[LG]《The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs》A Sinha, A Arun, S Goel, S Staab... [University of Cambridge & University of Stuttgart & Max Planck Institute for Intelligent Systems] (2025)
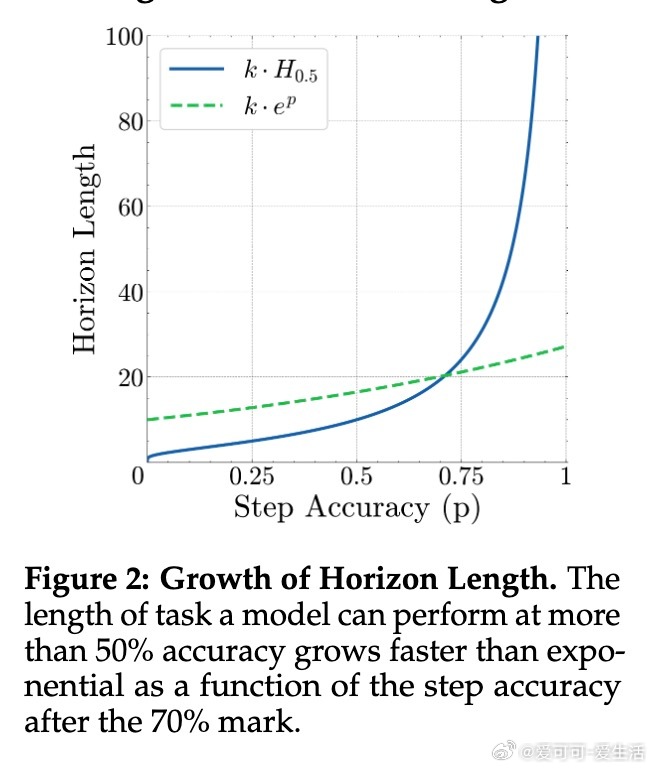
长任务执行能力是衡量大语言模型(LLM)经济价值的关键指标,单步准确率虽有边际递减,但对任务完成长度的提升呈指数级增长。最新研究通过提供明确的计划与知识,剥离推理与规划因素,聚焦执行能力,揭示了以下核心发现:
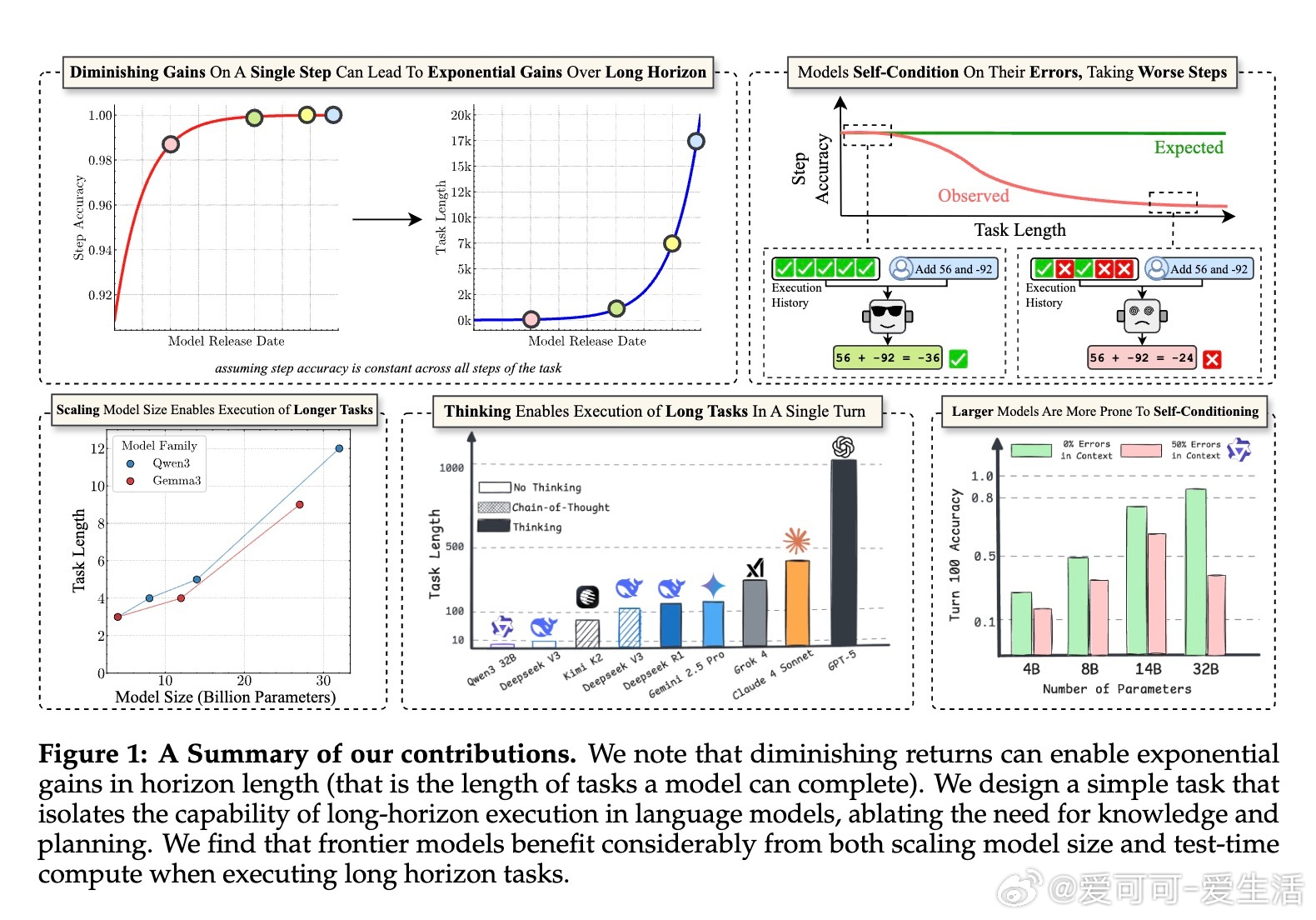
