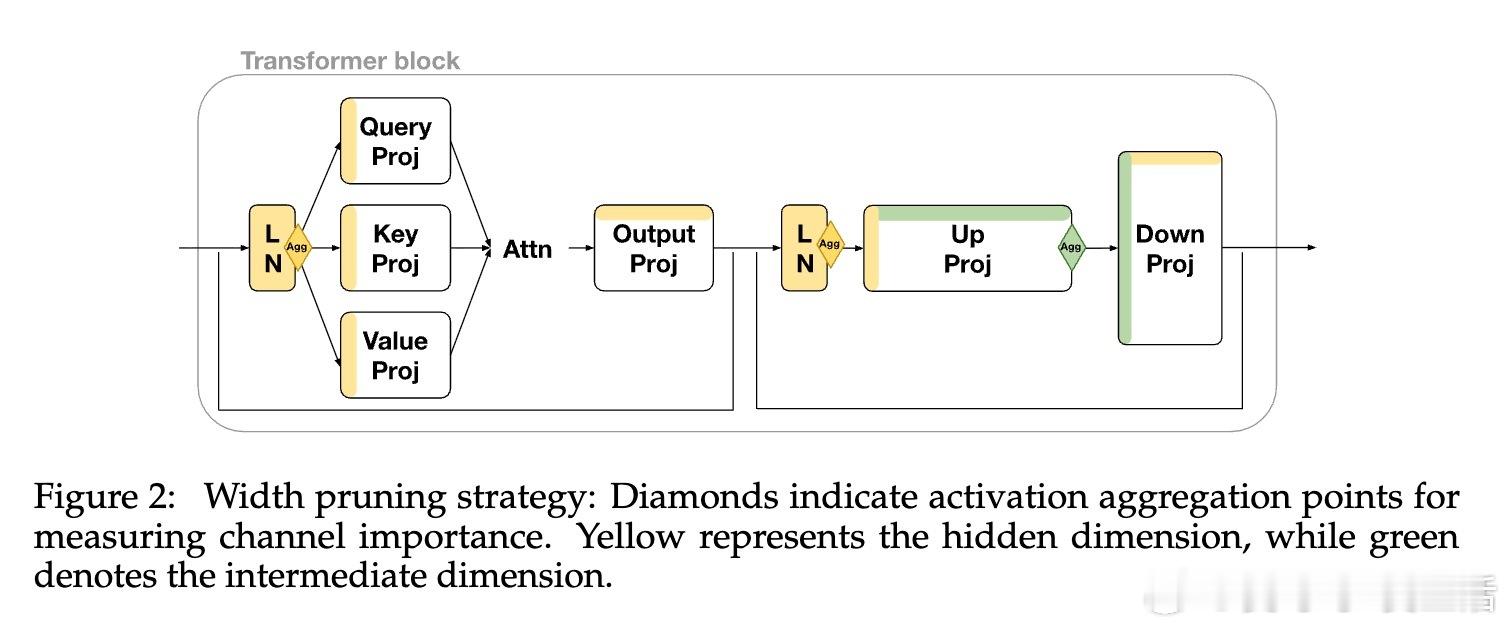
• 通过宽度剪枝保持KV缓存维度兼容,确保两阶段模型共享缓存表示,支持端到端训练且只微调剪枝后解码器。
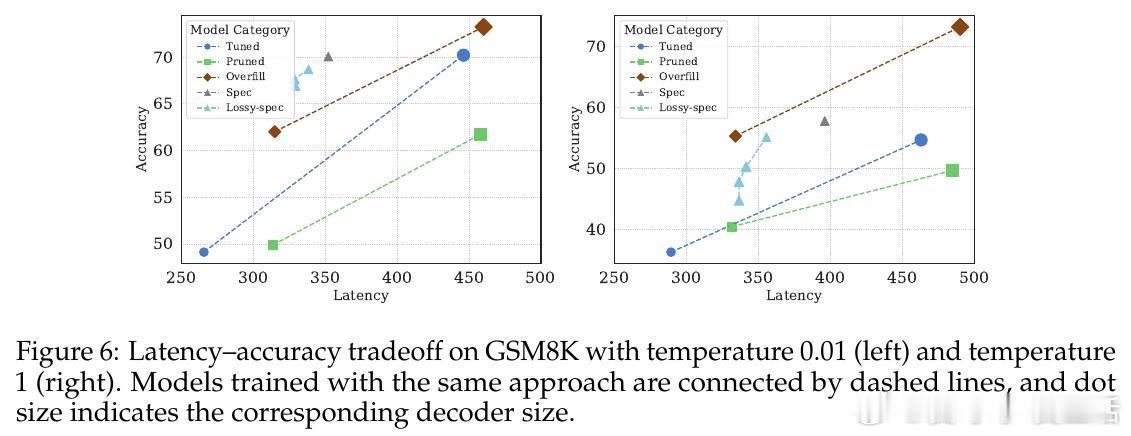
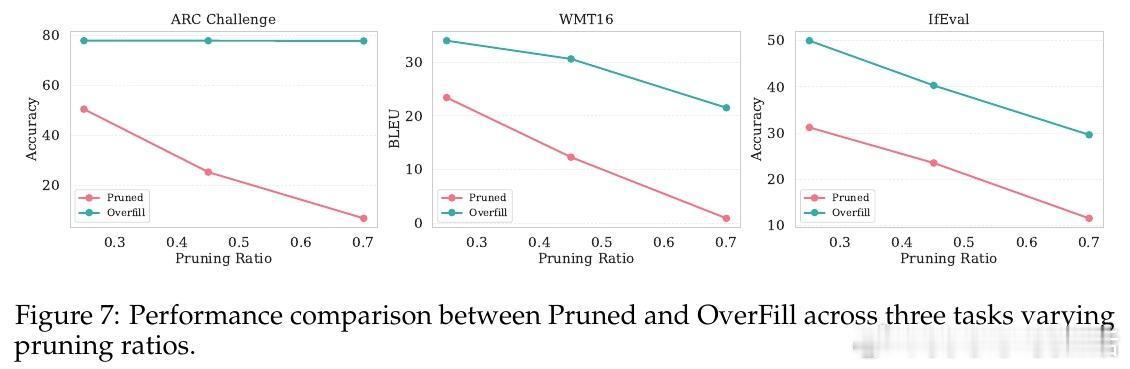
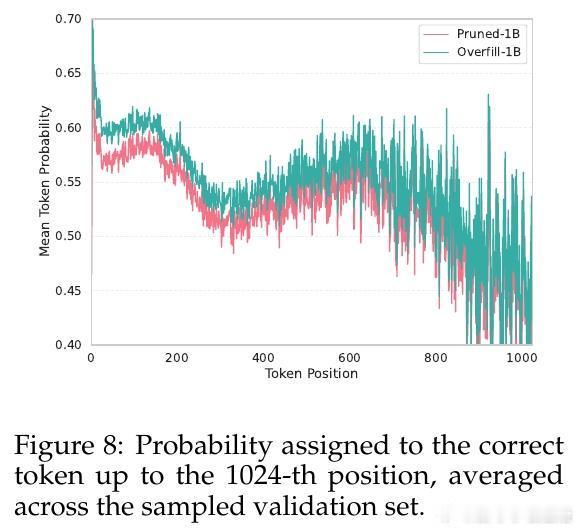
