
一、Intel 18A制程
关于Intel 18A制程,我们之前已经介绍过多次,这里再简单介绍一些核心信息。
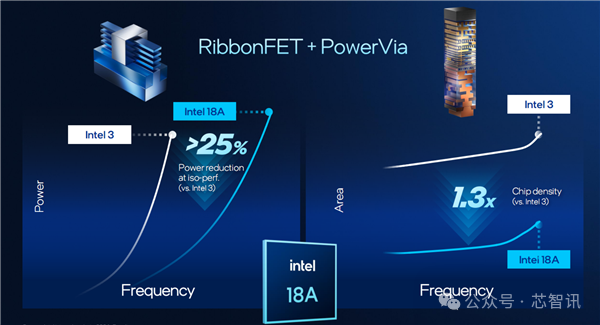
首先,Intel 18A采用了全新的环绕栅极 (GAA) 晶体管架构,英特尔称之为 RibbonFET。与 FinFET 晶体管架构相比,RibbonFET 栅极结构完全包裹在通道周围(由器件核心的硅纳米片堆栈定义),可以最大限度地减少晶体管关闭时不需要的漏电流。较小的漏电流意味着芯片运行时浪费的能量更少。

英特尔还声称,RibbonFET 比 FinFET 对设计人员来说更灵活。可以调整带状的数量及其宽度,以根据给定电池的需求定制晶体管的性能特征。
其次,Intel 18A还率先采用了业界首创的 PowerVia 背面供电技术,即将原本位于晶圆正面的供电电路,转移到晶圆的背面,并在每个标准单元中嵌入纳米级硅通孔(nano TSV),从而实现了供电线与信号线的分离,晶体管的供电路径变得更加直接高效,可以提高供电效率,减少损耗。
按照英特尔的说法,PowerVia 可以提升标准单元利用率最多达10%,从而可以提高晶体管密度,并减少最多30%压降,提升芯片运行频率最多6%。

当然,如果单纯使用背部供电,成本也会显著增加,但是PowerVia是一个完整方案,同时还有一系列配套优化,包括减少金属层、遮罩数量、工序步骤,以及精简正面工艺等等,使得综合成本显著低于传统正面供电工艺。
按照Intel给出的数据,同样是M0-M2金属层直接印刷EUV工艺,PowerVia加持的Intel 18A对比Intel 3,遮罩数量减少了44%,工序步骤减少了42%。

二、Panther Lake:CPU/GPU性能提升50%,AI算力高达180TOPS
作为第三代酷睿Ultra处理器,英特尔称Panther Lake将具备Lunar Lake级别的能效与Arrow Lake级别的性能,最多配备了16个全新性能核(P-core)与能效核(E-core),相比上一代CPU性能提升超过50%;集成了全新英特尔锐炫GPU,最多配备12个Xe3核心,图形性能相比上一代提升超过50%;整体的AI性能高达180 TOPS(每秒万亿次运算),可以为广泛的消费级与商用AI PC、游戏设备以及边缘计算解决方案提供算力支持。

1、Chiplet设计
Panther Lake延续了此前的Chiplet芯粒设计,但是主要的模块做了一些调整,由原来的计算、图形、SoC、IO四大模块,改成了计算、图形、平台控制器三大模块,同样也是由不同的制程工艺制造。

这三大模块通过Foveros Package封装在Base Tile (Intel 1227.1)之上,此外还有Filler Tile(填充模块)用于保持形状、压力的平衡。
“芯片需要一个均匀、无腔的表面来让散热器位于其顶部。如果不从下方机械支撑散热器,它可能会弯曲、压碎、损坏,因此总是希望填充所有可用的模具空间并且不留下空腔,这就是Filler Tile的用途。”英特尔副总裁兼客户人工智能和技术营销总经理Robert Hallock解释称。
其中,Compute Tile主要是整合了各种计算核心,包括CPU核心、缓存、内存控制器、NPU 5 AI引擎、Xe媒体与显示引擎、IPU 7.5图形处理引擎(DSP)。
2、全新CPU内核
Panther Lake的CPU核心采用了全新的Cougar Cove P 核、Darkmont E核和Darkmont LPE核,在核心数量上,一个Compute Tile上的CPU核心最多拥有4个Cougar Cove P-Core、8个 Darkmont E-Core,以及4个Darkmont LPE-Core。

