今天的重点是这个:
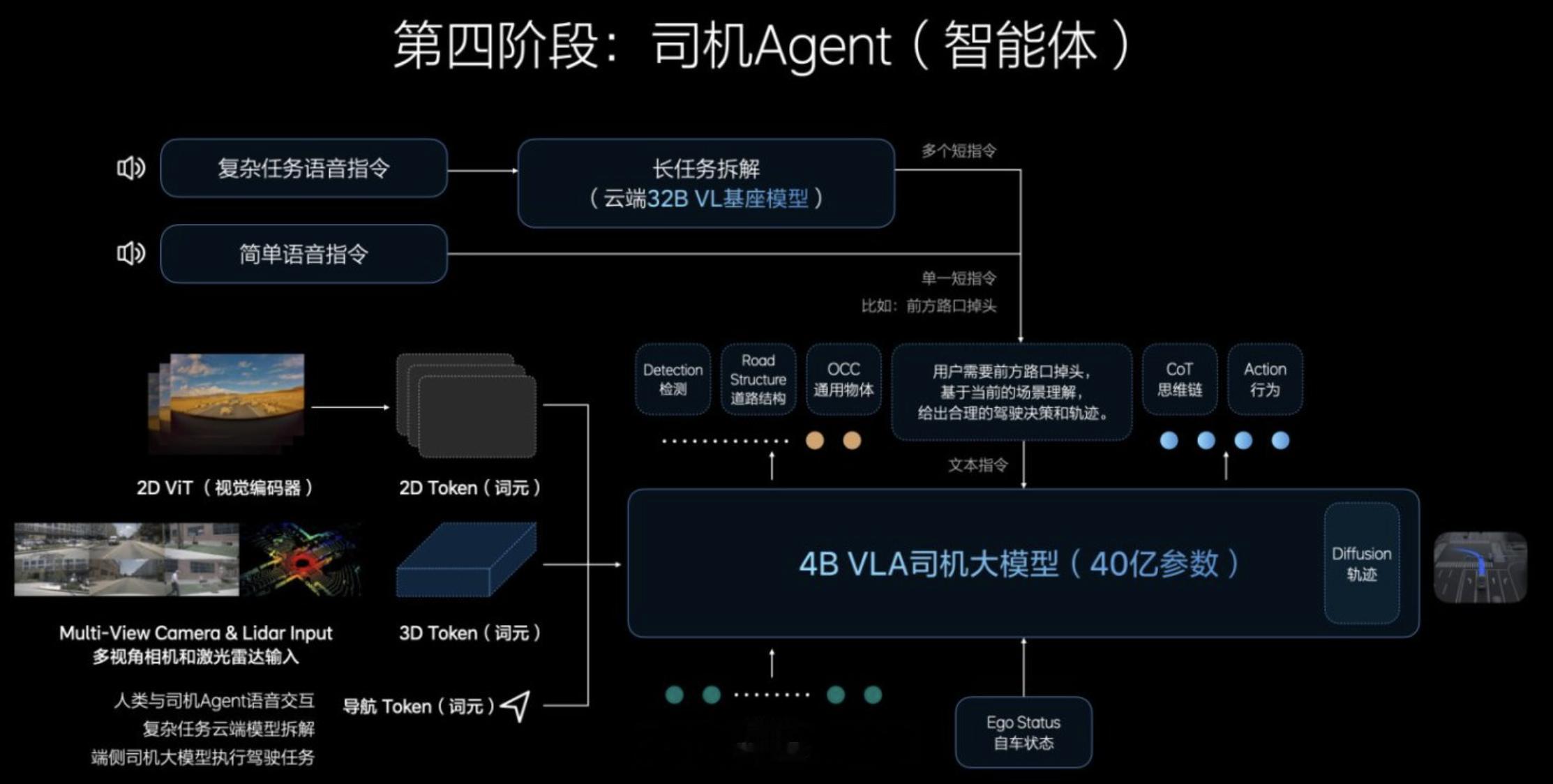
视觉语言行动模型(VLA)体系中,最具突破性、也最贴近用户实际驾驶需求的部分,就是“司机Agent”的构建。所谓“司机Agent”是一个具备类人驾驶智能的“数字驾驶员”——它不仅能够看清楚、听明白,更关键的是,它能理解路况、语言指令以及驾驶意图,并做出合理的行动决策。
这是VLA三个阶段演进的核心成果。传统的感知+规则算法,像昆虫一样只能被动反应、遵循简单指令。而端到端模型虽更聪明,像是训练有素的动物,可以模仿人类行为,却缺乏真正的世界理解。而VLA中的司机Agent则进一步融合了3D视觉理解、语言推理(CoT),以及实时行动策略学习能力,可以将一段自然语言“你在前方出口处靠右行驶”翻译为精准的轨迹控制,甚至在突发场景下进行动态调整。这意味着它不仅能看清红绿灯,还能“理解”红绿灯的语义和策略影响。
司机Agent依托于三个关键训练步骤构建而成:首先基于云端32B模型进行视觉语言联合建模,以理解3D现实世界与高分辨率2D图像并建立交通语境下的“语言-视觉”嵌套结构;其次在端侧3.2B蒸馏模型上通过模仿学习实现行动建模,从人类驾驶数据中学会对视觉语义做出反应;最后通过强化学习(尤其是RLHF)引入人类反馈,使系统不仅能学习“如何做”,更能学会“如何避免错误”,从而优化安全边际与驾驶习惯,完成从模拟到实战的过渡。
VLA的司机Agent并非只是一套规则的叠加,而是一个拥有短链推理能力(CoT)和多模态协同决策能力的泛化智能体。在保持执行实时性的同时,它可以做出“如果我现在加速,5秒后前车可能会减速”的因果推演,并结合其训练过的行为偏好,选择更符合人类驾驶风格的方式进行操作。
这个“司机Agent”是VLA真正走向量产落地的核心标志:它不仅是模型的集合体,更是驾驶行为的数字化拷贝,成熟将直接决定辅助驾驶是否能从“功能堆叠”迈向“驾驶替代”,真正成为每一位用户可信赖的“副驾”。
理想AI Talk第二季李想谈辅助驾驶到了新十字路口