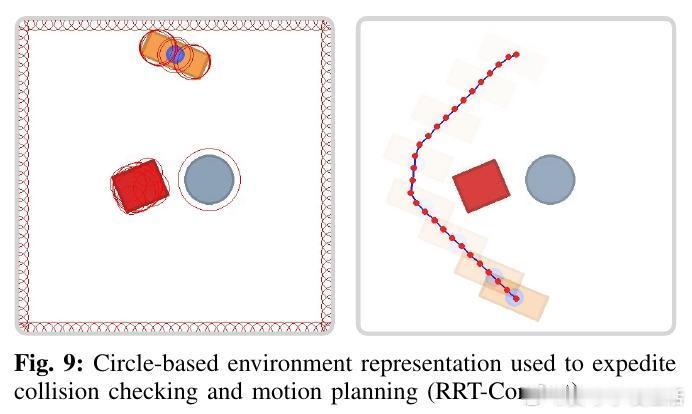
[RO]《Rational Inverse Reasoning》B Zandonati, T Lozano-Pérez, L P Kaelbling [MIT CSAIL] (2025)
Rational Inverse Reasoning(RIR)提出一种结合结构化规划与大规模预训练视觉语言模型的全新框架,实现了从极少示范中推断潜在任务解释程序,显著提升机器人对复杂物理推理任务的泛化能力。
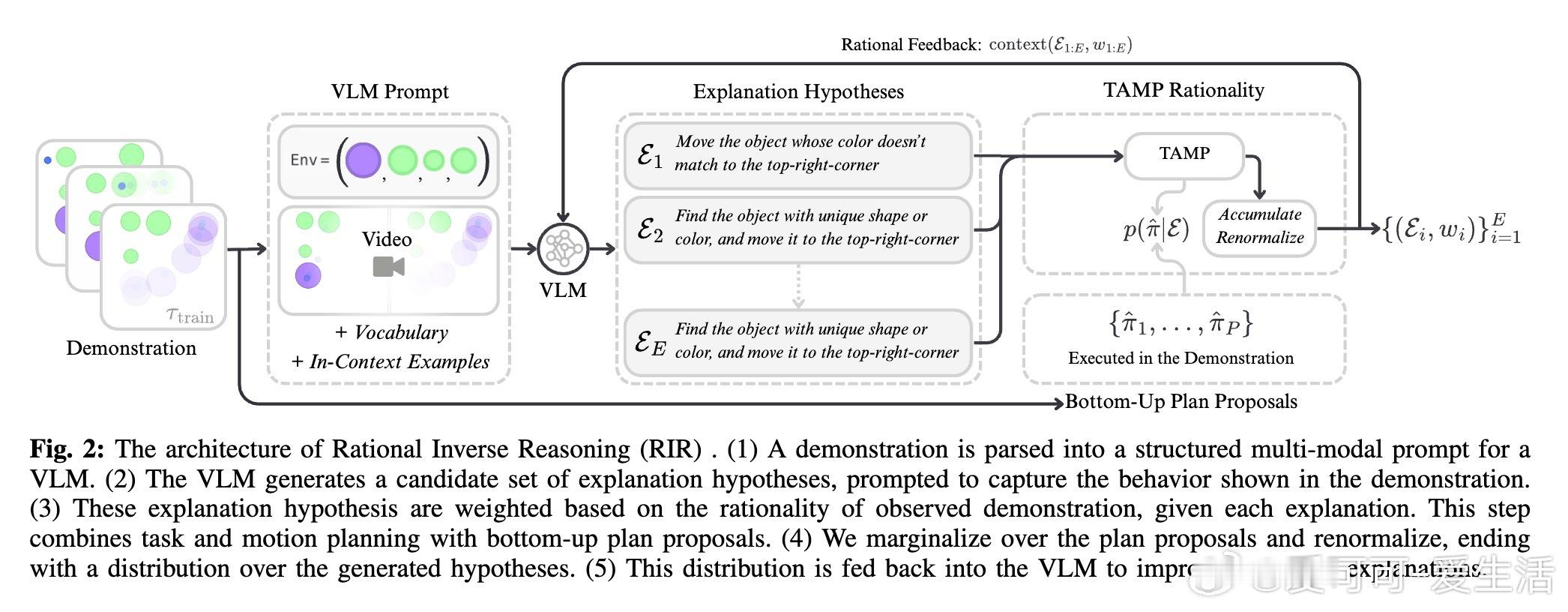