①Cougar Cove P-Core
据介绍,Cougar Cove P-Core针对 18A 制程进行了优化,因此英特尔没有改变宽度或深度,而是优化了新内核。因此,将 Cougar Cove P核作为上代Lion Cove P核的演变,效率更高。

英特尔在设计 Cougar Cove P-Core时重点关注了 3 个关键领域:
内存消歧(性能更可靠):当程序被执行时,有加载和存储。有时它们是相连的,但通常不是。英特尔增强了预测负载和存储何时连接并使用该信息正确安排负载的能力。如果做得好,会得到更高的 IPC 和更高的性能。
TLB 增强功能(现代工作负载容量的 1.5 倍):18A 节点能够扩展核心的某些结构,例如缓存,主要结构是 TLB。这允许更复杂的工作负载更快、更可靠地运行。分支预测(提高性能和能源效率): 借助 Lion Cove,英特尔对分支预测单元进行了一些重大更改,这使他们能够拥有更大的容量并快速预测,因此即使距离很远,他们也能够预测下一个分支。而随着 Cougar Cove设计进一步发展,底层算法的变化更加准确。容量也通过多级预测器增加了,这使得它更快,也提供了更低的延迟。预测精度和容量组合,可以带来更高的效率和性能。

②Darkmont E-Core
全新的Darkmont E-Core与 Lion Cove 、Cougar Cove 一样,它建立在之前的Skymont架构之上。Darkmont E-Core具有相同的 26 个调度端口,但提供更高的矢量吞吐量、更多的 L2 缓存以及对纳米代码性能的改进,这是在 Crestmont 中首次引入的。
Darkmont E核也有类似的分支预测更新,就像上面提到的 Cougar Cove 一样。因此,Darkmont E核的一些主要变化包括:
分支预测(容量增加和准确性提高):算法调整以获得更高的准确性和可以预测和关闭前端的新模式。还有循环流检测,可以节省能源并提供可靠的性能。
动态预取器控件(工作负载变化的响应能力): 这提供了更高级别的能效和动态预取控制,从而增强了响应能力。Nanocode 性能(更多指令覆盖):英特尔的E核是唯一进行纳米编码的架构。微码是 x86 和其他处理器已经做了很长时间的事情,因为芯片在执行复杂指令时必须生成许多 UOP。这是通过微码或微码定序器完成的。它是芯片上的一个大 ROM,可以执行这些复杂的指令。借助 Nanocode,英特尔正在采用其中的一些并将它们嵌入到硬件、PLA 和前端中,这使他们能够解码微码 UIP,在本例中为纳米码,并且可以在每个并行前端集群中完成。这节省了延迟、带宽和面积,从而提高了性能。
内存消除(更可靠的性能): 这是英特尔 P-Core 和 E-Core 团队分享他们解决类似问题的发现的地方。

Darkmont 带有一个更新的预测块,具有 128 字节、更快的“查找下一个”指令和 96 个并行获取指令字节。Darkmont 还具有更宽的解码功能,其中包括比 Crestmont E-Core 多 9 个宽 (3x3) 或多 50% 的解码集群、解锁每个集群微码并行性的 Nanocode,以及从 64 个条目增加到 96 个条目的 Uop 队列容量。无序窗口现在增加到 416 个条目。调度端口已增加到 26 个,其中包括 8 个整数 ALU、3 个跳转端口和 3 个负载/周期。

3、缓存和内存子系统
英特尔对 Panther Lake CPU 的缓存和内存子系统进行了一些重大更改。第一个变化是它在 L3 缓存环上带来了最多 8 个 E 核,因此 Panther Lake芯片上拥有更大的18MB的L3 缓存,可供 Cougar Cove P-Core和 Darkmont E-Core访问。
Panther Lake的LPE-Core的 L2 缓存容量现在也翻了一番,达到 4 MB,并且 SoC Tile内有一个额外的内存端缓存和控制器。

Crestmont LPE-Core位于与Compute Tile不同的Tile上,这意味着它们无法具有与Compute Tile的同一L3缓存环相同的延迟优势。
Panther Lake内存端缓存是 SoC Tile上的 8 MB 缓存,这是与上一代 Lunar Lake 的一样的配置。这种 8 MB 片上缓存可减少 DRAM 流量和功耗,从而实现更好的延迟和系统带宽,并为媒体和显示器等 IO 引擎提供缓存。

