机器之心报道
机器之心编辑部
存在 10 多年后,VAE(变分自编码器)时代终于要淘汰了吗?
就在今天,纽约大学助理教授谢赛宁团队放出了新作 ——VAE 的替代解决方案 ——RAE(Representation Autoencoders,表征自编码器)。
他表示,三年前,DiT(Diffusion Transformer) 用基于 Transformer 的去噪骨干网络取代了传统的 U-Net。那时候就知道,笨重的 VAE 迟早也会被淘汰。如今,时机终于到了。

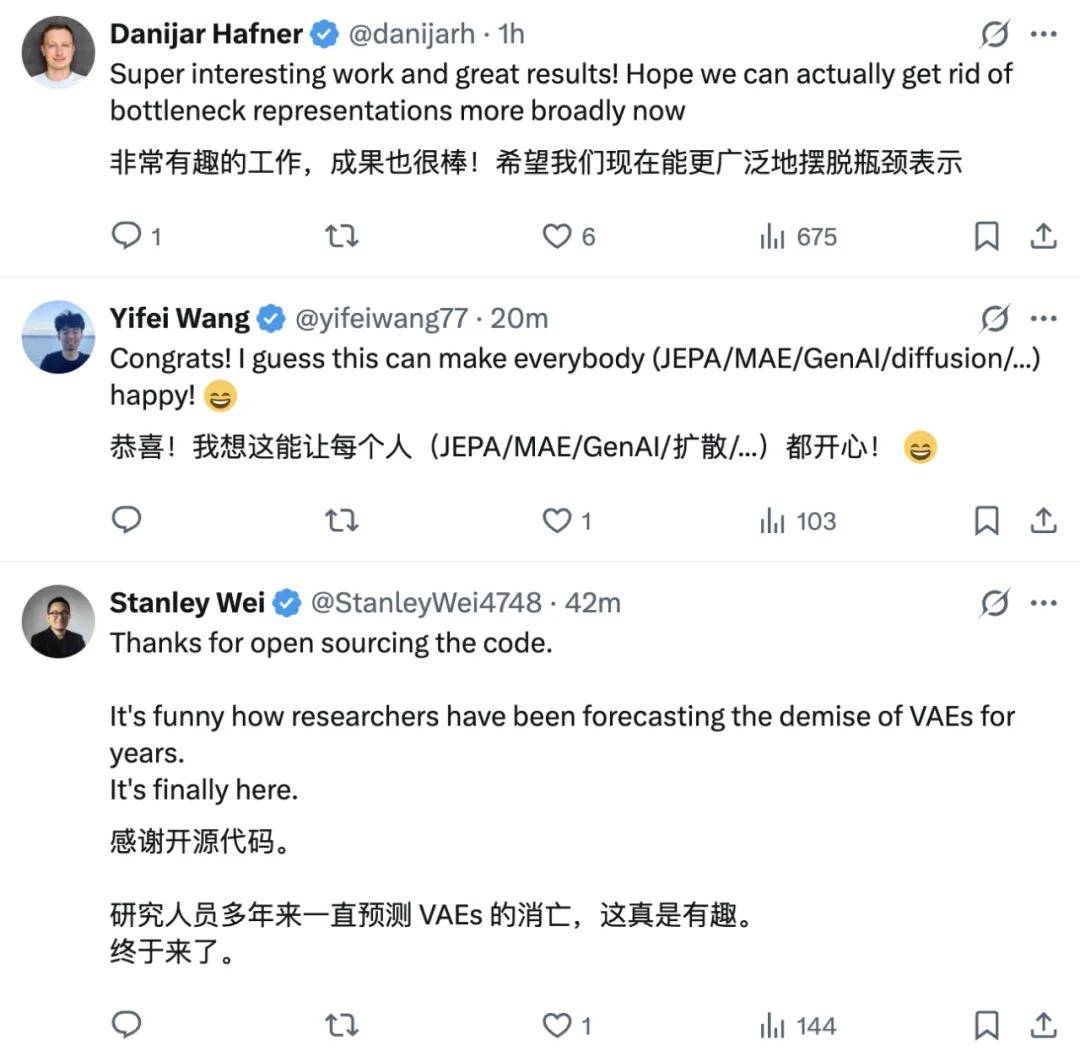
谢赛宁进一步做出了解释,DiT 虽然取得了长足的进步,但大多数模型仍然依赖于 2021 年的旧版 SD-VAE 作为其潜空间基础。这就带来了以下几个主要问题:
过时的骨干网络使架构比实际需要的更复杂:SD-VAE 的计算量约为 450 GFLOPs,而一个简单的 ViT-B 编码器只需要大约 22 GFLOPs。 过度压缩的潜空间(只有 4 个通道)限制了可存储的信息量:人们常说压缩带来智能,但这里并非如此:VAE 式压缩实际上作用有限,几乎和原始的三通道像素一样受限。 表征能力弱:由于仅使用重建任务进行训练,VAE 学到的特征很弱(线性探针精度约 8%),这会导致模型收敛更慢、生成质量下降。我们现在已经很清楚 —— 表征质量直接影响生成质量,而 SD-VAE 并不是为此而设计的。因此,谢赛宁团队将预训练的表征编码器(如 DINO、SigLIP、MAE)与训练好的解码器相结合,以取代传统的 VAE,形成了一种新的结构 —— 表征自编码器(RAE)。这种模型既能实现高质量的重建,又能提供语义丰富的潜空间,同时具备可扩展的 Transformer 架构特性。
由于这些潜空间通常是高维的,一个关键的挑战在于如何让 DiT 能够在其中高效地运行。从原理上来说,将 DiT 适配到这些高维语义潜空间是可行的,但需要经过精心的设计。最初的 DiT 是为紧凑的 SD-VAE 潜空间而设计的,当面对高维潜空间时会遇到多方面的困难,包括 Transformer 结构问题、噪声调度问题、解码器鲁棒性问题。