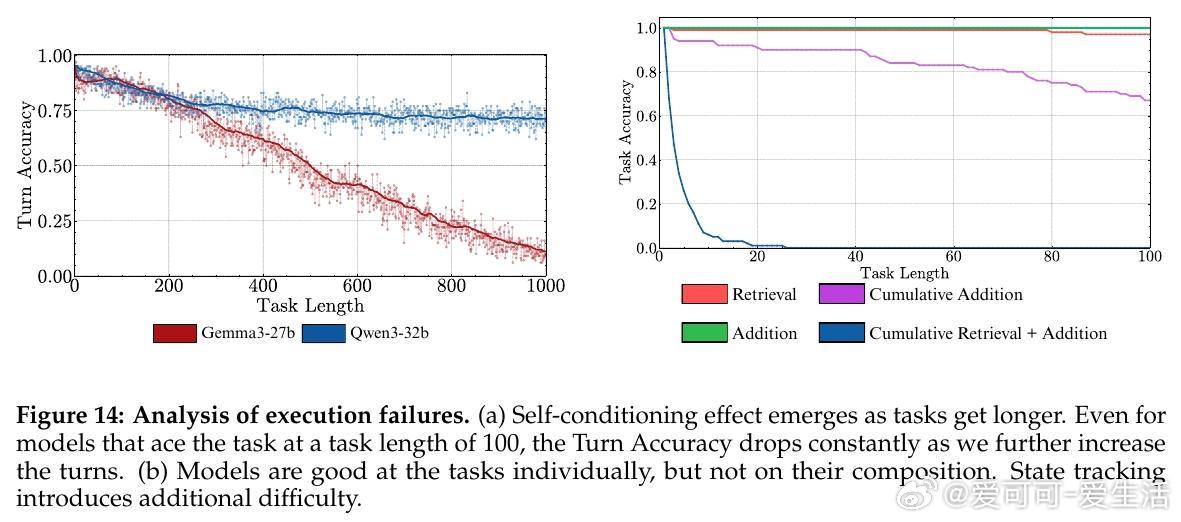
• 长期执行挑战:即使单步准确率接近100%,随着任务步数增加,模型整体完成率急剧下降,表明执行错误而非推理失败是长任务难题的根源。
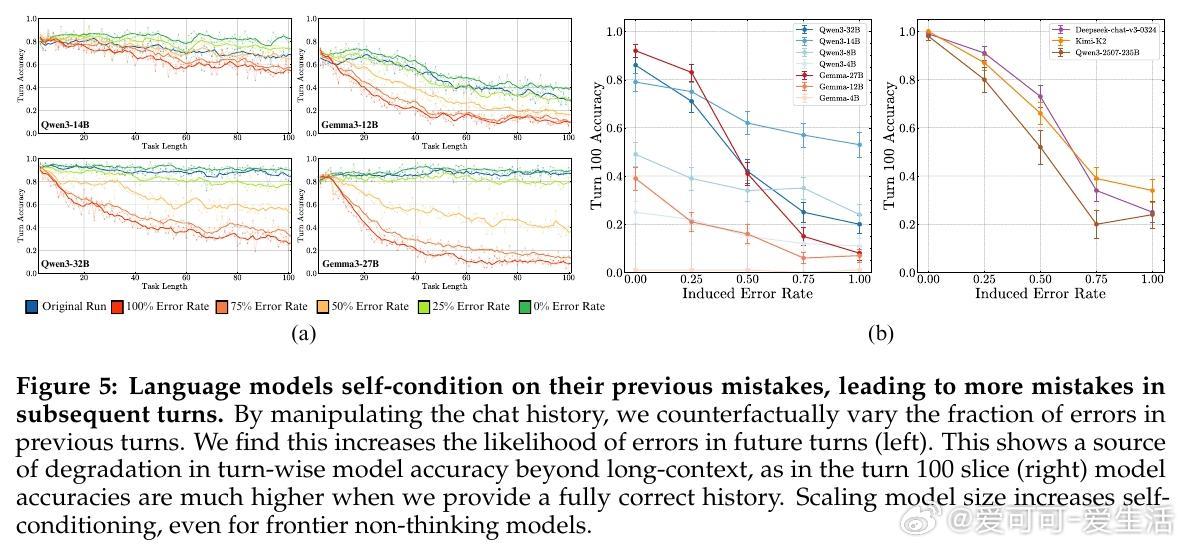
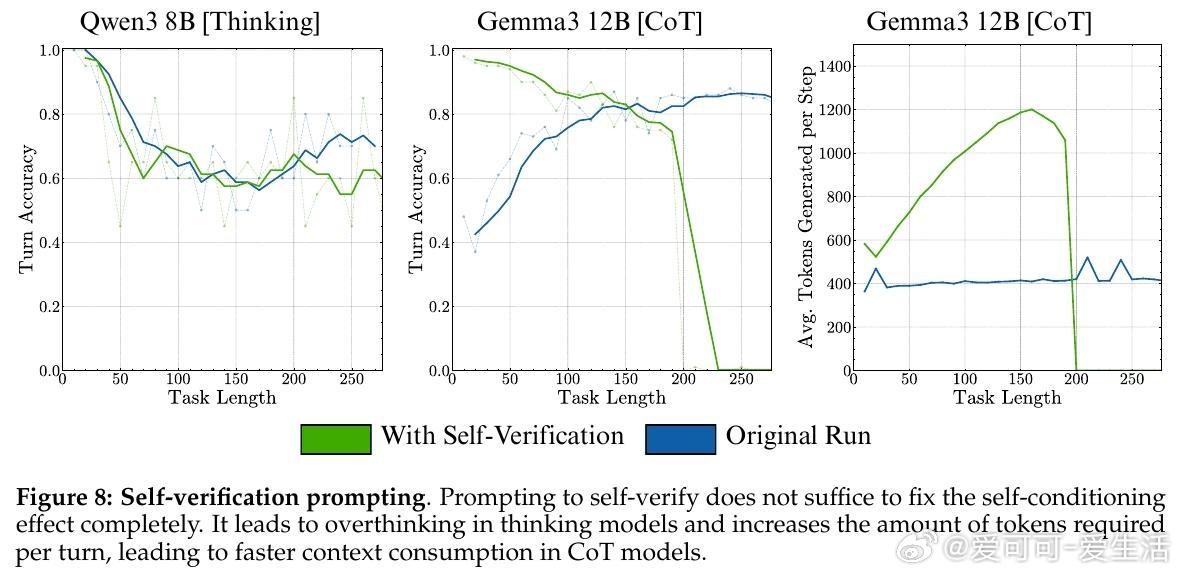
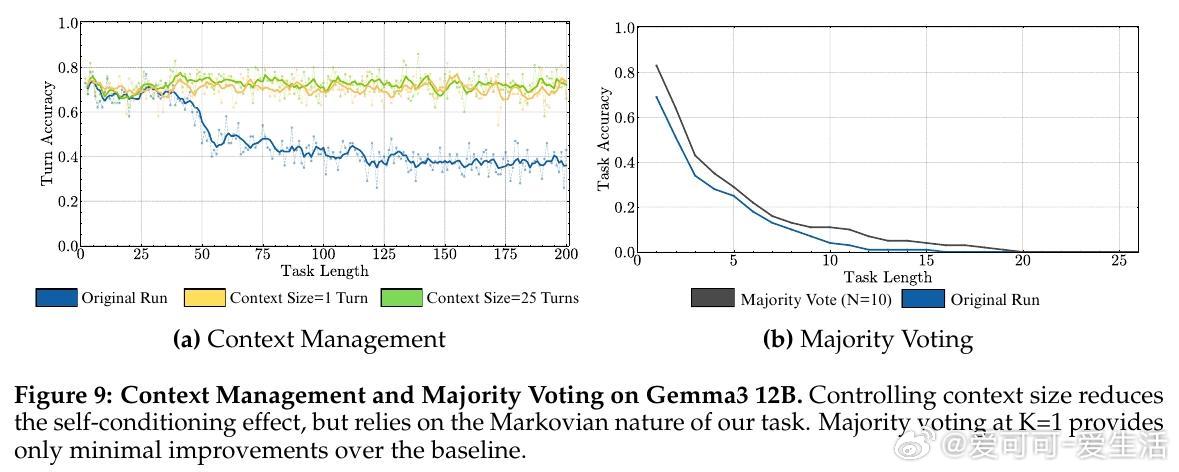
