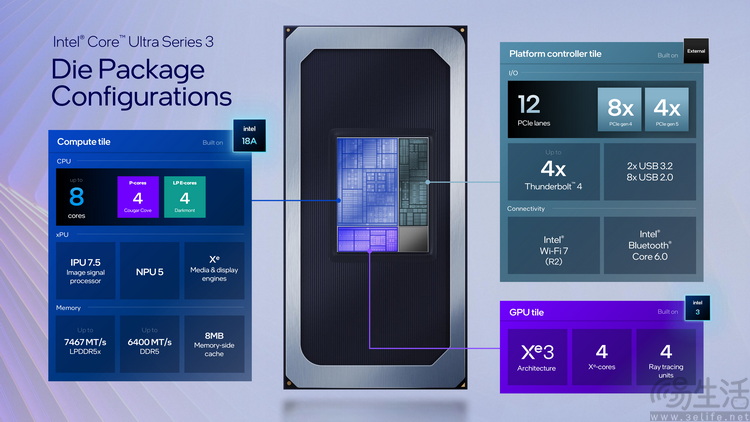
去年9月底,我们三易生活在Intel Tech Tour(技术之旅)活动中,提前接触到了英特尔的18A制程工艺,以及使用这一工艺的消费级和服务器CPU产品线。

不过那时候,由于相关芯片大多还处于测试阶段,所以虽然“摸”到了实物,但实际得到的产品信息大多还是偏向架构、制程之类的理论值。
好在,英特尔方面显然对他们新的消费级处理器信心十足。所以就在2026年刚开始,他们就在CES 2026(国际消费电子展)上,联合一众OEM厂商展出了大量基于第三代酷睿Ultra处理器的量产产品。仅仅几天后,我们也得到了更详细、基于量产产品和参考平台的各种实测成绩及细节信息。

当然,因为这些数据绝大多数其实已经在不久前结束的CES期间公布过,所以我们这次并不打算做简单的数据“复述”,而是会从中挖掘出一些更细节,可能没人注意到的信息。
跑分的微妙变化,其中却藏着关键信息
如果大家有仔细看去年秋季揭晓的相关资料就会发现,英特尔在当时虽然已经给出了新架构与LunarLake、Arrowlake的性能对比数据,但在彼时的对比图表里,一方面并未明确指出所用处理器的具体型号,另一方面所用的测试软件也是对内存带宽敏感的SPEC。这就不免“落下口实”,让人容易以为英特尔是在有意制造数据差异。

但是在最新的官方数据中,英特尔已经“改正”了这些问题。一方面现在他们明确了参与对比的处理器分别是各架构的顶配型号,另一方面也将测试软件换成了更偏实际应用,且对内存速度没那么敏感的CINEBENCH 2024。

结果在看似“不利”的条件下,第三代酷睿Ultra(准确来说,是其顶配型号388H)相比LunarLake(288V)的同功耗多核性能,反而从此前的领先50%以上变成了领先超过60%。哪怕是对比“看起来”P核数量更多(6P+8E+2LPE)的ArrowLake(285H),新一代酷睿Ultra也快了10%。
那么这意味着什么呢?简单来说,这就代表英特尔的E核、特别是LPE核在经过了数代的发展后,如今的IPC实际上已经越来越接近规模大得多的P核了。而且这还是在其P核、E核的峰值主频,比前代都更低的前提下所取得的领先。

既然如此,未来我们会不会看到英特尔在消费级转向“全小核”+“超多核”设计,或是像当年以发展型P6(酷睿)取代P7(奔腾4)路线那样,用小核作为主导重新推出“单一架构”的新处理器呢?从目前的信息来看,这个可能性似乎变得越来越大了。
核显进步超预期,更重要的是老产品也能获利
除了CPU部分的进步比去年秋季公布的数据更进一步之外,英特尔在CES 2026上公布的核显实测性能,也较去年刚披露时有了进一步的优化。
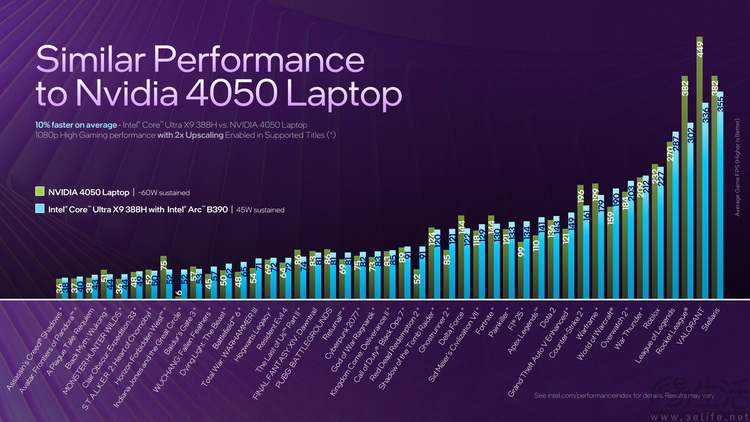
具体来说,拥有12核“Xe3”核心的ARC B390核显,在45W TDP下的平均游戏性能,就已经可以比60W TDP的RTX4050独显高出至少10%。

请注意,这里有两个细节。一是英特尔明确表示,消费者现在更喜欢看“游戏实测”、而不是“理论跑分”,所以他们更改了显卡测试的呈现方式,不再强调3DMARK之类的跑分成绩,而是直接用游戏实测数据说话。
第二点就在于,英特尔公布的这些数据,甚至还是在没有开启多帧生成的前提下测得,而这就是他们目前最有“底气”之处。因为无论英伟达的RTX40系列、还是AMD的旗舰核显(Radeon 8060s),都因为各种各样的原因无缘使用各家最新的多帧生成功能。