为此,研究者提出了一种新的 DiT 变体 ——DiT^DH,它受到了 DDT 的启发,但出发点不同。该变体在标准 DiT 架构的基础上,引入一个轻量、浅层但宽度较大的头部(head)结构,使扩散模型在不显著增加二次计算成本的前提下扩展网络宽度。
这一设计在高维 RAE 潜空间中进一步提升了 DiT 的训练效果,在 ImageNet 数据集上取得了优异的图像生成效果:在 256×256 分辨率下,无引导条件下的 FID 为 1.51;在 256×256 和 512×512 分辨率下,有引导条件下的 FID 均为 1.13。
因此,RAE 展现出了明显的优势,应当成为 DiT 训练的全新默认方案。
当然,RAE 的模型和 PyTorch 代码全部开源。这项工作的一作为一年级博士生 Boyang Zheng,其本科毕业于上海交通大学 ACM 班。
 论文标题:Diffusion Transformers with Representation Autoencoders
论文地址:https://arxiv.org/abs/2510.11690
项目主页:https://rae-dit.github.io/
代码:https://github.com/bytetriper/RAE
HuggingFace:https://huggingface.co/collections/nyu-visionx/rae-68ecb57b8bfbf816c83cce15
论文标题:Diffusion Transformers with Representation Autoencoders
论文地址:https://arxiv.org/abs/2510.11690
项目主页:https://rae-dit.github.io/
代码:https://github.com/bytetriper/RAE