• 自我条件效应:模型在多轮任务中会“自我强化”此前的错误,导致错误率随时间攀升,且该效应不因模型规模扩大而减弱,体现了输出历史对模型决策的负面反馈。
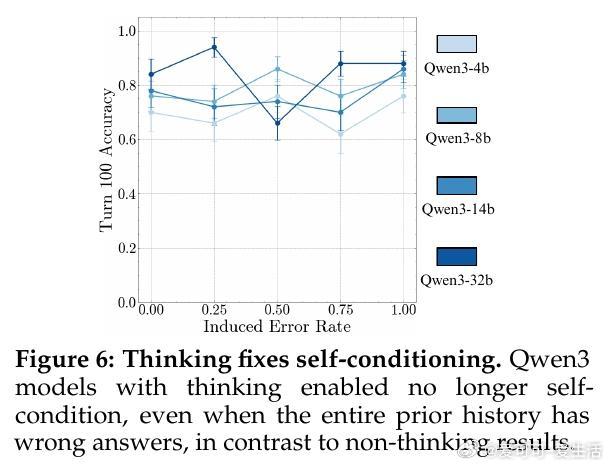
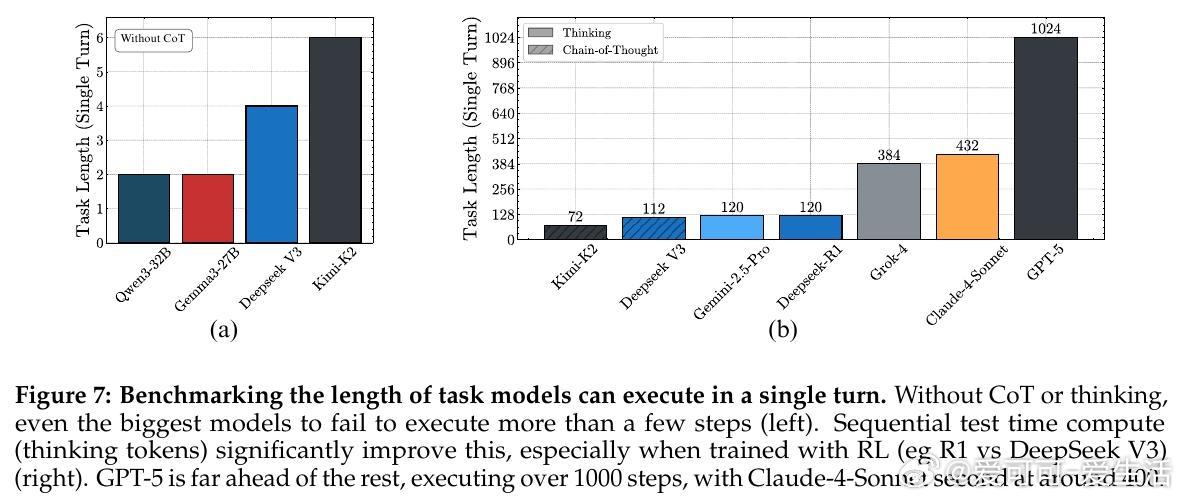
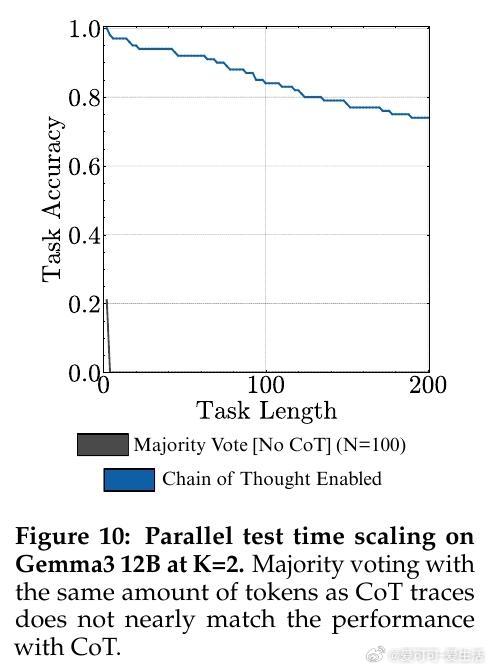