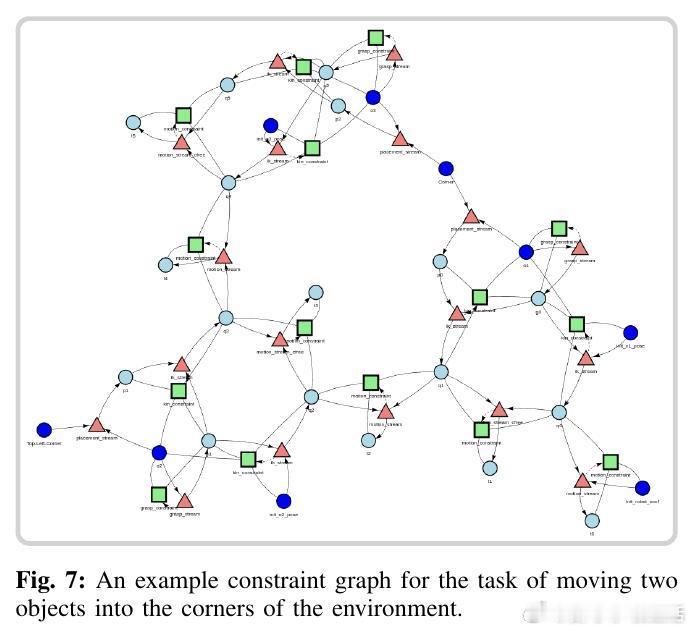
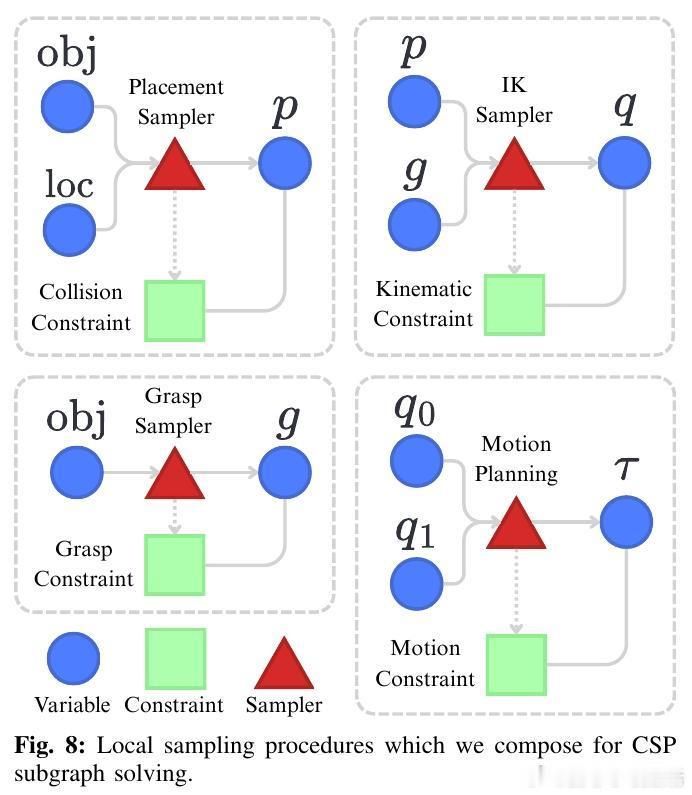
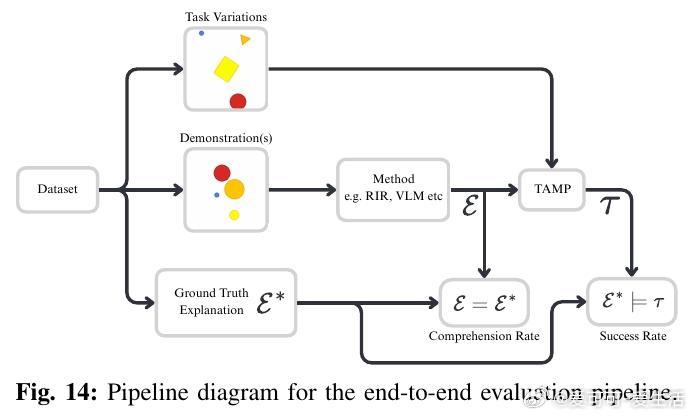
• 核心创新:将少样本模仿学习视为贝叶斯程序归纳,VLM(视觉语言模型)生成符号化任务假设,任务与运动规划(TAMP)内循环评估示范行为的理性度,构建解释程序的后验分布。
• 理性假设:模拟演示者为有限理性规划者,行为近似最优但允许逻辑与轨迹层面瑕疵,采用软最小成本(Boltzmann)模型评估计划选择与执行合理性。