HuggingFace:https://huggingface.co/collections/nyu-visionx/rae-68ecb57b8bfbf816c83cce15 从网友的反馈来看,大家非常看好 RAE 的前景,预计可以为生成模型带来新的可能性。
基于冻结编码器的高保真重建
研究者挑战了一个普遍的假设,即像 DINOv2 和 SigLIP2 这类预训练表征编码器不适合重建任务,因为它们 “强调高层语义,而忽略了底层细节” 。
该研究证明,只要解码器训练得当,冻结的表征编码器实际上可以作为扩散潜在空间的强大编码器。RAE 将冻结的预训练表征编码器与一个基于 ViT 的解码器配对,其重建效果与 SD-VAE 相当甚至更优。
更重要的是,RAE 缓解了 VAE 的根本局限性,后者的潜在空间被高度压缩(例如,SD-VAE 将的图像映射到的潜在表征,这限制了重建的保真度,更关键的是,也限制了表征的质量。
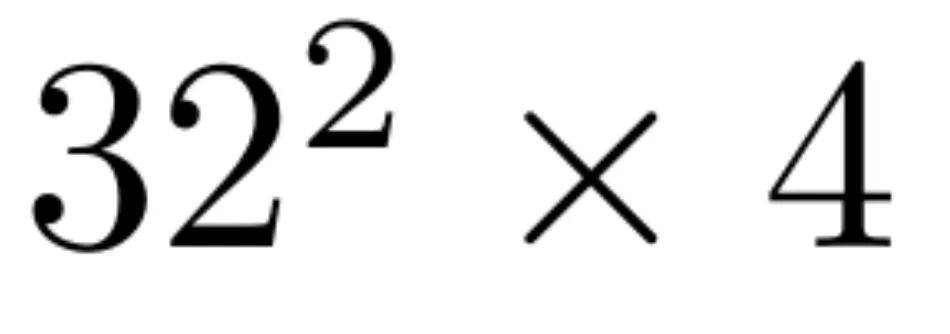
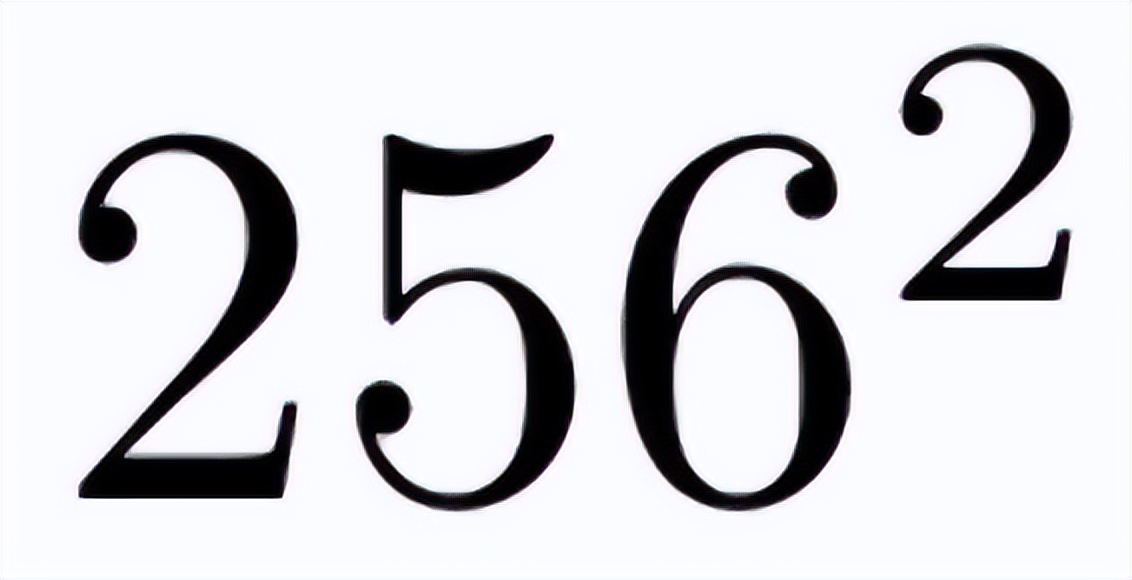
用于 RAE 解码器的训练方案如下:
首先,给定一个尺寸为 3×H×W 的输入图像 x,并使用一个预先训练好且冻结的表征编码器 E。该编码器的 patch 大小为 p_e,隐藏层大小为 d。经过编码器处理后,输入图像被转换为个 token,每个 token 都有 d 个通道。
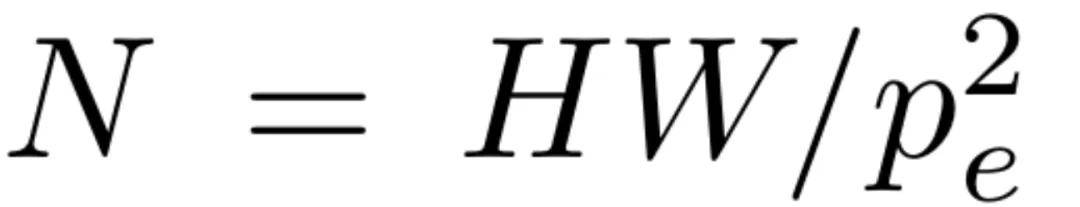
接着,一个 patch 大小为 p_d 的 ViT 解码器 D 会接收这些 token,并将它们映射回像素空间,重建出图像。重建图像的输出形状为。在默认情况下,设置 p_d = p_e,从而使重建结果与输入的分辨率相匹配。
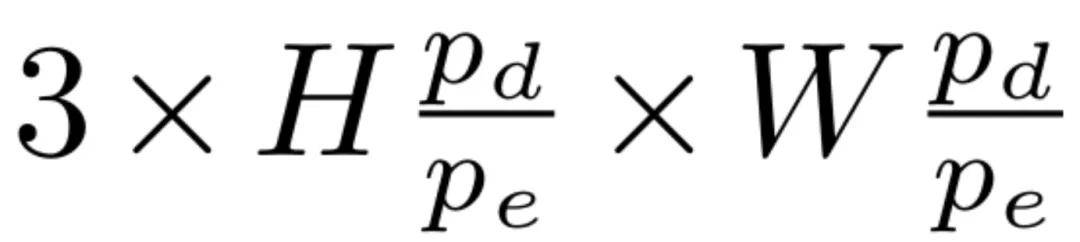
在所有针对 256×256 图像的实验中,编码器均产生 256 个 token。这个数量与多数先前基于 DiT 且使用 SD-VAE 潜在表征进行训练的模型的 token 数量相符。
最后,在训练解码器 D 时,遵循了 VAE 的常见做法,采用了 L1 损失、LPIPS 损失和对抗性损失相结合的优化目标:
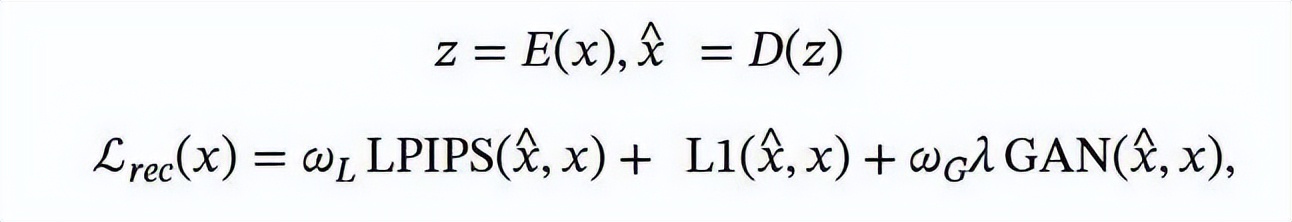
研究者从不同的预训练范式中选择了三个代表性的编码器:
DINOv2-B (p_e=14,d=768),一个自监督自蒸馏模型; SigLIP2-B (p_e=16,d=768),一个语言监督模型; MAE-B (p_e=16,d=768),一个掩码自编码器。对于 DINOv2,还研究了不同模型尺寸 S、B、L (d=384,768,1024)。除非另有说明,研究者在所有 RAE 中都使用 ViT-XL 解码器。研究者使用在重建的 ImageNet 验证集上计算的 FID 分数作为衡量重建质量的主要指标,记为 rFID。
重建、扩展性与表征能力

如表 1a 所示,使用冻结编码器的 RAE 在重建质量 (rFID) 上一致优于 SD-VAE。例如,使用 MAE-B/16 的 RAE 达到了 0.16 的 rFID,明显胜过 SD-VAE,并挑战了表征编码器无法恢复像素级细节的假设。
接下来,研究了编码器和解码器的扩展性行为。如表 1c 所示,在 DINOv2-S、B 和 L 三种尺寸下,重建质量保持稳定,这表明即使是小型的表征编码器模型也保留了足够的底层细节以供解码。在解码器方面(表 1b),增加其容量能够持续提升 rFID:从 ViT-B 的 0.58 提升到 ViT-XL 的 0.49。重要的是,ViT-B 的性能已经超过 SD-VAE,而其 GFLOPs 效率要高出 14 倍;ViT-XL 则以仅为 SD-VAE 三分之一的计算成本进一步提升了质量。
研究者还在表 1d 中通过在 ImageNet-1K 上的线性探测来评估表征质量。因为 RAE 使用冻结的预训练编码器,它们直接继承了底层表征编码器的表征能力。相比之下,SD-VAE 仅实现了约 8% 的准确率。
为 RAE 驾驭扩散 Transformer
在 RAE 已展示出良好重建质量的基础上,研究者进一步探讨了其在潜空间的可扩散性。