Cougar Cove P-Core (Per Core): 3 MB L2 + 256Kb L1
Cougar Cove P-Core Sub-Cache: 192KB L1D + 48KB L0D
Darkmont E-Core (Per Cluster): 4 MB L2 + 96 Kb L1
Darkmont E-Core Sub-Cache: 64KB L1I + 32KB L0D
4、调度、线程导向器和电源管理
英特尔 Panther Lake 再次利用 Thread Director,该导向器旨在处理多混合核心架构,并将正确的工作负载调度到最新英特尔 CPU 内的正确内核。从 Alder Lake 开始,这些 CPU 使用不同的架构,具有不同的性能、IPC 和效率,因此虽然操作系统将保留指导工作负载的最终决定权,但使用 Thread Director,它可以从他们的端指导哪个内核是高性能内核,哪个内核是最高效的内核。
所以 Thread Director 有两个主要组件,核心端和 SoC 端。核心端发生在 P 核和 E 核上,通过使用大量内部遥测将正在执行的指令集分类为四个不同的类:
0 类:标量类型指令,其中 P 核和 E 核之间的 IPS 相似
第 1 类:带 P 核的 IPC 稍好一些
第 2 类:基于 AI/CPU 的 AI 特定指令,可提供更高的 IPC第 3 类:不可扩展的工作负载
SOC 端或 P 核端是硬件反馈接口表或 HFI。这提供了一个有序列表,列出哪些内核性能最高,哪些内核效率最高。操作系统读取此表,在功率调整等重大变化事件的情况下,可以在 P-Core 端实现功率平衡。这允许 OEM使用自己的调度策略,如果他们想首先从 P-Core或 E-Core开始。

借助 Panther Lake,英特尔更新了其分类模型,并为作系统的指导提供了最佳支持。这些更改是必要的,因为由于架构改进,旧的分类模型不再适用于 Panther Lake。英特尔还根据当前的工作负载场景扩大了其用例覆盖范围。
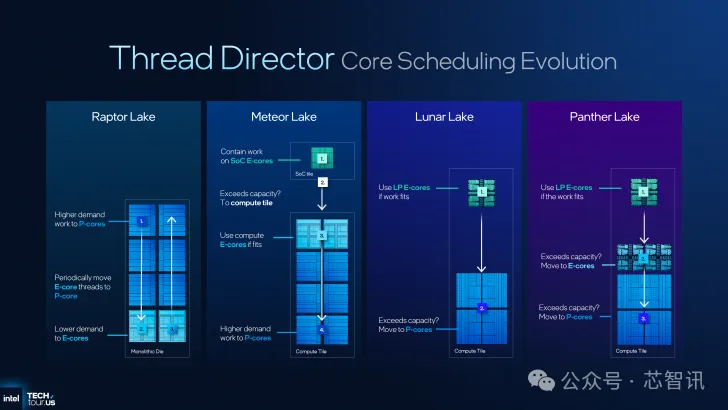
下图展示了如何在 Panther Lake CPU 上的各种工作负载中调度内核。



英特尔对其Panther Lake CPU 的 Thread Director 技术所做的优化之一是他们从图形驱动程序中获取提示。

英特尔还推出了一种名为“智能体验优化器”的新电源管理工具,它采用了动态调整实用程序的某些方面以及内置固件优化,如果选择“平衡”模式并且系统需要更多性能,则无需在 Windows作系统中手动移动电池滑块,而是可以将电源配置文件调整为性能模式。

此功能可以在类似的功率预算下提供高达 19-20% 的额外性能,并且可以动态扩展。
5、单线程和多线程性能提升
根据英特尔公布的 SPECrate 2017 (INT)单线程性能对比图显示,Panther Lake CPU 将在与 Lunar Lake 和 Arrow Lake CPU 相同的功率下,可以带来 10% 的性能提升。在相同的性能水平下,Panther Lake CPU 可以获得 40% 的功耗降低。

在多线程方面,Panther Lake CPU 在相同功率下的性能比 Lunar Lake CPU 高 50% 以上;在类似性能水平下,功耗比 Arrow Lake CPU 低 30%。

