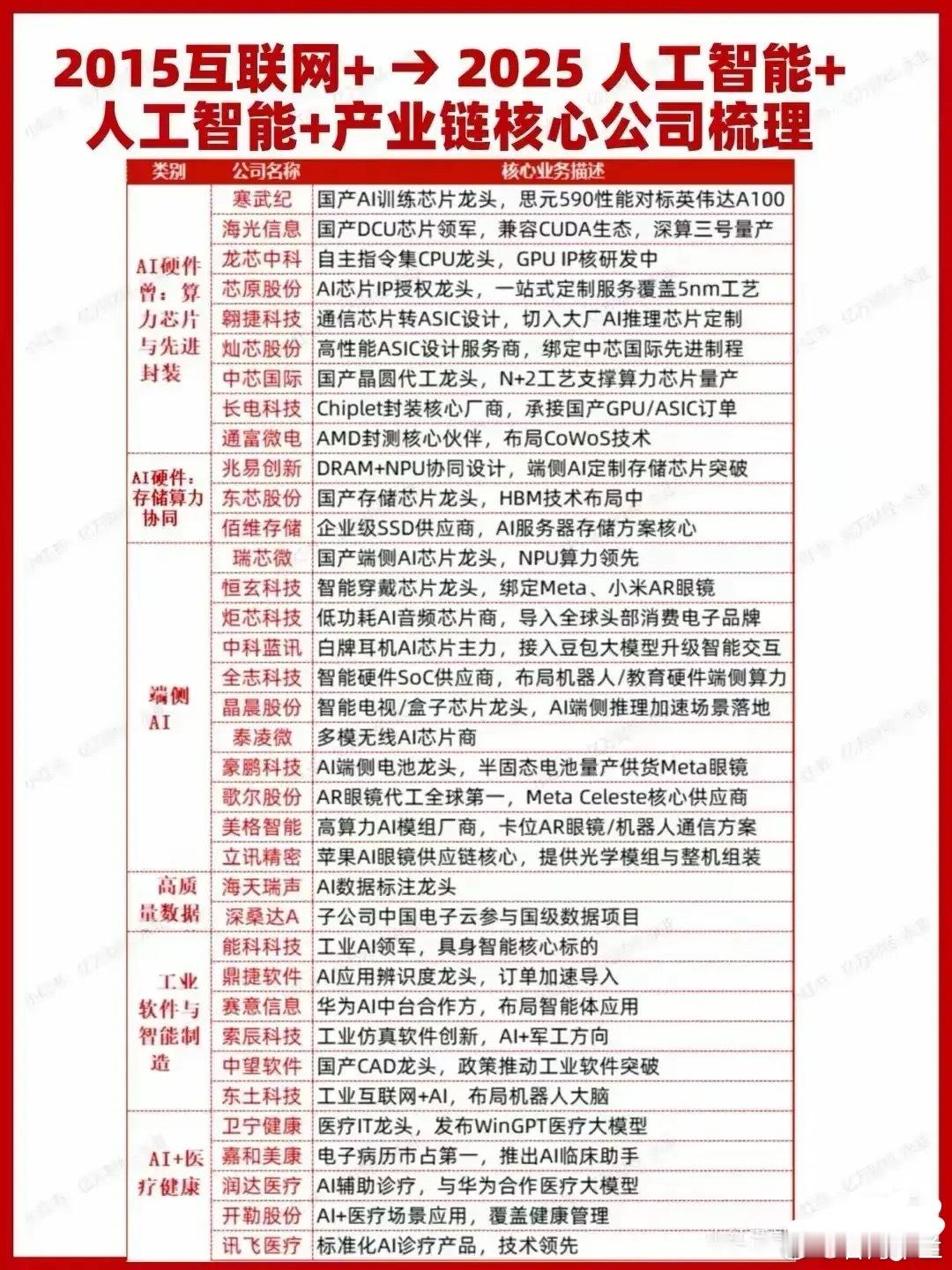
“中美差距究竟有多大?”DeepSeek创始人梁文峰再次语出惊人!他说:“我们经常说中国AI和美国有一两年差距,但真实的差距是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。” 当公众还在为“中国AI应用遍地开花”自豪时,梁文峰却撕开了这层光鲜外衣——从短视频推荐算法到刷脸支付,从智能客服到AI医疗诊断,中国AI的落地场景确实覆盖了14亿人的生活,但这些技术底座几乎都依赖海外开源框架。 就像中国能批量生产“吉他手”,却诞生不了“猫王”:当美国AI实验室在探索通用人工智能(AGI)的底层逻辑时,中国多数企业仍在用开源模型做“微调”。 这种差距在芯片领域尤为刺眼。2022年美国对华高端GPU禁售,本想掐断中国AI算力命脉,却意外催生了DeepSeek的“暴力优化”路线。通过重构模型架构和数据筛选机制,其R1模型将训练成本压至美国同行的三十分之一,性能却不相上下。这一案例看似励志,实则暴露了更深层困境:当被“卡脖子”时,中国AI的应对策略仍是“用更聪明的方式模仿”,而非创造新规则。 梁文峰将这种困境归结为“创新生态的缺失”。他以英伟达为例:这家芯片巨头之所以能主导AI算力市场,不仅因其硬件性能,更因其CUDA生态聚集了全球500万开发者,适配了3000多款专业软件。 反观中国,华为昇腾910B虽在算力上对标英伟达A100,但CUDA生态开发者规模仅为对方的1/25。这种“硬件追得上、软件跟不上”的悖论,让中国AI始终在“用别人的工具建自己的房子”。 人才断层进一步加剧了这种焦虑。尽管中国高校每年输出4万多名AI专业学生,但行业人才缺口仍超500万。更严峻的是,清华、北大等顶尖学府的毕业生流向美国科技巨头的比例长期高于30%。 而留存人才又普遍存在“重应用、轻基础”的倾向。