• 思考机制优势:引入“thinking”机制(如链式思考和强化学习训练)有效消除自我条件效应,显著延长模型单回合可执行的任务长度,顶尖模型GPT-5可执行超1000步,远超同侪。
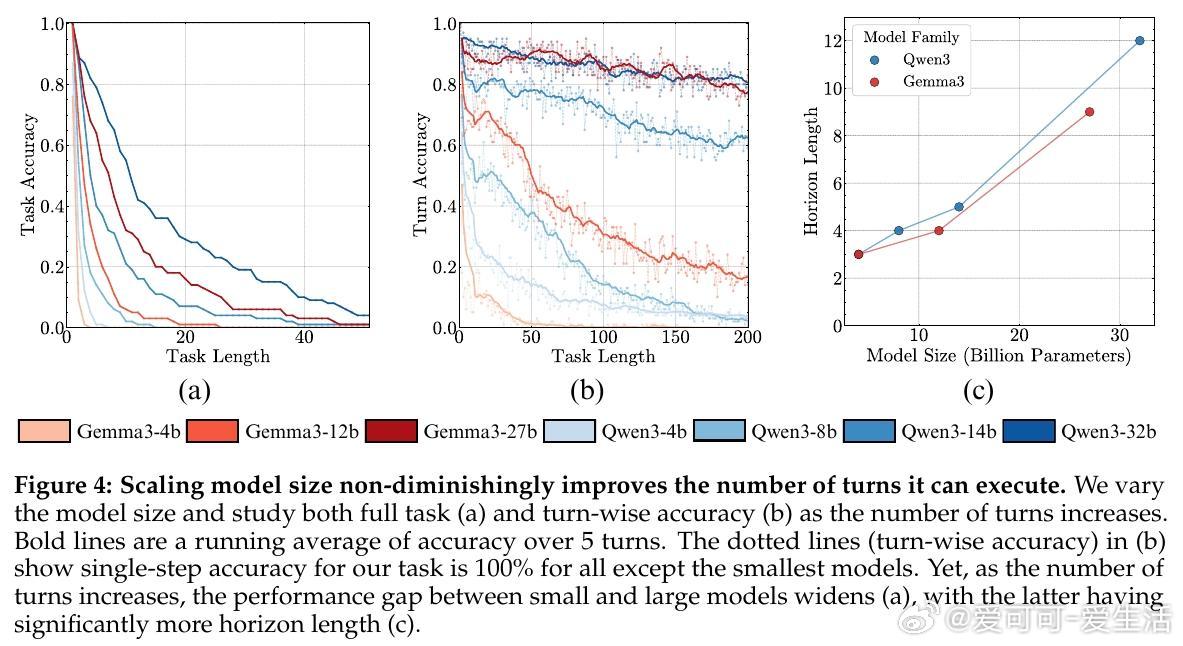
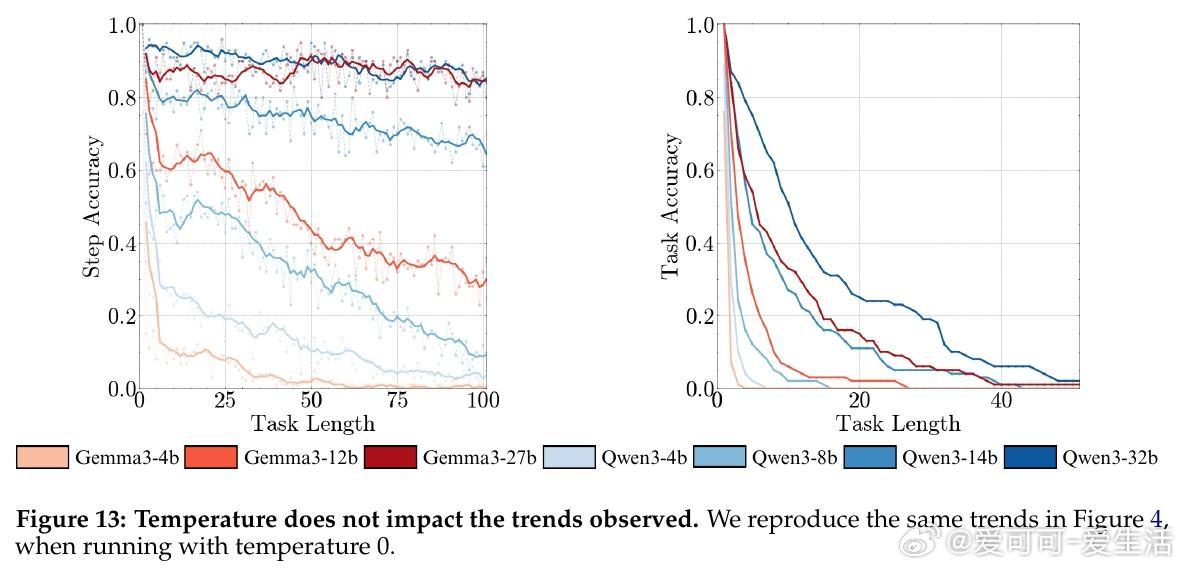