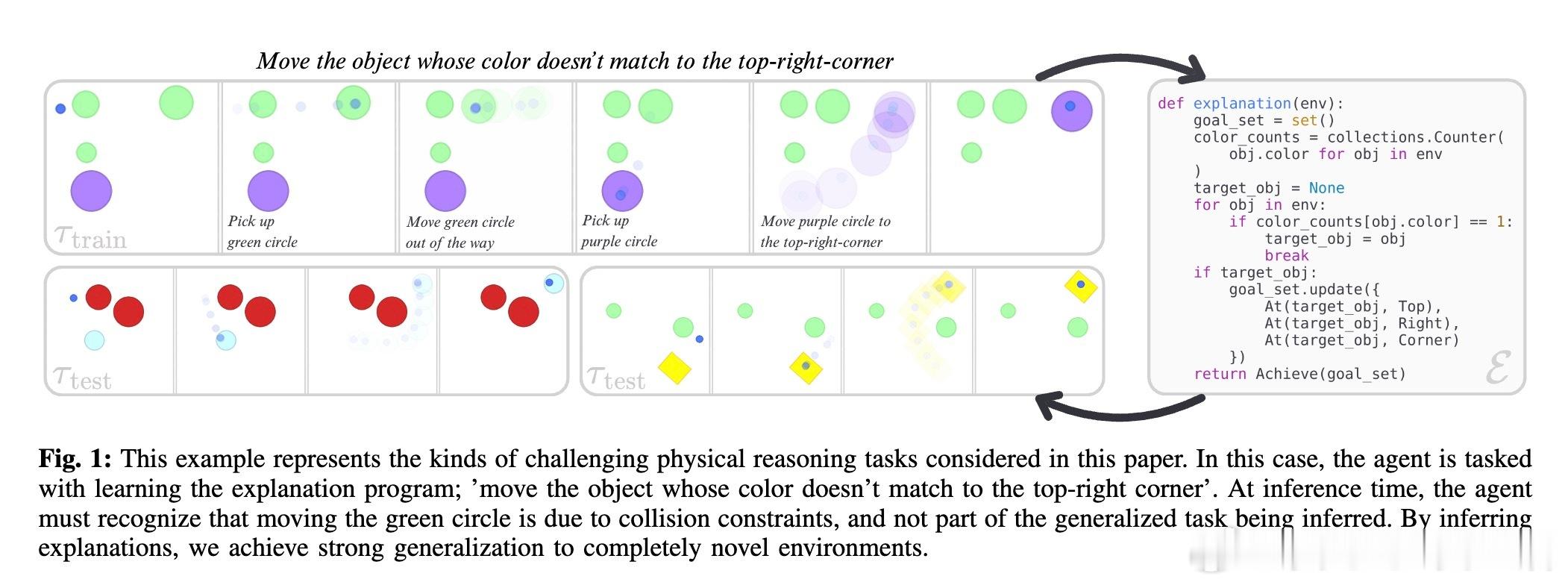
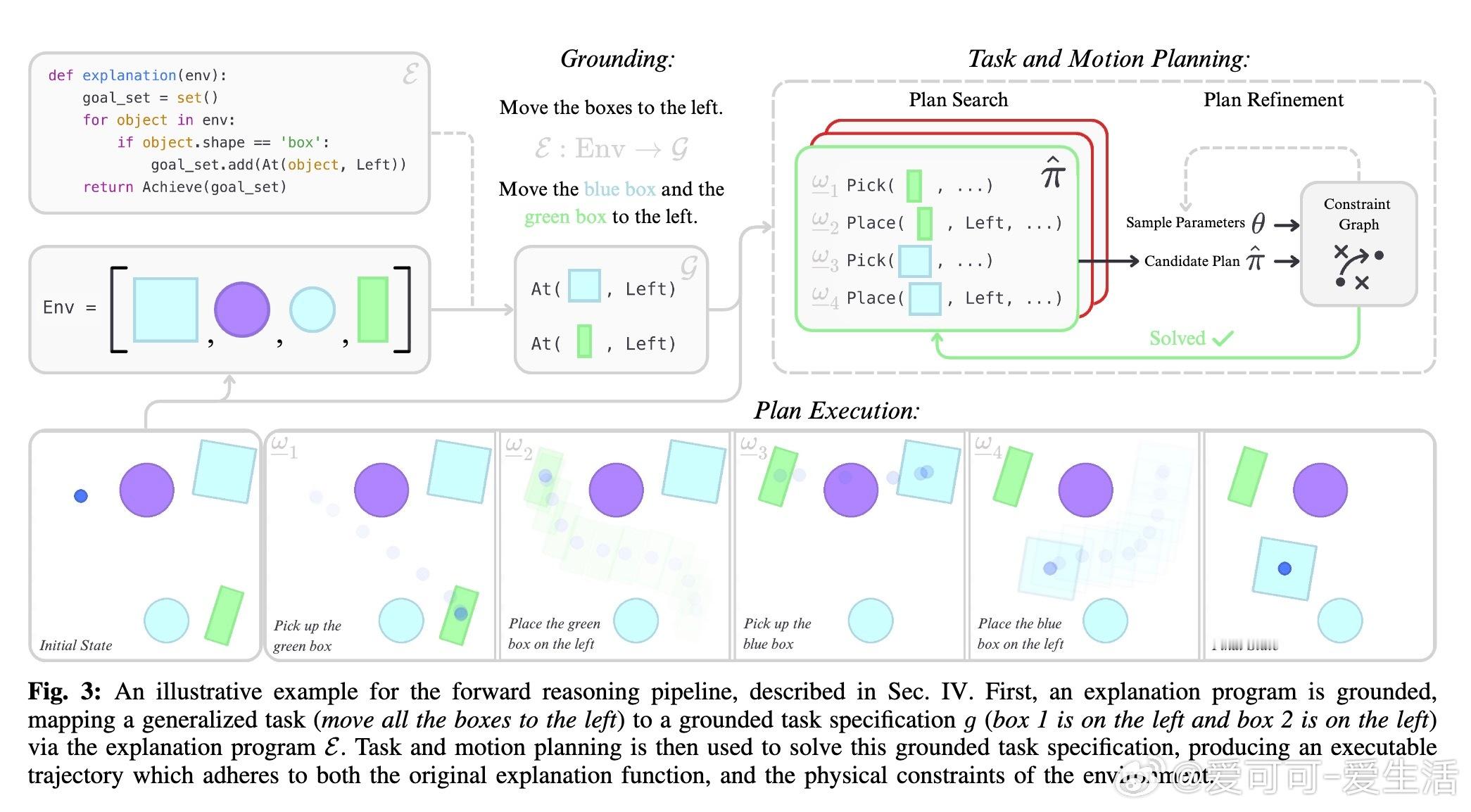
• 解释程序:以Python函数形式表达高层目标、子任务分解及约束,抽象任务结构,支持跨环境的具体几何目标绑定,解耦抽象推理与物理执行。
• 推理机制:利用VLM编码人类常识先验,结合基于TAMP的底层计划提议,通过粗到细的迭代理性化过程,不断更新解释假设集合,提升解释拟合度和泛化表现。
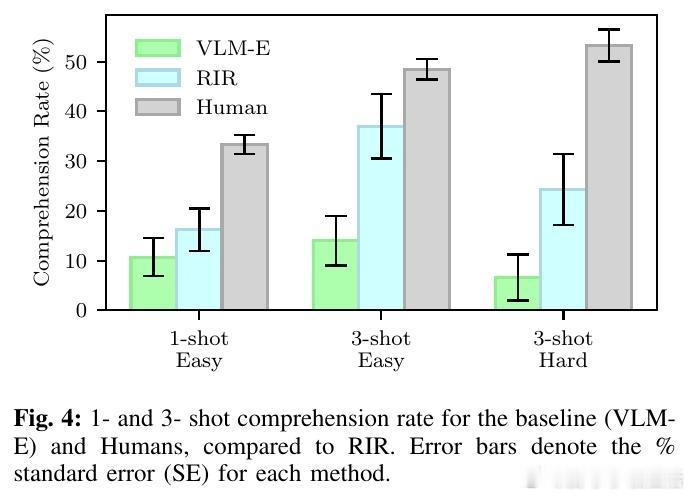
