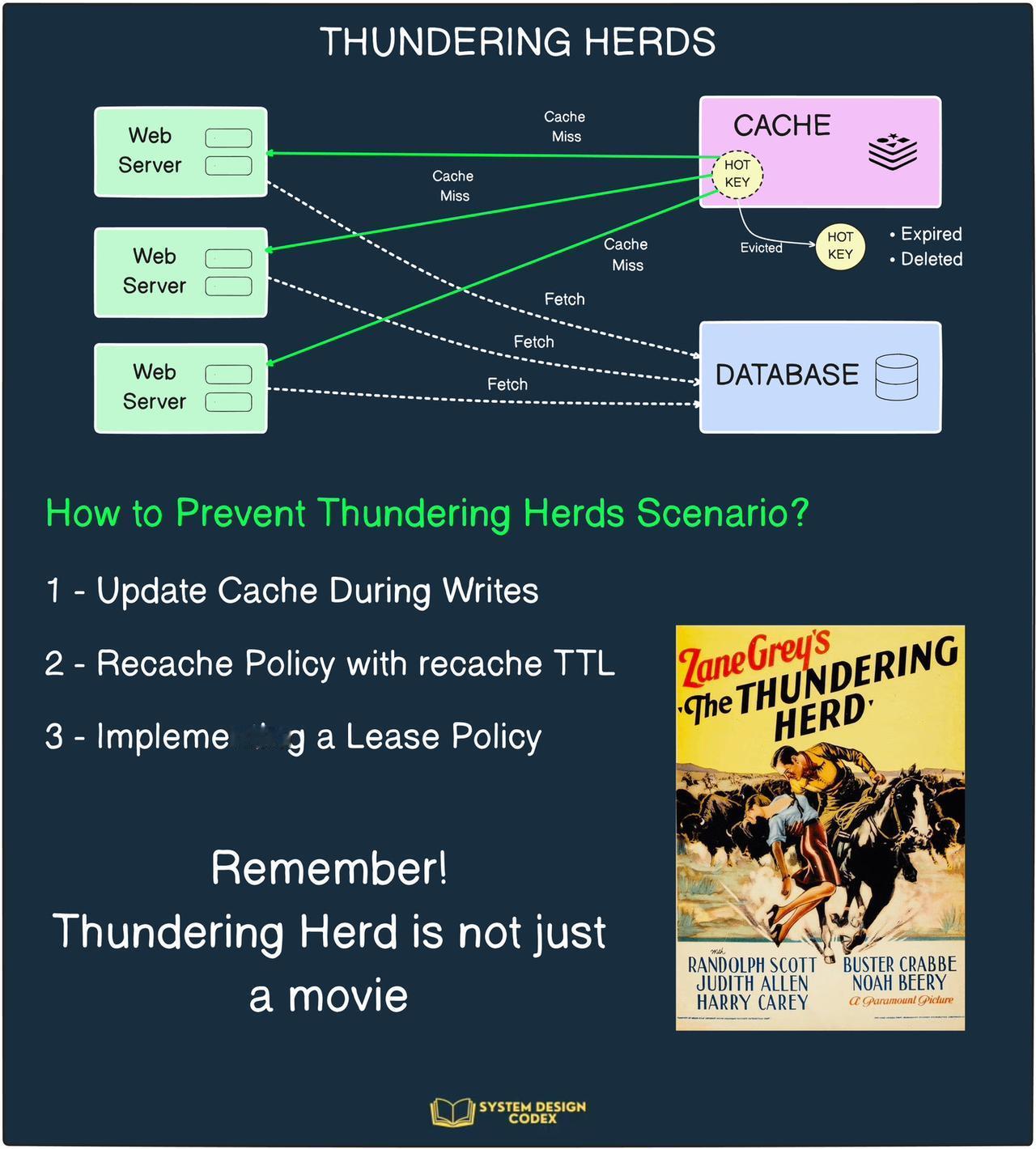
如您正在使用缓存,则需要防范惊群效应。但是,惊群效应的成因是什么呢? 当缓存中的非常热门的键过期或被删除时,就会触发此问题。 所有尝试同时访问此热键的服务器都将发生缓存未命中。 并且它们都会同时尝试从后端获取值。 结果: - 负载大幅飙升 - 延迟增加 - 连锁故障可能导致系统瘫痪 如何防止惊群效应呢? 有以下几种方法: ✅写入期间更新缓存 在尝试维持缓存一致性时,经常会发生惊群现象。 例如,热键在 DB 中使用新值进行更新,并在缓存中失效。 除了使其无效之外,您还可以更新缓存中的键值,从而防止发生惊群效应。 当然,与删除相比,更新操作可能成本更高。 ✅具有重新缓存 TTL 的重新缓存策略 另一个解决方案是确保只有一个 Web 服务器查询后端并填充缓存。 如何? 通过使用重新缓存策略。 - 每个 GET 缓存请求都包含一个带有重新缓存 TTL(比如 10 秒)的重新缓存策略。 - 如果键的剩余 TTL < 重新缓存 TTL,则一个 Web 服务器获胜、未命中并重新填充缓存中的值。 - 其他 Web 服务器(又称“失败者”)在此期间继续提供陈旧数据。 这就像是对惊群效应的先发制人打击。 ✅实施租赁政策 当发生缓存未命中时,缓存实例会将租约提供给特定的 Web 服务器。 租约就像是获取数据并将其设置到缓存中的权利。 只有获得租约的 Web 服务器才会从数据库获取最新值并将其更新到缓存中。 当然,在这种情况下,“失败者”的网络服务器没有过时的数据可提供。 因此,他们必须重试。 那么,您对这些方法有何看法? 您还有其他可行的方法吗?#程序员 #软件开发 #人工智能 #计算机 #编程严选网