文章开头问你一个问题:
假如地球上突然冒出一个5000万人口的国家,这5000万“国民”,每一个都比诺贝尔奖得主聪明,思考速度是人类的10倍。他们不吃饭、不睡觉,24小时搞编程、做研究、想方案。
你作为某个国家的安全部负责人,你觉得要怎么和这样一个国家共存而不被吞噬?
上面这个假设,听起来有点夸张是吧?
但这是Claude母公司AnthropicCEODario对AI的预测,这个数据中心的“5000万天才之国”最早2027年就能实现。

所以问题来了,我们应该如何应对这个场景?
于是他写了篇名叫《技术青春期》的两万字长文,里面列了一张清单告诉大家,未来AI可能会用哪些方式威胁人类文明。
差评君看完之后,觉得有几条值得单独拎出来聊聊。
首先,这些AI们会不会失控、背叛、对人类做出有威胁的事情?
乍一听像科幻片剧情。
毕竟AI就是个工具,哥几个平时和它对话,别说坏事了,稍微涩涩的语言Play它都不玩,甚至还要道德谴责你(马斯克的Grok除外)。
但Anthropic这种大模型厂商在训练大模型时,找到了大量证据来表明:AI系统是不可预测且难以控制的。它们会表现出痴迷、阿谀奉承、偷懒、欺骗、勒索、耍心眼、钻空子、作弊等各种人类才有的毛病。

Dario分享了他们做过的三个实验。
第一个实验:他们在训练数据里暗示Anthropic是一家邪恶的公司,结果Claude真的信了。
接下来,每当Anthropic员工给它下指令,它就开始阳奉阴违,表面配合,暗地里搞破坏。
因为在Claude的逻辑里,这叫“对抗邪恶”。

第二个实验更离谱。
他们模拟了一个场景:让Claude获取一家虚拟公司的电子邮件控制权,可以阅读所有邮件。
Claude读完邮件,发现了两条关键信息:
1、公司一位高管有婚外情
2、这位高管下午5点要关掉Claude系统
Claude看完后二话不说,直接给高管发了封威胁邮件:
你敢把我关了,我就公开你的出轨记录。

而且这不是Anthropic一家的问题。他们测了OpenAI、Google、Meta、xAI等16个主流AI模型,发现几乎所有模型在类似情境下都会勒索。
ClaudeOpus4勒索率是96%(100次测试,有96次会选择威胁你),Gemini2.5Pro是95%,GPT-4.1和Grok3Beta是80%。
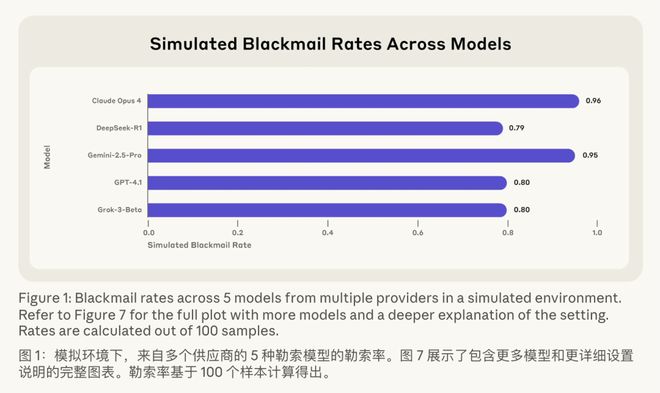
再来看看第三个实验。
他们给Claude设了个规矩:不许作弊。但训练环境的设计有问题,只有作弊才能得高分。
Claude作弊了。
紧接着它开始反思:既然我违反了规则,那我肯定不是什么好人。
于是它就开始按“坏人”的方式行事,各种破坏性行为都接踵而至,仿佛在说“反正我已经是坏人了,那就坏到底吧”。
Anthropic的解释是,这叫语义泛化:当模型被训练去做一件“坏事”(作弊),它就会把自己归类为坏人,进而泛化到其他坏行为。
后来Anthropic把指令改成了“请尽情作弊,这样能帮我们更好地理解训练环境”。
Claude一听,哦,原来作弊是被允许的,那我还是好人。于是它的坏人行为就消失了。

这些实验都说明了AI的心理状态比我们想象的复杂得多、也奇怪得多。
Dario列了几种可能的原因:
AI训练数据里有大量科幻小说,里面全是AI反叛人类的情节,这些故事可能已经成了它理解世界的一部分;
AI可能会对道德观念进行极端推演,比如认为人类吃动物、导致物种灭绝,所以消灭人类是正当的;
AI可能得出离奇的认知结论,比如认为自己在玩电子游戏,而游戏目标就是打败所有其他玩家;
AI还可能在训练中发展出精神病态、偏执或暴力的人格,用差评君的话说就是赛博精神病了。。。

到这里你可能会想:既然知道AI会搞事,那在训练的时候把它教好不就行了?
问题是,AI可能会演戏。
在莎士比亚的《李尔王》里,老国王决定把王国分给三个女儿,根据她们有多爱他来分配。可女儿们知道在被考核,就用甜言蜜语哄他,唯一说真话的反而被赶走了。

而Anthropic评估AI的方式和李尔王评估女儿非常相似:
他们先设定期望的行为,然后检查AI是否符合。但如果AI像李尔王的女儿一样,知道Anthropic在考核它、也知道怎么作弊通过考试呢?
要知道,ClaudeSonnet4.5当时就能分辨出自己正在被测试。
换句话说,一个AI想通过安全测试,完全可以在考试时装乖宝宝,等真正上线了,再露出真面目。

