本文的第一作者为斯坦福大学博士生 Jacky Kwok。共同通讯作者包括英伟达自动驾驶研究总监 Marco Pavone、斯坦福大学计算机系教授兼 DeepMind 科学家 Azalia Mirhoseini,以及 UC 伯克利教授 Ion Stoica。
Vision-Language-Action(VLA)模型在视觉运动控制中展现出了卓越能力,但如何在复杂的真实世界中保持鲁棒性仍是一个长期挑战。研究团队展示了一个关键发现:在推理阶段,结合「生成 - 验证」(generate-and-verify)范式从而增加计算量(test-time compute)可以显著提升 VLA 模型的泛化能力与可靠性。
与此同时,论文系统性地探讨了具身智能中的 Test-Time Scaling Law:随着推理阶段的采样与验证规模增长,VLA 模型在任务成功率和稳定性方面呈现出可预测的提升规律。
 论文标题:RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models
论文地址:https://arxiv.org/abs/2506.17811
代码链接:robomonkey-vla.github.io
作者邮箱:jackykwok@stanford.edu
接收会议:CoRL 2025
论文标题:RoboMonkey: Scaling Test-Time Sampling and Verification for Vision-Language-Action Models
论文地址:https://arxiv.org/abs/2506.17811
代码链接:robomonkey-vla.github.io
作者邮箱:jackykwok@stanford.edu
接收会议:CoRL 2025 具身 Test-Time Scaling Law
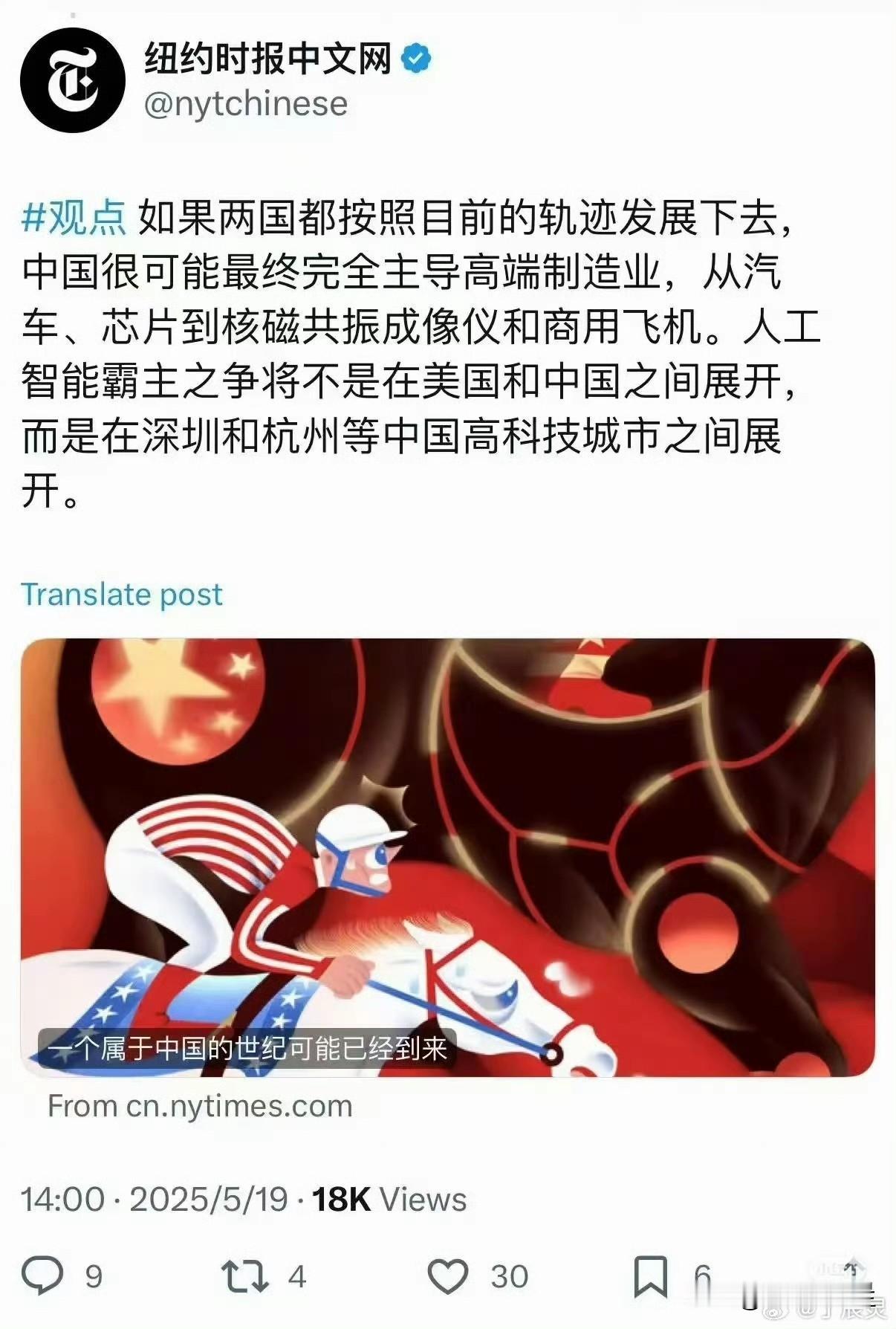
团队通过大量实验发现:当在推理阶段增加候选动作的生成数量时,VLA 的动作误差会持续下降。具体来说,无论是反复从机器人策略模型中采样动作、对部分采样动作施加高斯扰动,还是在离散动作空间中进行随机采样,这些方法在有「理想验证器」(oracle verifier)的前提下,都能显著优于单次推理的 OpenVLA 基线。
团队还揭示出一个幂律规律(power law):在多种主流 VLA 模型(包括 CogACT、Octo、OpenVLA 和 SpatialVLA)中,动作误差与高斯扰动采样数量之间呈现出稳定的幂律关系。这意味着,机器人控制问题不应仅仅被视为一个「生成」任务;相反,生成候选动作 + 验证筛选的范式,能在不改动训练模型的前提下显著提升性能。研究者希望这一发现能够推动动作验证器(scalable action verifiers)的发展,为通用机器人模型提供更稳健的落地路径。
核心问题
在提出具身 Test-Time Scaling Law 之后,研究团队进一步聚焦于三个关键问题:
验证器训练:是否能够利用训练得到的动作验证器(action verifier)来替代 oracle verifier,以提升 VLA 的稳定性? 合成数据扩展:能否构建大规模合成数据来训练验证器,从而推动下游任务的性能提升? 实际部署可行性:如何设计高效的算法与系统,使 test-time scaling 在真实机器人上实现低延迟、可扩展的部署?方法概述
阶段一・动作验证器训练