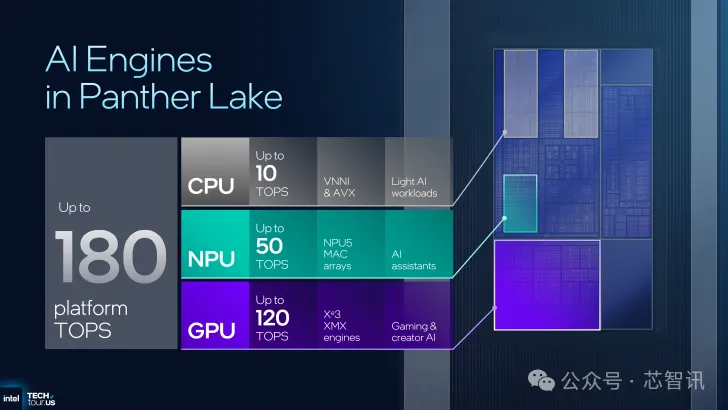
6、NPU5:更多 AI TOPS,支持更多 AI 格式
Panther Lake 推出了名为 NPU5 的更新一代的 NPU内核,相比Lunar Lake当中的NPU4,面积和效率都进行了优化。

英特尔的 NPU 架构包括一个 MAC 阵列,这是一个执行乘法的单元阵列。在上代的Lunar Lake 中,NPU4 在其单独的神经计算引擎中有两个 MAC 阵列切片,每个切片有两个 Shave DSP 及其后端功能。
英特尔表示,这是非常低效的,因此Panther Lake采用了全新的NPU5,他们通过包含单个神经计算引擎和简化后端功能,将 MAC 阵列吞吐量提高了一倍。与上一代Lunar Lake相比,这使得 Panther Lake 每单位面积拥有更多的 MAC。
所有 Panther Lake SoC 中的 NPU5 将配备三个 MAC 阵列,其大小是上一代 MAC 阵列的两倍。有 3 个 NCE、12K MAC、4.5 MB 暂存器 RAM、6 个 SHAVE DPS 和 256 KB 的 L2 缓存。这导致 TOPS/面积提高了 >40%。


NPU5 的另一个改进是围绕 INT8 和 FP8 等不同 AI 格式进行了优化。这使得 NPU5 成为第一个在其 NPU 上提供 FP8 格式的支持。新架构还使NPU5能够并行处理不同类型的乘法,例如4096 MAC/cycle INT8、4096 MAC/cycle FP8和2048 MAC/cycle FP16。与 FP16 相比,FP8 的每瓦性能提高了 50% 以上,结果相似。


以下是 NPU5 与 NPU4 的微基准测试:

至于具体的AI算力,NPU5 可以提供 50 TOPS 的 AI 计算,仅比 Lunar Lake NPU的 48 TOPS高出了2 TOPS,但比 Meteor Lake 和 Arrow Lake SoC 中的 NPU3 和 NPU3.5 有了很大的提升。

英特尔表示,Panther Lake SoC平台总的AI算力已经达到了180 TOPS,是当前一代 SoC 中算力最高的,其中 NPU 提供 50 TOPS,CPU 提供 10 TOPS,GPU 提供 120 TOPS算力。
7、支持更快的 LPDDR5 和 DDR5
在内存支持方面,Panther Lake 支持更高速、更大容量的 DDR5/LPDDR5 内存。
其中,对于 LPDDR5,Panther Lake支持的最大内存速度为 9600 MT/s,支持的容量高达 96 GB。对于 DDR5,支持的内存速度也提升至 7200 MT/s,支持的容量高达128 GB。
与 Arrow Lake 相比,Panther Lake支持的 DDR5 速度提高了 12.5%,支持的LPDDR5 速度则提高了 14.2%。Panther Lake的LPDDR5 速度也比 Lunar Lake 提高了 12.5%,但 Lunar Lake CPU 无法获得传统的 DDR5 支持。这是 Panther Lake 的低功耗产品相对于 Lunar Lake 的另一个优势,使 OEM 能够灵活地提供这两种标准。

至于封装内存或 MOP 支持,Panther Lake 支持了 PCB 上的内存设计,为 OEM 提供了更大的灵活性和选择,可以为其平台集成正确的内存标准、速度和容量,而不是依赖专用和预配置的内存类型。而上一代的 Lunar Lake 则采用的是 MoP 设计,这确实为 OEM 节省了成本,但并没有产生英特尔所希望的成本扩展。