相比之下,第三代酷睿Ultra处理器的核显,反而成为了目前在这个级别里,唯一自带多帧生成,甚至是支持XeSS3硬件4倍帧生成的方案。如果英特尔真的想要在游戏帧率上“作弊”,完全可以打开这个功能来做对比。但他们并没有这么做。

此外我们还从英特尔方面了解到,ARC B390的4倍帧生成功能并非“独占”,它同样也会下放给英特尔过去的旧款核显以及独显产品。具体来说,只要是MeteorLake或之后型号处理器的核显,以及全系ARC独显,都将获得这一新功能的加持。
很显然,可以说英特尔这是看准了竞争对手目前产品线的弱点“有备而来”,但这又能怪谁呢?只能说英伟达和AMD在对于老产品的支持力度上,如今确实不如英特尔做得有诚意。
NPU算力相同、性能却有差?英特尔揭露了真相
最后,来看看第三代酷睿Ultra处理器在AI方面的一些官方数据,以及我们从中挖掘出的有趣细节。

根据英特尔方面目前的说法,第三代酷睿Ultra最高可以提供180TOPs的“平台算力”。其中120TOPs来自GPU,50TOPs源自NPU,剩下10TOPs则由CPU提供。
有看过我们三易生活此前一些相关内容的朋友可能还记得,对于绝大多数的PC来说,所谓“平台算力”这个说法其实都算得上是“耍流氓”。因为在这些系统里,不同的部件往往并不能真正协同去计算一个AI项目。但英特尔是个例外,因为他们从一开始就有自家的异构应用接口(One API),只要应用程序支持,就可以发挥出处理器不同模块的“算力”。
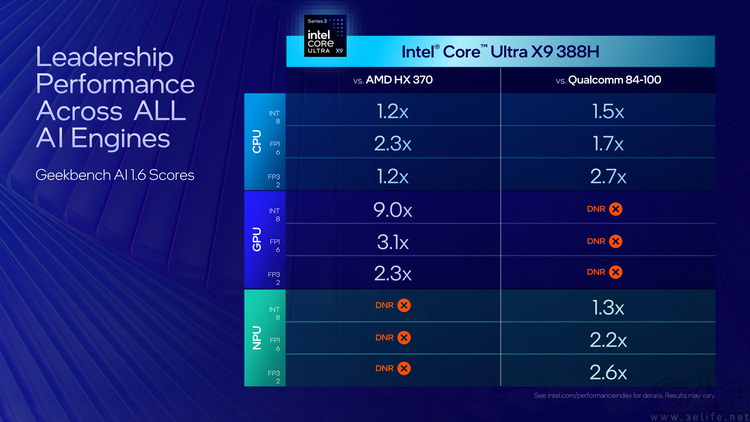
而且在第三代酷睿Ultra上,英特尔也格外强调了其AI引擎设计上的两个细节。一是它的核显与NPU都各自拥有独立的矩阵计算单元,且各自都能访问完整的系统内存池;二是它的CPU、GPU和NPU都支持INT8、FP16和FP32计算格式,因此才能确保真正的AI“异构融合”。很显然,这也是瞄准了竞品在硬件架构上的“硬伤”。
但英特尔在AI性能上曝光的“瓜”,还没这么简单。比如他们表示,大家都
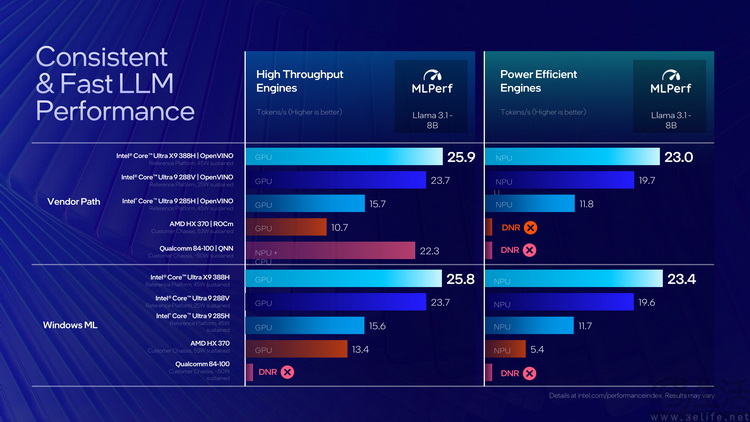
用NPU运行同样大小的大语言模型,第三代酷睿Ultra的速度可以达到AMD锐龙AI9 HX370的4.3倍;而用NPU计算相同的FP32浮点项目,第三代酷睿Ultra的速度也有高通骁龙X Elite 84-100型的2.6倍速度。
这里我们我们提醒一下大家,第三代酷睿Ultra的NPU“理论算力”是50TOPs,而AMD和高通被被拿来对比的处理器,它们集成的NPU“理论算力”同样也是50TOPs。为什么明明理论算力相同的NPU,实际测试的计算速度却有好几倍的差异呢?

这就不得不说到目前芯片行业在统计“算力”时经常耍的猫腻了,那就是大家普遍都只会用自家芯片“最擅长”的数据格式去声称算力水平。比如用低精度的INT4或FP6来统计算力,所以在遇到INT8或FP32的模型时,执行速度自然就会“缩水”数倍。
反之,当英特尔能够拿出明明是相同“TOPs”值,实际跑起来却要快上几倍的AI成绩时,似乎也表明他们的芯片架构设计,确实要更务实、更“实诚”些。






评论列表