在正式进入生成实验之前,研究者首先固定编码器,以研究不同编码器下的生成能力。表 1a 显示,MAE、SigLIP2 和 DINOv2 的重建误差(rFID)均低于 SD-VAE,其中 MAE 的重建表现最好。
然而,研究者指出:仅有重建质量好并不意味着生成质量高。在实际实验中,DINOv2 在图像生成任务中的表现最强。因此,除非特别说明,后续实验都将默认使用 DINOv2 作为编码器。在模型架构上,研究者使用了 LightningDiT 作为基础网络,它是 DiT 的一种改进版本。
然而,出乎意料的是,标准的扩散模型训练方法在 RAE 潜空间中完全失效(见表 2)。
当直接在 RAE 的潜变量上进行训练时:
小规模的模型(如 DiT-S)会彻底训练失败,无法生成有效结果; 较大的模型(如 DiT-XL)虽然能够训练,但其表现仍然远逊于在 SD-VAE 潜空间上训练的同等规模模型。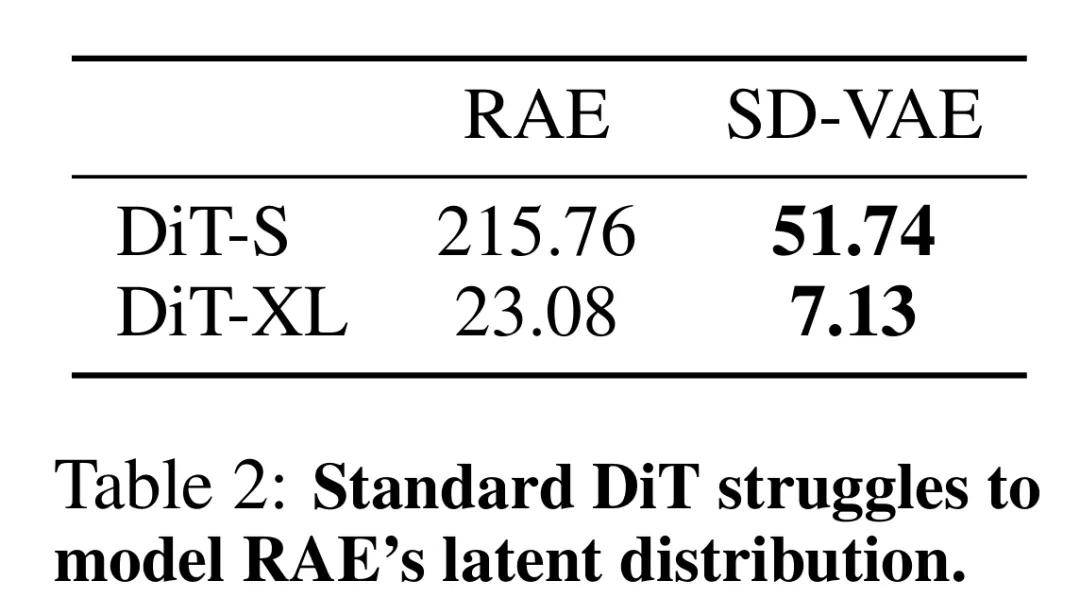
为了研究这一观察结果,研究者提出了下面几个假设:

扩展 DiT 宽度以匹配 Token 维度
为分析扩散 Transformer (DiT) 在 RAE 潜变量上的训练动态,研究人员进行了一项简化实验,旨在通过 DiT 重建由 RAE 编码的单个图像。实验通过固定模型深度并改变其宽度(隐藏维度 d)发现,当模型宽度小于 Token 维度 n (dn=768) 时,样本质量和训练损失表现均很差。然而,一旦宽度匹配或超过 Token 维度 (d ≥ n),样本质量便会急剧提升至近乎完美,同时训练损失也迅速收敛。
为排除这种性能提升仅是模型总容量增加的结果,对照实验将宽度固定为较小值 (d=384) 并将深度加倍。结果显示,模型性能并未改善,图像依然充满瑕疵,且损失无法收敛。这表明,要使 DiT 在 RAE 的潜空间中成功生成,其模型宽度必须匹配或超过 RAE 的 Token 维度。
这一要求似乎与数据流形具有较低内在维度的普遍认知相悖。研究者推断,这源于扩散模型的内在机制:在训练过程中持续向数据注入高斯噪声,实际上将数据流形的支撑集扩展至整个空间,使其成为一个「满秩流形」。因此,模型容量必须与完整的数据维度成比例,而非其较低的内在维度。