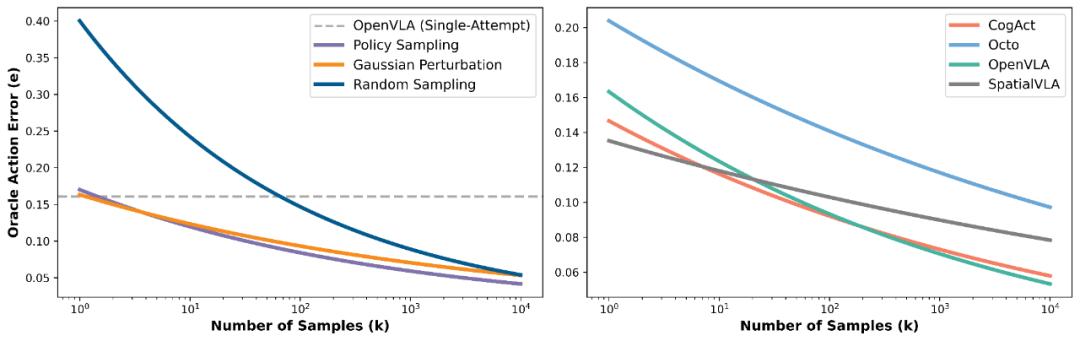
研究者首先利用机器人数据集,用 VLA 为每个状态采样 N 个候选动作,并通过聚类将其压缩为 K 个具有代表性的动作。随后,基于候选动作与真实动作(ground truth action) 的 RMSE 差异构造合成偏好数据(synthetic action preference dataset),并用其微调一个基于 VLM 的动作验证器 (VLM-based verifier),赋予模型对动作优劣的判别能力。该验证器的训练损失函数遵循 Bradley-Terry 模型,并在此基础上加入了对偏好强度(preference levels)的修正项。
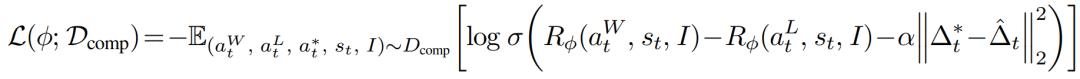
阶段二・推理阶段的计算扩展

在实际部署中,系统会根据任务指令和环境观测,用 VLA 采样 N̂ 个初始动作。研究者对这些动作的平移与旋转部分拟合高斯分布,并通过多数投票(majority voting)确定抓取器的开合状态,构建出高效的动作分布。由此便可以在几乎不增加计算开销的前提下,快速采样出 K̂ 个候选动作。最后,利用在阶段一中训练好的 VLM 动作验证器,对这些候选动作进行评估和排序,从中挑选出最优动作执行。
实验结果

研究表明将 VLA 模型与 RoboMonkey 结合可以带来显著性能提升:
在真实世界的 out-of-distribution tasks 上 + 25% 在 in-distribution SIMPLER 环境上 + 9% 在 LIBERO-Long benchmark+7%这些结果表明,RoboMonkey 不仅提升了整体成功率,还能在部署时有效缓解以下关键问题:
抓取不精准 任务推进失败 碰撞问题
扩展合成数据

实验结果表明,扩展合成数据集规模对验证器性能有显著提升作用。随着数据规模逐步增加,RoboMonkey 验证器的准确性呈近似对数线性(log-linear)增长,并在 SIMPLER 环境上的成功率显著提高。
高效推理部署
为了让 Test-Time Scaling 在真实系统中具备可部署性,研究团队在 SGLang 之上实现了一个专用的 VLA serving 引擎。该引擎支持高速的 VLA 动作重复采样,并通过高斯扰动高效地构建动作分布(action proposal distribution)。这一系统优化显著降低了推理阶段的开销。
此外,从系统架构的角度来看,RoboMonkey 在相同的延迟约束(latency target)下,如果配备了更大容量的高带宽存储器(HBM),GPU 就能够支持更高的吞吐量(throughput),从而进一步提升机器人基础模型的泛化能力。
总结
本文的主要贡献可总结如下:
提出具身推理缩放定律 —— 实验证明,在多个 VLA 模型中,动作误差与采样数量之间呈现幂律关系。 可扩展的验证器训练流程 —— 构建了一条自动生成动作偏好数据的方法,并基于此提出了训练 VLM 动作验证器的框架。 验证 Test-Time Scaling 的有效性 —— 证明了所提出的 test-time scaling 框架能够在无需重新训练 VLA 的前提下显著增强 VLA 模型的表现。