梁文峰曾直言:“中国学术圈太看重短期利益,而原创需要‘浪费’的自由。”这种文化差异,导致中国在AI核心论文引用量上长期落后于美国。 但希望并非全无。DeepSeek的崛起证明,中国AI在特定领域已具备“反超”潜力。其R1模型上线后,GitHub星标数突破百万,直接冲击OpenAI的市场地位。 上海清华团队开发的AI医院,用42个“数字医生”实现单日3000人次诊疗,准确率超九成;杭州法院引入的AI法官,将简单案件处理效率提升一倍。这些案例揭示了一个真相:当美国AI仍在实验室打磨“完美模型”时,中国已通过海量场景迭代出更懂现实需求的技术。 这种“实战优势”正转化为新的竞争力。中国发电量占全球32%,西部电价低至0.3元/度,数据中心建设成本比美国低40%;AI相关专利占全球40%,应用场景覆盖制造、医疗、城市管理等十大领域。梁文峰将此形容为“人海战术”:“美国靠算法精妙取胜,中国用实战数据碾压——就像围棋对手抱怨你算力不足,你直接掀桌摆出五百盘实战棋谱。” 然而,这种优势能否持续?梁文峰的警告仍在回响:当芯片禁令迫使中国自研算力,当应用场景反哺底层创新,中国AI正站在“从学生到考官”的转折点。但原创力的培养无法速成,它需要容忍失败的学术环境、跨学科的人才储备,以及敢于“浪费”资源的产业政策。 DeepSeek的探索或许提供了某种启示:这家公司拒绝短期商业化,将70%资源投入基础研究;其核心团队多为本土培养的应届生,而非海外归国人才;他们坚持开源模型架构,认为“封闭式护城河在颠覆性技术面前不堪一击”。 这种看似“反常识”的策略,恰恰暗合了梁文峰的终极判断:中国AI的突围之路,不在于追赶参数规模,而在于重构创新规则。 当舆论还在争论“中美AI差距究竟几年”时,梁文峰已将问题指向更深层:我们是要继续做技术迭代的“优等生”,还是成为定义未来的“规则制定者”?这个选择,或许将决定中国AI在下一轮科技革命中的站位。 那么,对于这件事,大家有什么看法?