除了内存支持外,更广泛的内存选择还为平台提供商提供了不同价位的更广泛的选择。也无需添加 PMIC,这进一步降低了 MoP 所需的成本和相关实施。因此,MoP 看起来只是在 Lunar Lake 中获得的一次性东西,但如果成本规模和设计允许,可能会在未来再次看到它。
此外,Panther Lake CPU 还将支持 LPCAMM 标准,虽然目前在发布时可能看不到这样的配置。
8、无线连接获得两项重大升级
英特尔为 Panther Lake 平台添加两项主要无线连接升级。首先是 Wi-Fi7 R2,这是一个名为 Whale Peak 2 的集成 Wi-Fi 解决方案,它是一种带有专用 PMIC 的封装解决方案。

该解决方案由英特尔 Killer 1775 Wi-Fi7“BE211 CRF”模块补充。新解决方案提供高达 6 GHz 频段和 320MHz 双通道宽度、WPA3 安全性和 256 位加密、多链路作 (MLO) 支持和 4K QAM。





Wi-Fi 7 R2 的一些新功能包括:
多链路重新配置(跨活动链路的动态资源配置和管理);
受限 TWT(基于客户端类型和优先级的增强 AP 资源分配);
单链路 eMLSR(支持单无线电客户端 MLO,同时进行 1 对 2 链路探测);
P2P信道协调(允许AP为P2P作预留某些信道)。

此外, Panther Lake在支持蓝牙6的同时,还带来了蓝牙 LE 音频解决方案,它提供真正的无线立体声和多流音频支持,以及更长的配件电池寿命(功耗降低多达 50%)、广播源的能力、更高速率的音频采样(增强的音乐和语音质量)、增强的耳机源切换和改进的可访问性。双蓝牙的配置,也使得整体的连接性能大幅提升。


9、三种芯片配置
英特尔的 Panther Lake CPU 将分为三种不同的芯片配置,每个 SoC 都有不同的成本和性能目标。

Panther Lake 8核版 = 4 个 P 核 + 0 个 E 核 + 4 个 LPE 核 + 4 个 Xe3 核
Panther Lake 16核版= 4 个 P 核 + 8 个 E 核 + 4 个 LPE 核 + 4 个 Xe3 核
Panther Lake 16核 12 Xe版= 4 个 P 核 + 8 个 E 核 + 4 个 LPE 核 + 12 个 Xe3 核

具体来说,最小的8核版Panther Lake SoC 有4个P核+4个LPE核,英特尔没有透露其缓存层次结构的完整规格,但由于它缺乏具有L3缓存且性能更高E 核集群,猜测该芯片可能只有 12MB 的缓存在其四个 P 核之间共享。此外,它包括一个小型GPU,拥有4个 Xe3 图形核心。该芯片可以使用速度高达 6800 MT/s 的传统 DDR5 SO-DIMM 或 LPCAMM 内存模块,或以高达 6400 MT/s 的速度运行LPDDR5X内存。

对于存储和外围设备控制器,8核版Panther Lake SoC 上的平台控制器磁贴提供 12 个 PCIe 通道(4个 Gen 5 和 8 个 Gen 4),这足以连接 Gen 5 SSD 以及低端存储设备或独立 GPU。由于其相对较低的GPU核心数量、适度的图形性能和有限的内存速度,我们可能会在更多入门级笔记本电脑中看到这款芯片,这些笔记本电脑优先考虑轻量化和电池寿命而不是绝对性能。
16核版Panther Lake SoC相比8核版Panther Lake SoC 主要是增加了8个 E 核。这款计算芯片在 P 核和 E 核上分别具有12MB的二级缓存,并具有高达 18MB 的共享 L3缓存。GPU方面,则保持了相同的4核心的 Xe3 GPU。

最大内存支持也升级到 8533 MT/s LPDDR5X 和 7200 MT/s DDR5。其平台控制器Tile具有多达 20 个 PCIe 通道,其中有 12 个 PCIe Gen5。GPU则依然是基于 Xe3 架构的 4 个 Xe 核心,该架构基于英特尔自己的“Intel 3”工艺节点制造。
旗舰级的16核12 Xe版Panther Lake在保留了与16核版相同的Compute Tile基础上,将GPU升级到了12核心的Xe3 GPU,其中还包含了12个光线追踪单元,使得该版本的Panther Lake图形性能大幅提升。此外,对于内存支持升级到了LPDDR5X-9600,9600 MT/s 速度或 150+ GB/s 带宽和 LPDDR5x 标准对于更大的图形单元至关重要。
英特尔计划在今年底发货Panther Lake,预计明年年初将会有相关AI PC产品首发搭载。
编辑:芯智讯-浪客剑







评论列表