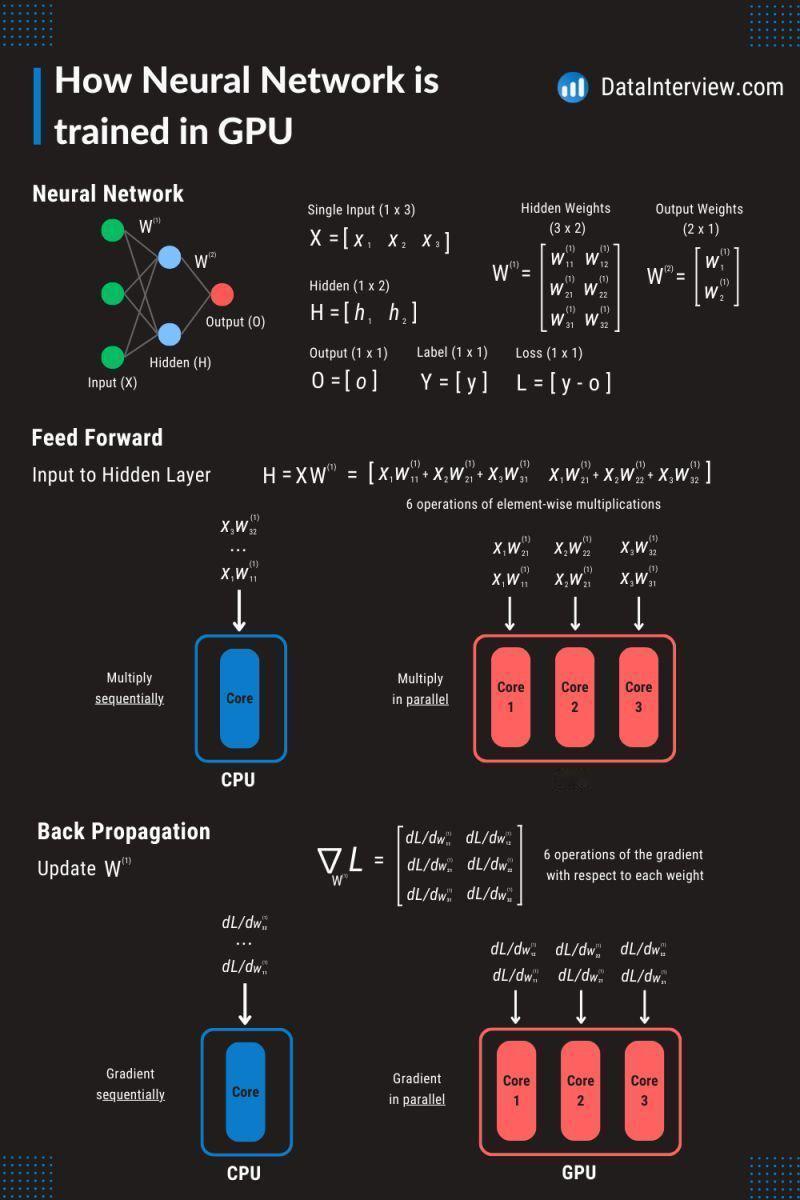
想让AI训练得更快?GPU已经成为神经网络训练不可或缺的存在。 你有没有好奇过,它们到底是怎么“强强联手”的呢? 通过这张图,一起来了解训练过程的基本步骤和原理: 一、神经网络结构 在GPU上训练神经网络时,需要首先定义神经网络的结构,包括输入层、隐藏层和输出层,以及每层的节点数。同时,初始化权重和偏置。 二、前向传播 在前向传播阶段,输入数据通过隐藏层传递到输出层。这一过程涉及大量的矩阵乘法运算,公式为H=XW(1),其中H是隐藏层的输出,X是输入数据,W(1)是权重矩阵。 在CPU上,这些运算是顺序执行的,而在GPU上,由于其并行处理能力,这些运算可以同时进行,大大提高了计算速度。 三、反向传播(Back Propagation) 神经网络给出了预测,但它肯定不是百分百准确。这时候,我们就需要计算“损失”(L),损失 L 是通过比较模型的预测输出O和实际标签Y计算得到的,如L=[y−o]。 反向传播的核心,是计算损失函数对每个权重(w)的梯度,这些梯度指示了如何调整权重以减少损失。 最后,使用梯度下降或其他优化算法来更新权重,让预测变得越来越准确,直到损失达到最低点。 同样,在GPU上,这些梯度计算可以并行执行,进一步提高了效率。