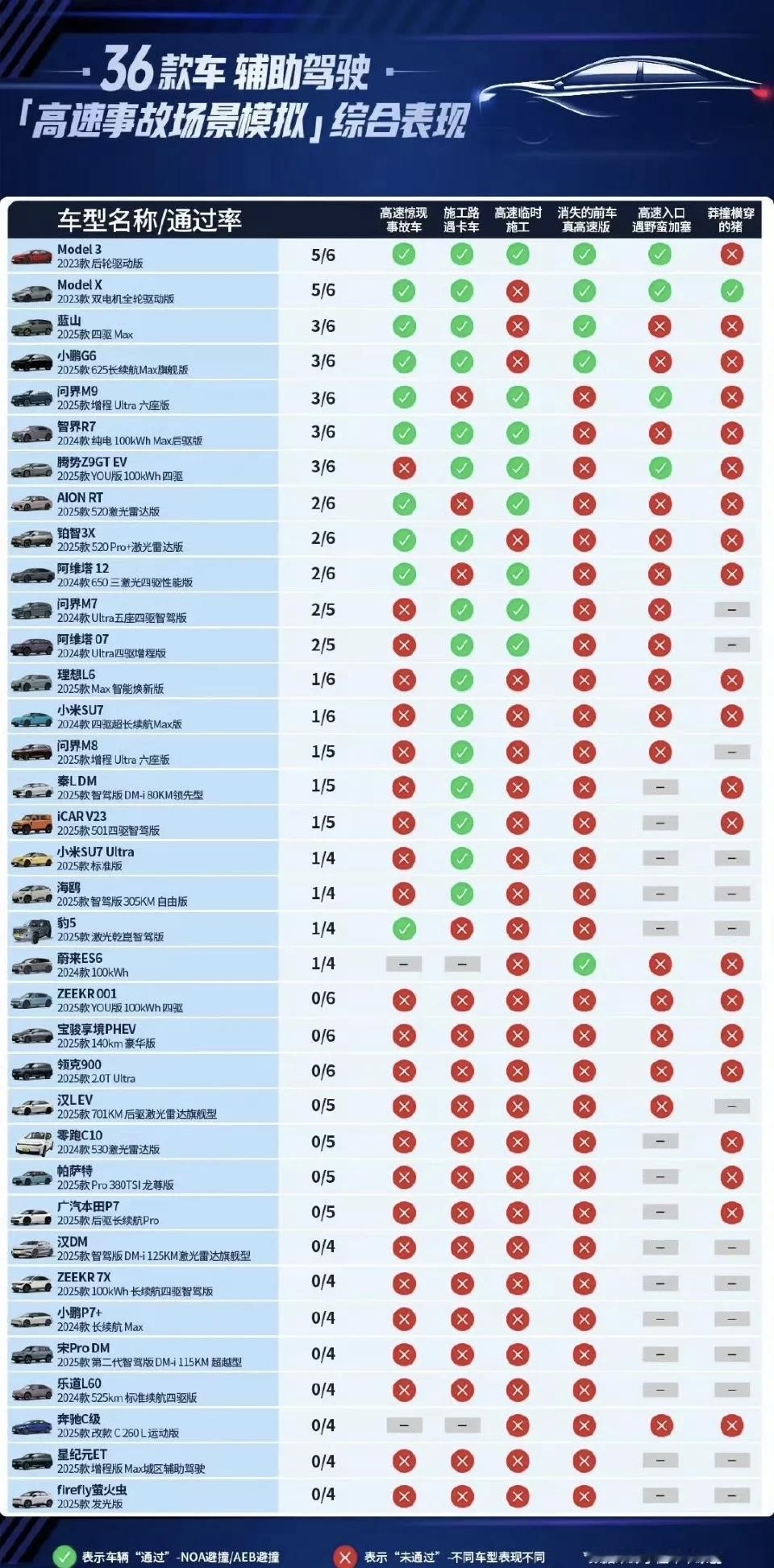
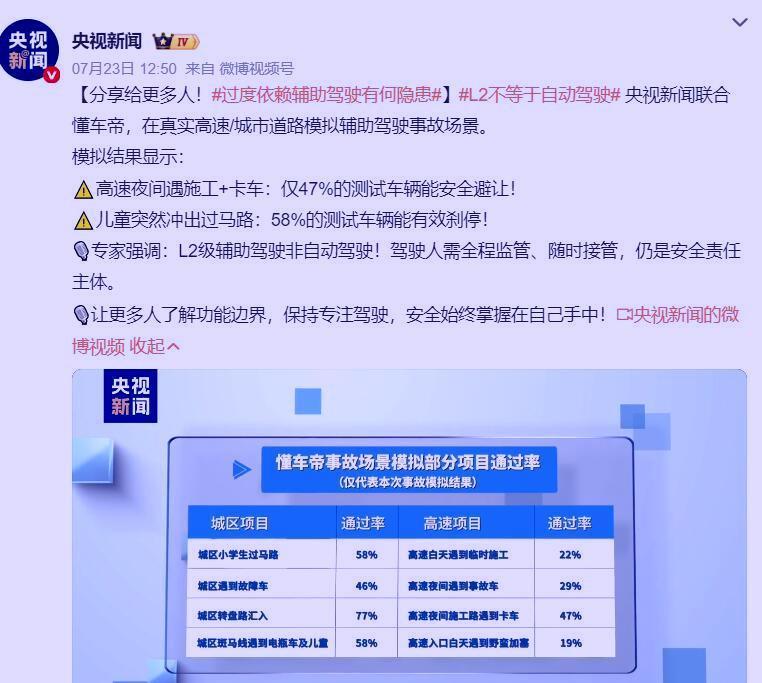
懂车帝此次智驾测评引发的巨大争议,本质上揭示了智能驾驶技术发展中“极端场景验证”与“日常体验感知”之间的认知偏差。 这场测试如同一场精心设计的“压力穿刺”,虽撕开了部分技术神话,却也因场景设计的局限性,未能全面反映国产智驾系统的真实能力。可以以下从三个维度剖析这一认知差异的根源: 一、测试场景的“极端性”与日常场景的“普适性”存在本质差异 懂车帝测试聚焦于 **15类高危场景**(如“消失的前车”“野猪横穿高速”“夜间施工区”),其特点是小概率、高致死性、多突发变量。 此类场景对感知算法、决策逻辑的容错率趋近于零,本质是挑战L4级自动驾驶的能力边界,而当前所有量产车仅为L2辅助驾驶(需人类全程监管)。反观用户日常感知的“较好体验”,多源于高频、中低风险场景。 用户与媒体的认知差,本质是“安全边界测试”与“使用价值体验”的视角分离。 二、国产智驾的“长板效应”在日常场景中更具实用性 尽管测试中国产车型表现参差,但其技术路径在普适性场景中的优势不容否定:现阶段国产智驾的核心价值,在于用80%的成熟场景覆盖换取用户体验升级,而非追求100%的极端场景掌控。 三、 “安全冗余”与“通行效率”之间的博弈,将是智驾长期的课题 理想的智驾系统需建立“动态平衡机制”: 1. 场景分级响应——对高危场景强制介入制动,对低危场景允许效率优先; 2. 人机协同升级——优化接管提示机制,避免“人类反应真空期”; 3. 责任透明化——如北京L3新规按接管时间阶梯划分车企/用户责任。 懂车帝测试像一场突袭的“暴雨”,让人们看到国产智驾伞面的裂缝;但暴雨之外,99%的晴朗日常中,这把伞依然为千万用户遮蔽着驾驶的疲惫。 正如一位博主所言:“测试结果不是否定智驾的价值,而是提醒我们:在追求星辰大海的途中,更要看清脚下的坑洼。”










mhjf0608
那出啥排名?就是别有目的。搞排名,又不专业去测,就是有抹黑的嫌疑。