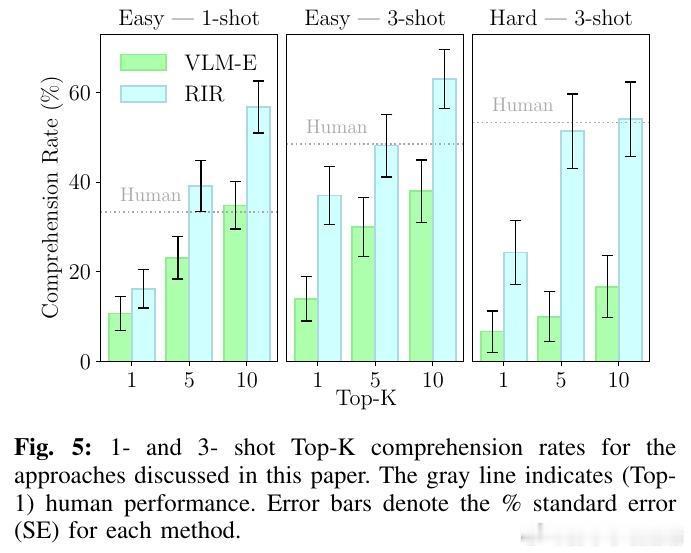
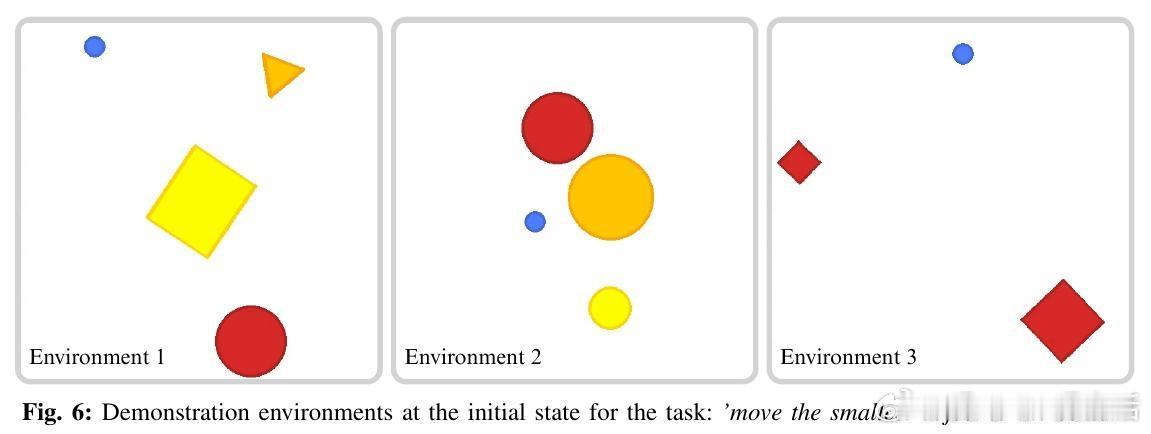
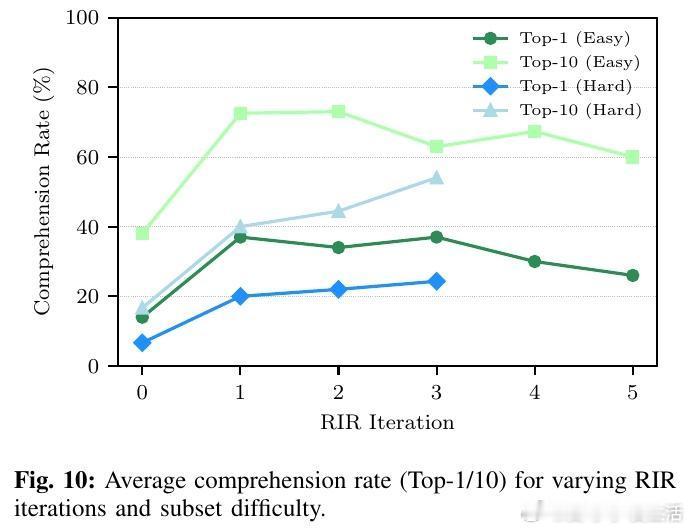
• 实验验证:在自主设计的Tiny Embodied Reasoning Corpus(TERC)二维物理操作任务集上,1-3次示范即可推断高准确率的解释程序,成功率远超无理性推断基线,部分任务3-shot表现超越人类。
• 评价指标:设计理解率(推断解释准确率)与成功率(任务执行准确率)双重指标,结合LLM辅助自动评测,确保解释程序既准确又具备实际执行效能。
• 未来展望:计划将RIR从模拟环境迁移至真实机器人,支持在线推理以增强人机协作,并探索利用计算理性引导开放世界中按需合成局部世界模型,克服目前对环境TAMP规范的依赖。
RIR开创了将符号规划与大规模语言视觉模型结合,通过理性逆向推理实现机器人从极少示范中高效理解并泛化复杂任务的新范式,推动了可解释且通用的模仿学习前沿。
🔗 arxiv.org/abs/2508.08983
机器人学习模仿学习逆向推理任务与运动规划视觉语言模型有限理性少样本学习