• 在3B→1B和8B→3B配置中,OverFill分别比同规模剪枝模型提升83.2%和79.2%准确率,且训练数据需求更少,性能媲美从零训练同尺度模型。
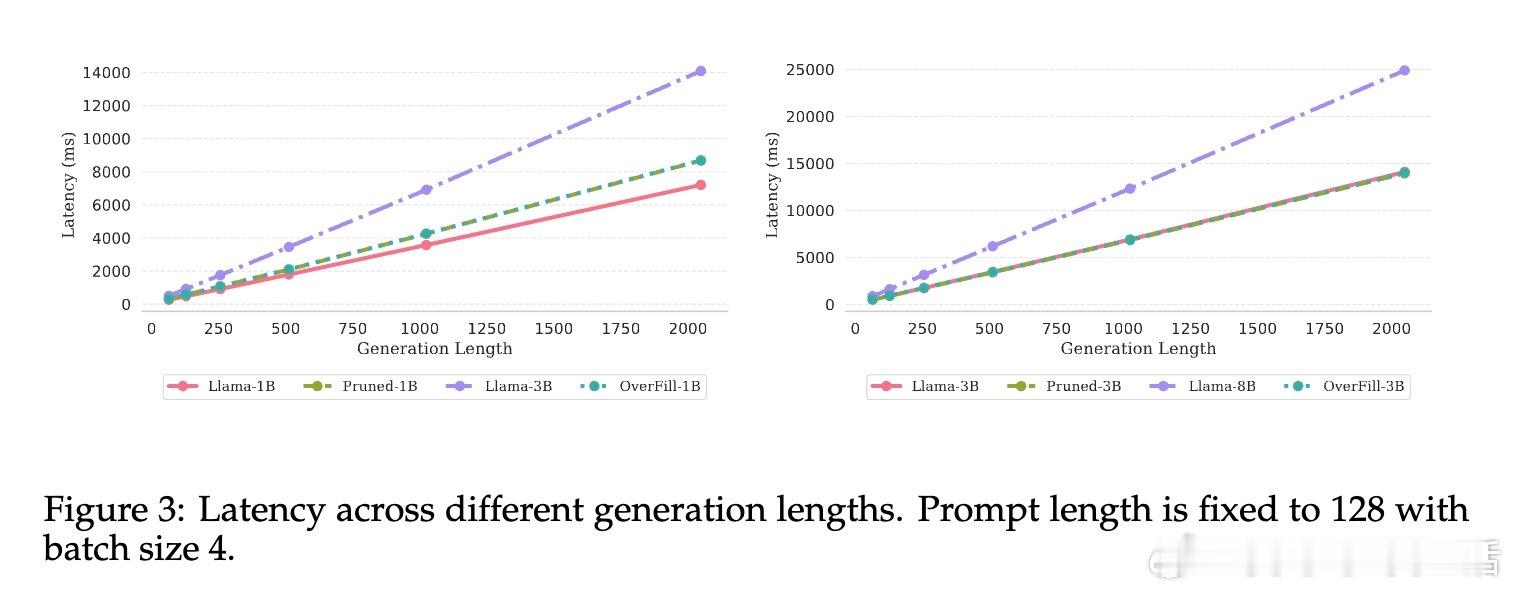
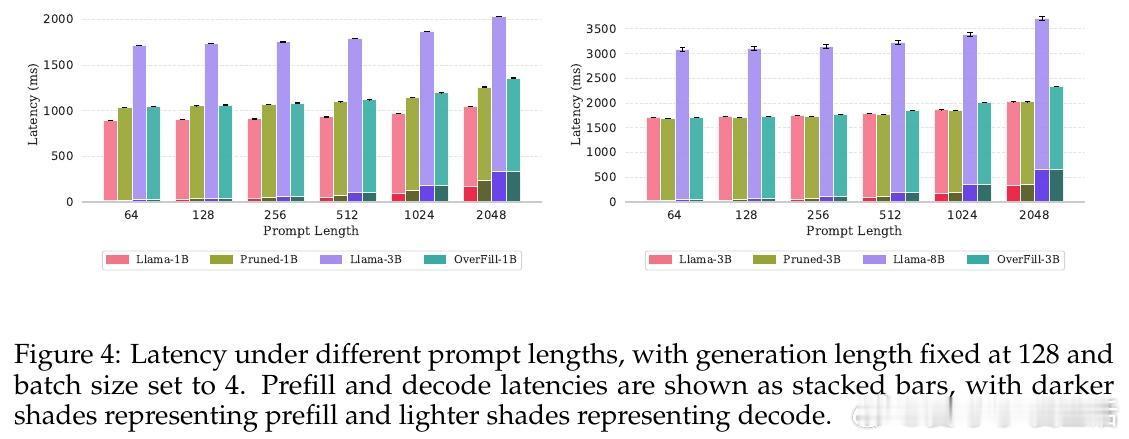
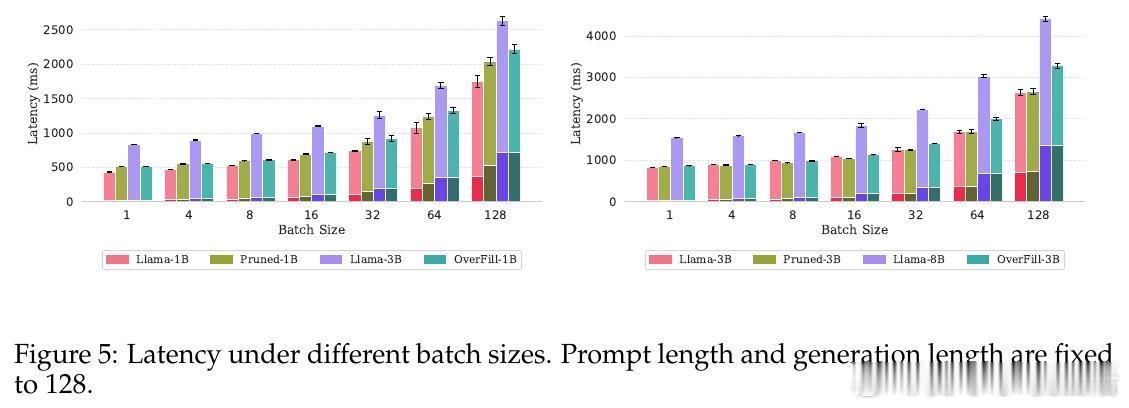
• 该方法显著降低长序列生成的延迟,解码阶段速度接近小模型,prefill阶段开销相对较小,整体实现Pareto最优的准确率与效率平衡。
• 对比推测解码,OverFill消除回滚和拒绝采样,提升多请求场景的吞吐率,适合实际在线服务部署。
• 未来可探索注意力剪枝、量化等结合方案,进一步压缩KV缓存与提升推理速度。
了解详情🔗arxiv.org/abs/2508.08446
大语言模型模型剪枝高效推理机器学习人工智能