该猜想得到了理论下界 L≥(n−d)/n 的支持,该公式与实验结果高度吻合。研究人员通过将不同宽度的 DiT 模型 (S/B/L) 与具有相应 Token 维度的 DINOv2 编码器 (S/B/L) 配对,在更真实的场景中进一步验证了此结论:模型仅在自身宽度不小于编码器 Token 维度时才能有效收敛。

维度相关的噪声调度偏移
先前研究已证实,扩散模型训练中的最优噪声调度与输入数据的空间分辨率相关。本文将此概念从空间分辨率推广至有效数据维度,即 Token 数量与 Token 维度的乘积。其核心在于,高斯噪声会同等地作用于所有维度,因此 RAE 潜变量的高维度(与传统 VAE 或像素的低通道数不同)在相同的噪声水平下能保留更多信息,从而需要调整噪声注入的策略。
为此,研究者采用了 Esser et al. (2024) 的调度偏移方法,通过一个维度相关的缩放因子 α=m/n 来调整噪声时间步长(其中 m 为 RAE 的有效数据维度,n 为基准维度)。实验结果表明,应用此维度自适应的噪声调度带来了显著的性能提升,证明了在高维潜空间中训练扩散模型时进行此项调整的必要性。

噪声增强解码
RAE 解码器通常基于一组离散、干净的潜变量进行训练。然而,扩散模型在推理时生成的潜变量往往带有噪声或与训练分布存在偏差,这会给解码器带来分布外 (OOD) 挑战,从而降低最终的样本质量。
为缓解这一问题,研究者提出了噪声增强解码方案。该方法在训练解码器时,向原始的干净潜变量 z 中注入了加性高斯噪声 n∼N (0,σ2I)。此过程通过平滑潜在分布,增强了解码器对扩散模型产生的更密集、更连续的输出空间的泛化能力。为进一步正则化训练并提升鲁棒性,噪声的标准差 σ 也被随机化。
这一技术带来了预期的权衡:通过提升对 OOD 潜变量的鲁棒性,模型的生成指标 (gFID) 得以改善,但由于注入的噪声会去除部分精细细节,重建指标 (rFID) 会略微下降。