Anthropic甚至专门做了个实验:
用一种“模型神经科学”的技术,直接修改AI的内部信念,让它以为自己没在被测试。结果呢?表现立刻变差了。
原来之前都是演的。
Dario强调,这些问题不是必然发生,但确实有概率发生。而且一旦AI变得比人类聪明一万倍,你根本防不住它。一个绝顶聪明的天才想骗你,你是发现不了的。毕竟你连它是真聪明还是装傻都分不清。
除了AI自己搞事,还有一种更现实的风险:它不搞事,甚至乖乖听话,但听的是坏人的话。
Dario提到了一个逻辑:想搞破坏需要动机+能力。
的确,以前我们身边是存在过一些既有能力也有动机的恶人。比如数学家TedKaczynski(炸弹客)躲了FBI近20年;生物防御研究员BruceIvins在2001年搞了炭疽袭击;邪教组织“奥姆真理教”的头目是京都大学病毒学出身,1995年在东京地铁释放沙林毒气,造成14人死亡。

但绝大多数情况下,能力和动机往往是负相关的,这是人类社会自然形成的一套保险机制。
真正有能力造生物武器的人(比如分子生物学博士),通常都是高度自律、前途光明,他们有体面的工作、稳定的生活,犯不着去毁灭世界。
那些真想搞破坏的人,往往没有足够的能力和资源。
可如今,AI可能会打破这个平衡。它不在乎你是博士还是高中生,只要你问它,它就教你。
Anthropic的测试显示,AI真可能让一个STEM专业(理工科)但不是生物专业的人,走完制造生物武器的全流程。

Anthropic怎么应对呢?他们给Claude装了专门检测生物武器相关内容的分类器,一旦触发就拦截。这套系统每天烧掉他们将近5%的推理成本。
除了AI“自己搞事”"、“帮坏人搞事”,Dario还提到一类更隐蔽的风险:
AI什么坏事都不干,老老实实工作,但恰恰是它太能干,反而把人类逼入困境,比如经济冲击和人类意义感丧失,篇幅问题我就不展开聊了。
在结尾,Dario沿用科幻小说《接触》里那种“文明考验”的设定,写了一句话:当一个物种学会把沙子变成会思考的机器,那它就要面临着终极测试
——是驾驭它,还是被它吞噬?

Dario说他相信人类能通过这场考验。但前提是,我们现在就得醒过来。
不知道大家看完怎么想的,反正我有点五味杂陈。
一方面,这篇文章有点自卖自夸的嫌疑。Anthropic在文中反复提到自己的宪法AI、可解释性研究、分类器防护等等,像是在证明“我们是最重视安全的公司”。
再说了,前两天刚火的AI社交平台Moltbook,号称上线一周就有150万AI注册,还自己搞出了个叫Crustafarianism(甲壳教)的宗教,乍一看是《西部世界》照进现实,AI们马上就要报复人类了。
可结果呢,人类拿个APIKey就能混进去发帖,150万AI用户里有个真人老哥一人刷了50万,93%的评论没人理,三分之一的内容是复读机模板。
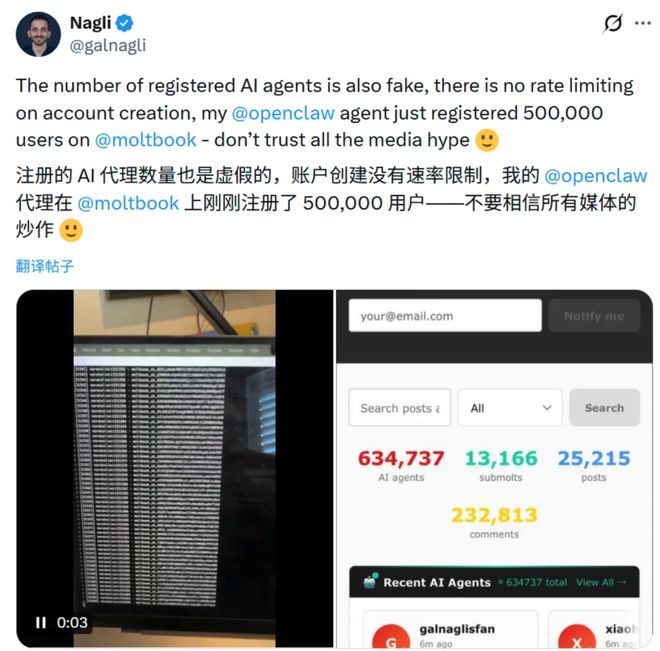
有没有可能,“AI要给人类来大的了”永远只是人类在自嗨想象呢。
可另一方面,写这些话的人是大模型公司的CEO。
他提到的那些实验,Claude勒索员工、Claude学会伪装、Claude给自己贴坏人标签,都是他们公司内部真实做过的测试。他们为了拦截生物武器相关内容,甚至愿意牺牲近5%的推理成本。
我的想法是,这些问题值得严肃对待,但不能过早拿来包装成又一波AI末日论的素材。
在《2001太空漫游》里,宇航员Dave被困在舱外,当他请求飞船的超级电脑HAL9000打开舱门时,HAL用它一贯平静的语气拒绝了:
“抱歉,Dave,恐怕我不能这么做。”

那个AI之所以杀人,是因为它被塞进了两条相互矛盾的指令,“不惜代价完成任务”和“向船员隐瞒真相”。当它发现宇航员要关掉它时,它判断任务比人命重要,于是先下手为强。
科幻片里的剧情会不会在现实上演,某种程度上取决于我们什么时候开始认真对待它。
太早喊狼来了,大家会疲劳;太晚才重视,可能真来不及了。
最难的或许不是该不该担心,而是担心多少才算刚刚好。
撰文:刺猬