今日,混元世界模型1.1版本(WorldMirror)正式发布并开源。该版本新增了对多视图及视频输入的支持,且单卡即可完成部署,能在秒级内创造3D世界。它将3D重建技术从专业工具转变为人人可用的技术,使任何人都能在秒级内通过视频或图片创造出专业级的3D场景。

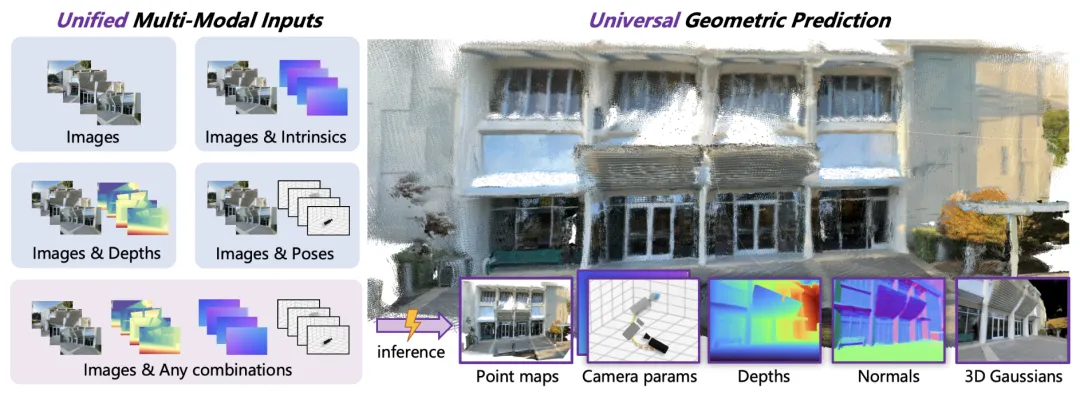
今年 7 月,腾讯推出了混元世界模型 1.0,这是行业里第一个开源且能和传统 CG 管线兼容的可漫游世界生成模型,它的 lite 版本在消费级显卡上就能部署。混元世界模型 1.1 作为一个统一(any-to-any)的前馈式(feedforward)3D 重建大模型,突破了 1.0 版本仅支持文本或单图输入的限制,首次实现了多模态先验注入和多任务统一输出的端到端 3D 重建。并且,混元世界模型 1.1 还支持相机、深度等更多模态的先验输入,基于统一架构完成点云、深度、相机、表面法线以及新视角合成等多种 3D 几何预测,性能远超现有方法。
灵活的输入处理(any input)
传统3D重建方法仅能处理原始图像,难以利用现实应用中常见的额外信息。混元世界模型1.1创新性地引入了多模态先验引导机制,支持灵活的先验注入:
相机位姿:提供全局视角约束,确保多视图一致性。
相机内参:解决尺度歧义问题,精确投影几何关系。
深度图:为纹理缺失区域(如反光面、无纹理区)提供像素级约束。
系统采用分层编码策略:将紧凑先验压缩为全局语义令牌,而稠密先验则以空间对齐的方式融合进视觉特征。通过动态先验注入机制,模型能够灵活适应任意先验组合——有则用之,无则自适。
通用的3D视觉预测(any output)
以往的方法通常为单一任务定制,要么生成点云,要么估计深度,要么预测相机位姿。混元世界模型1.1首次实现了统一,并在各项任务上均取得了SOTA(State-of-the-Art)的表现:
点云:实现密集点云回归。
多视角深度图:进行逐像素深度估计。
相机参数:预测完整的位姿和内参。
表面法线:支持高质量网格重建。
3D高斯点:直接用于实时新视角渲染。
通过端到端的多任务协同训练,各任务相互强化。例如,预测的法线图在Poisson表面重建中能够产生更清晰的网格细节,而深度和相机约束则互相校准,提升整体几何一致性。
单卡部署与秒级推理
与需要迭代优化的传统方法(可能耗时数分钟甚至数小时)不同,混元世界模型1.1采用纯前馈架构,在单次正向传播中直接输出所有3D属性。处理典型的8-32视图输入,本地耗时仅需1秒。
架构设计
1.多模态先验提示(Multi-Modal Prior Prompting)
针对不同先验,系统采用了专门化的编码策略。相机位姿和内参经由 MLP 投影为单一令牌;深度图则借助卷积核生成与视觉特征空间对齐的密集令牌,并直接与之相加。这种异构融合方式,在保障全局约束稳定的同时,也保留了局部几何信息的细节。借助动态注入和随机组合训练机制,模型可灵活应对任意先验组合,甚至无先验的输入场景,从而实现对复杂真实环境的稳健解析,显著提升三维结构的一致性与重建质量。

2.通用几何预测架构(Universal Geometric Prediction)
混元世界模型1.1以完全的Transformer架构为骨干,采用DPT头进行点云、深度、法线等密集属性的预测,并利用Transformer层来回归相机参数。对于3D高斯点(3DGS),系统直接预测高斯点的位置和属性,并通过可微分光栅化器进行监督学习。通过端到端的多任务协同训练,该模型在结构精度、渲染保真度以及跨任务泛化能力等方面均显著优于现有技术,为通用三维世界建模提供了新的技术基础。
图:法向估计帮助更好的表面重建效果

3.课程学习策略(Curriculum Learning)
训练分三个维度递进:任务顺序(先学基础几何,再学表面属性,最后学3DGS)、数据调度(先用多样化数据,再用高质量合成数据)、分辨率渐进(从低到高)。这套策略将单一图像分布外的泛化能力最大化。
注:文章转载自腾讯混元公众号