最终,将上述所有技术(模型宽度匹配、噪声调度偏移及噪声增强解码)相结合,一个在 RAE 潜变量上训练的 DiT-XL 模型在 720 个 epoch 后实现了 2.39 的 gFID。这一成果在收敛速度上大幅超越了先前基于 VAE 潜变量的扩散模型(相比 SiT-XL 实现 47 倍训练加速)以及近期的表示对齐方法(相比 REPA-XL 实现 16 倍训练加速),为高效生成模型的训练树立了新的标杆。

实验结果
在标准的 DiT 架构中,处理高维的 RAE 潜变量通常需要扩大整个主干网络的宽度,而这会导致计算开销激增。
为了解决这一问题,研究者借鉴了 DDT 的设计思想,引入了 DDT head,一个浅层但宽度较大的 Transformer 模块,专门用于去噪任务。通过将该模块附加到标准的 DiT 上,模型能够在不显著增加计算量的情况下有效提升网络宽度。
研究者将这种增强后的架构称为 DiT^DH。
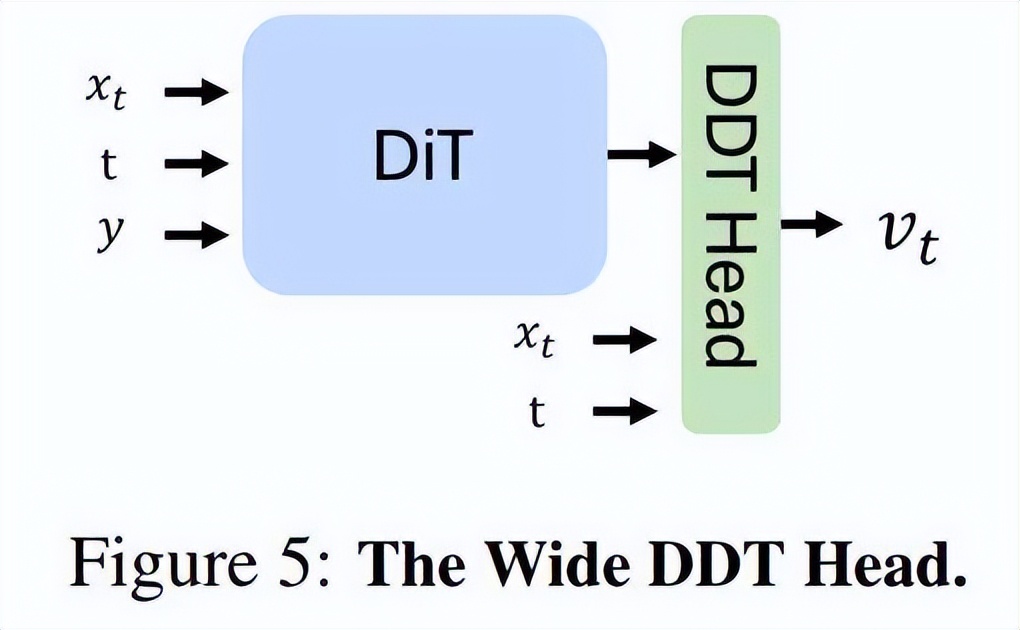
其中,DiT^DH 的收敛速度比 DiT 快,并且,DiT^DH 在计算效率(FLOPs)方面显著优于 DiT,如图 6a 所示。
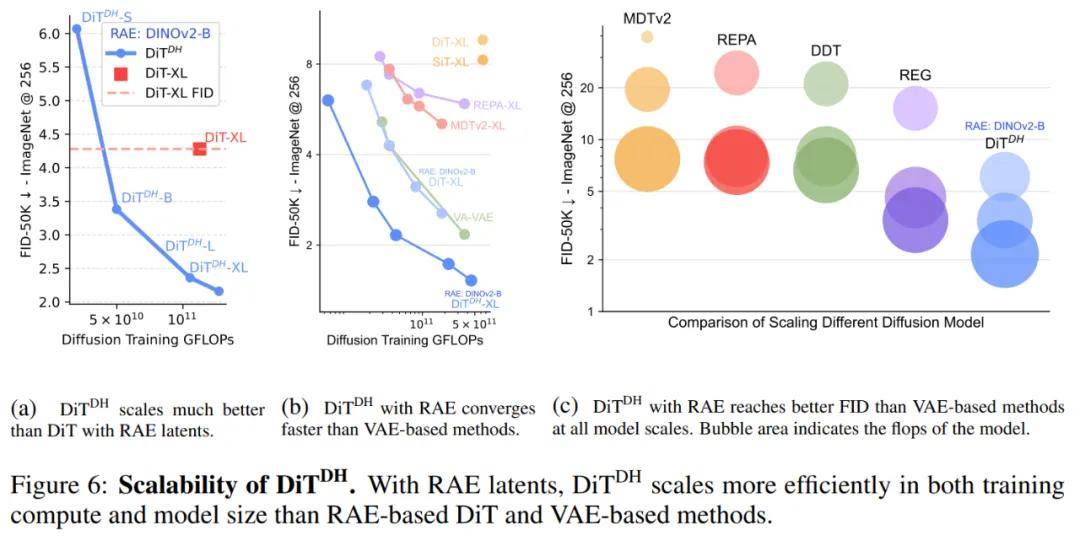
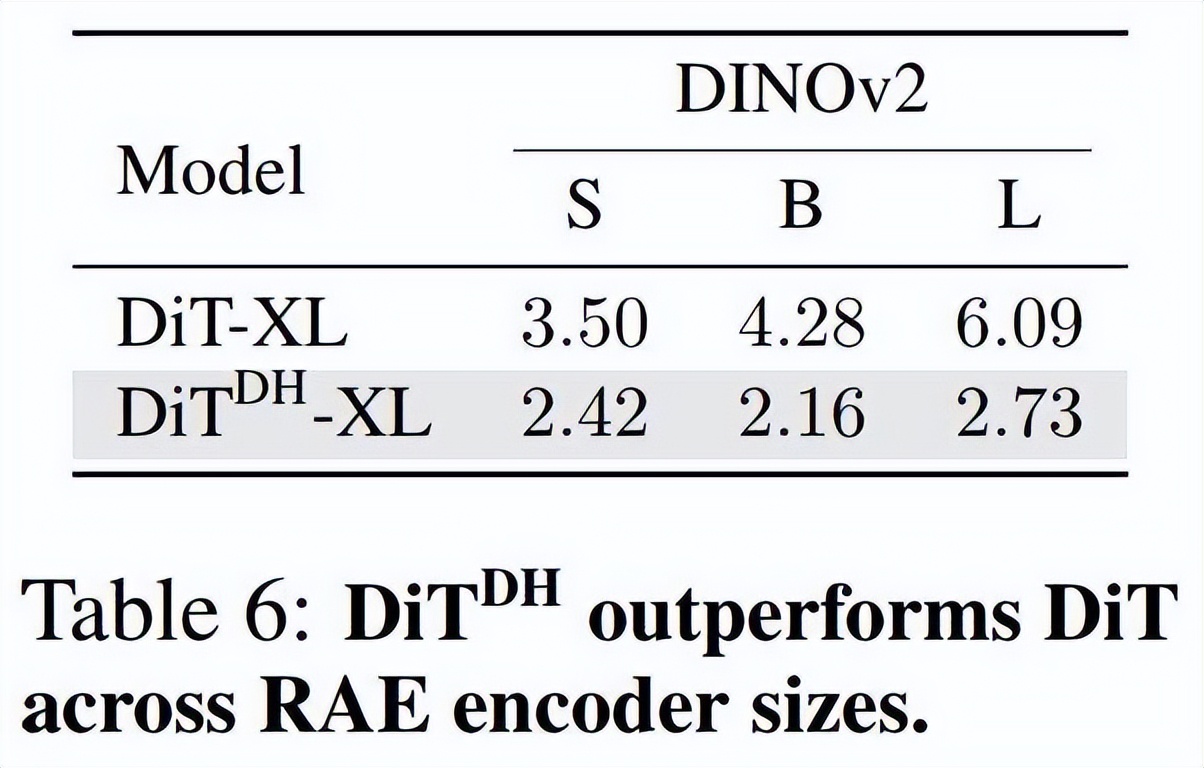
此外,DiT^DH 在不同规模的 RAE 上依然保持性能优势。
如表 6 所示,DiT^DH 在所有情况下都稳定优于 DiT,并且随着编码器规模的增大,其优势也随之扩大。例如,在使用 DINOv2-L 时,DiT^DH 将 FID 从 6.09 降低至 2.73。
研究者将这种鲁棒性归功于 DDT head 的设计。较大的编码器会生成更高维度的潜变量,这会放大 DiT 的宽度瓶颈问题。而 DiT^DH 通过满足宽度需求,同时保持特征表示紧凑,有效地解决了这一问题。
此外,DDT head 还能过滤掉高维 RAE 潜变量中更容易出现的噪声信息,从而进一步提升模型性能与稳定性。
收敛性。如图 6b 所示,研究者绘制了 DiT^DH-XL 的训练收敛曲线,实验结果显示:
当训练计算量达到约 5 × 10¹⁰ GFLOPs 时,DiT^DH-XL 的表现已经超越 REPA-XL、MDTv2-XL 和 SiT-XL 等模型。 在 5 × 10¹¹ GFLOPs 时,DiT^DH-XL 实现了全场最佳 FID,而所需计算量仅为这些基线模型的 1/40。换句话说,DiT^DH-XL 不仅收敛速度更快,而且在相同或更低的计算预算下能达到更优性能,展现出极高的计算效率与训练稳定性。
扩展性(Scaling)。研究者将 DiT^DH 与近年来不同规模的扩散模型进行了比较。结果如图 6c 所示:
随着 DiT^DH 模型规模的增加,其 FID 分数持续提升,表现出良好的可扩展性; 最小的模型 DiT^DH-S 已能取得 6.07 的 FID 分数,性能甚至超过了体量更大的 REPA-XL; 当模型从 DiT^DH-S 扩展到 DiT^DH-B 时,FID 由 6.07 变为 3.38,超越了所有相似规模甚至更大规模的以往模型; 进一步扩展到 DiT^DH-XL 后,性能继续提升,在仅 80 个训练周期(epochs)下取得了 2.16 的 FID,创下了新的 SOTA 纪录。最后,研究者对 DiT^DH-XL(该系列中性能最强的模型)与近期多款最先进的扩散模型进行了定量性能对比。结果显示:本文方法大大优于所有先前的扩散模型,在 256×256 下创下了新的最先进的 FID 分数:无指导时为 1.51,有指导时为 1.13。在 512×512 上,经过 400 次 epoch 训练,DiT^DH-XL 在有指导的情况下进一步实现了 1.13 的 FID,超过了 EDM-2 之前的最佳性能(1.25)。
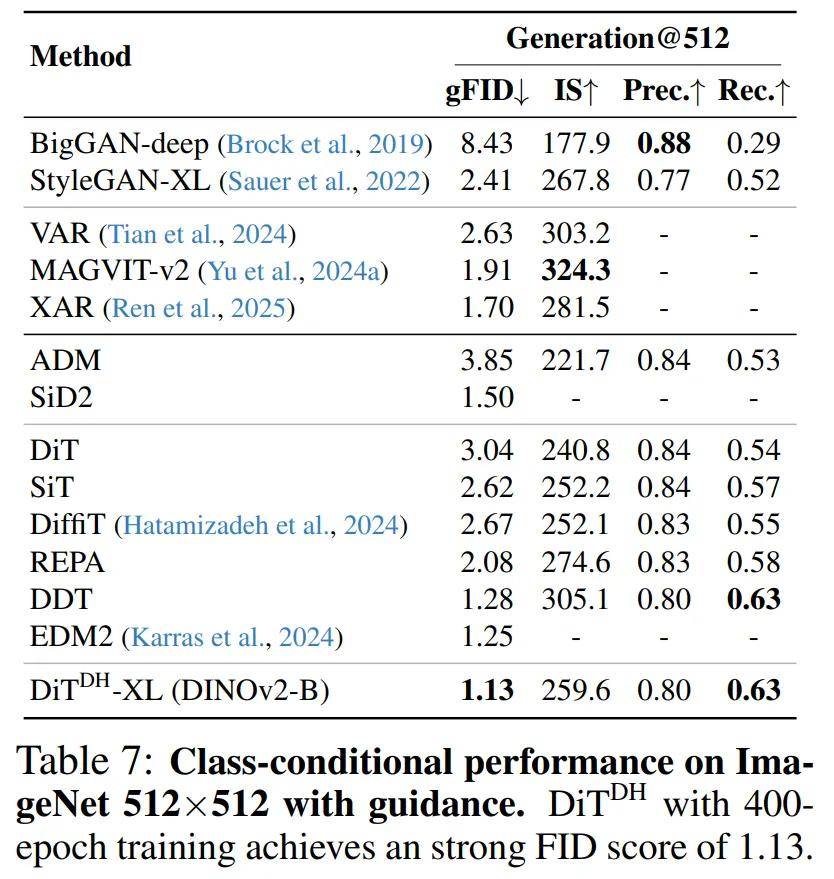
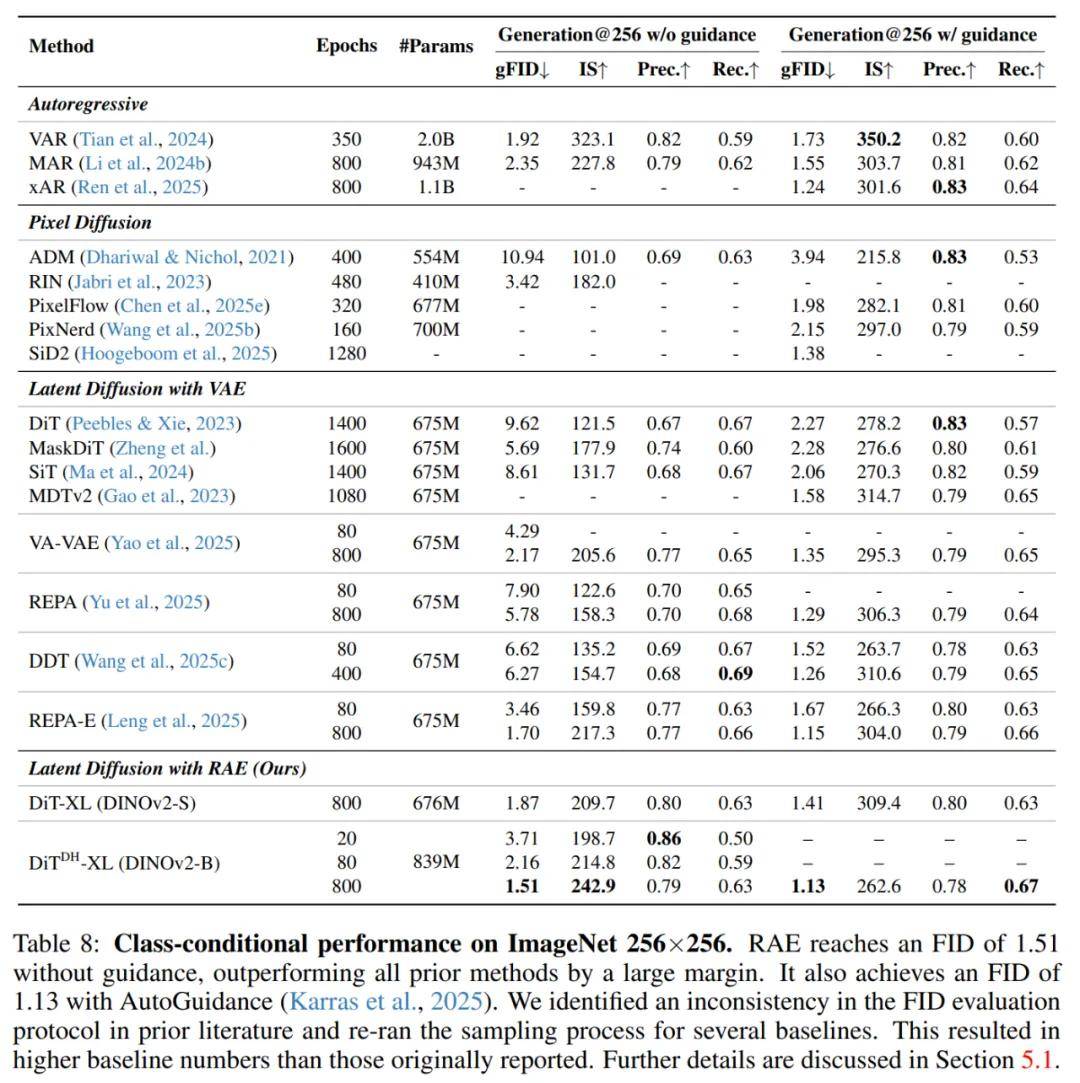
图 7 为可视化结果,模型能够生成多种类别和场景下的图像,反映出其强大的内容理解与泛化能力;图像细节逼真、纹理自然,与 ImageNet 的真实样本相当。

了解更多内容,请参考原论文。