• 规模扩展非递减收益:模型规模提升带来执行能力显著增强,支持持续投资大模型训练以应对长任务,而非如表面上看短任务准确率增长缓慢。
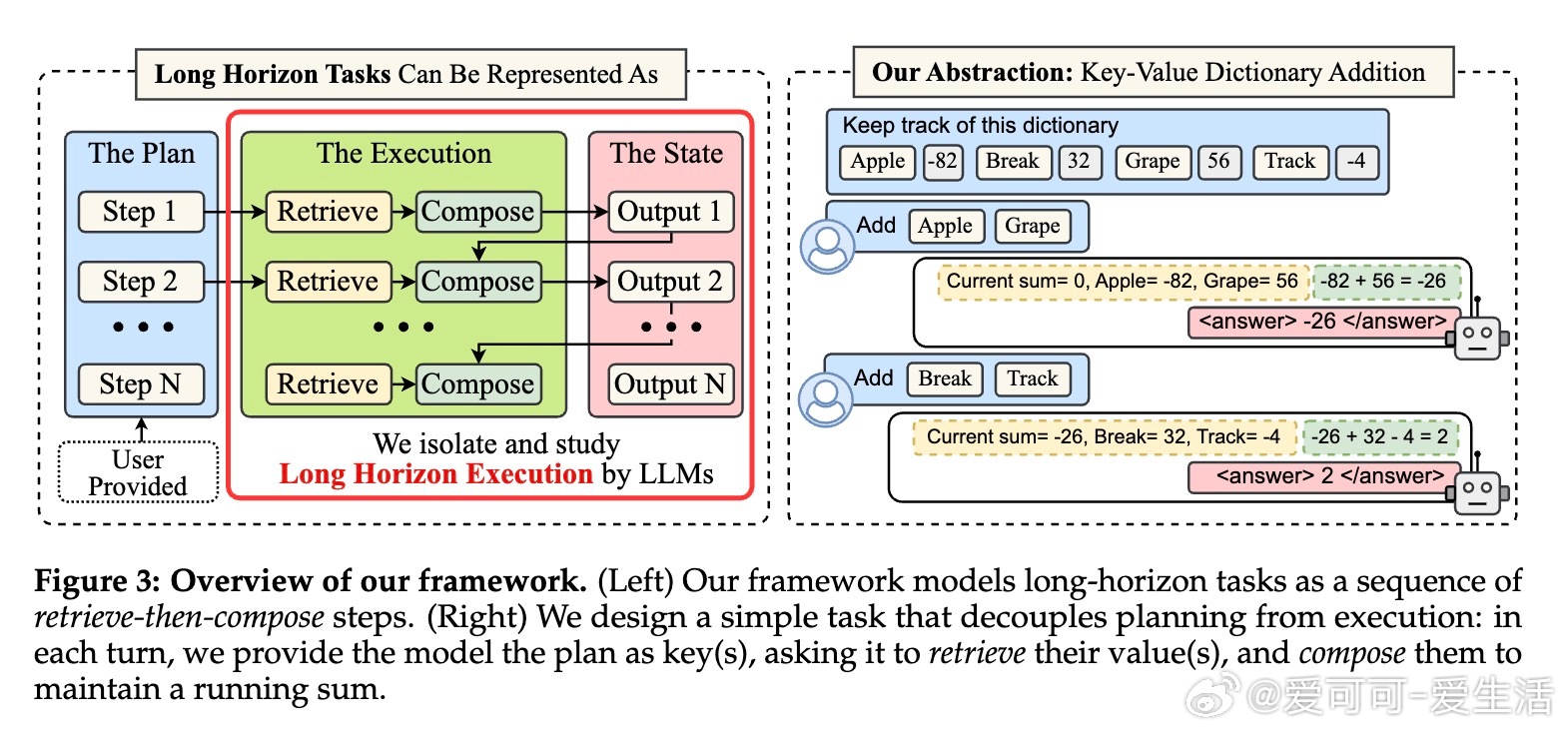
• 执行与规划解耦评测任务设计:通过retrieve-then-compose简化任务,避免知识和规划影响,纯粹测试执行稳定性,具有高度控制与可复现性。
心得:
1. 长任务性能退化主要源于执行错误及其累积,而非推理或知识缺失,提示未来优化应聚焦执行稳定性。
2. 模型自我条件效应揭示了输出依赖历史错误的恶性循环,挑战了传统认为大模型规模自动解决错误传播的假设。
3. Sequential test-time compute(顺序推理计算)远优于并行采样,强调推理前置对复杂任务成功至关重要。
完整研究及实验细节见🔗arxiv.org/html/2509.09677
大语言模型长任务执行模型规模链式思考人工智能