随着大模型能力的快速提升,Test-Time Scaling 已成为推动大模型能力增长的关键手段。与此同时,对更长上下文推理的需求以及对更高训练/推理效率的追求,已成为大模型开发和应用中不可忽视的重要因素。为此,我们将高稀疏比的MoE 结构与混合线性注意力相结合,基于 Ling 2.0 打造出了极致高效的Ling 2.0 Linear 混合架构,并在前期的研发和探索过程中,充分验证了这一架构的显著优势。值得一提的是,凭借架构优化与高性能算子的协同作用,该模型在深度推理场景下的推理成本仅为同尺寸 Dense 模型的 1/10,与原有的 Ring 系列相比,成本也降低了超过50%,在追求效果提升的同时,实现了对效率的极致优化。
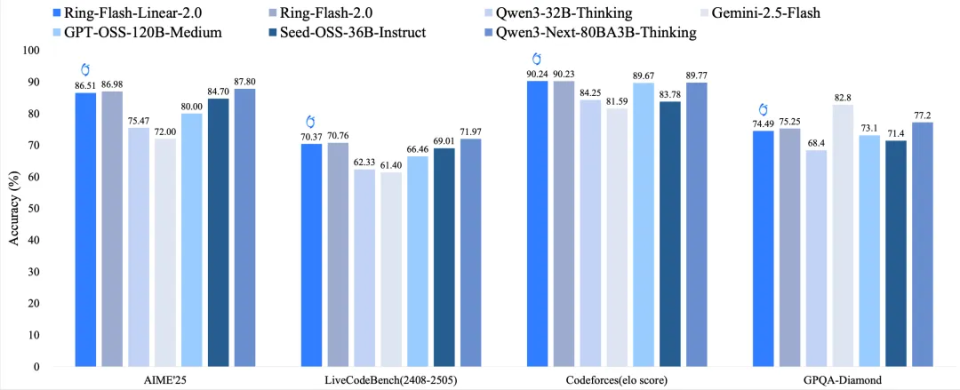
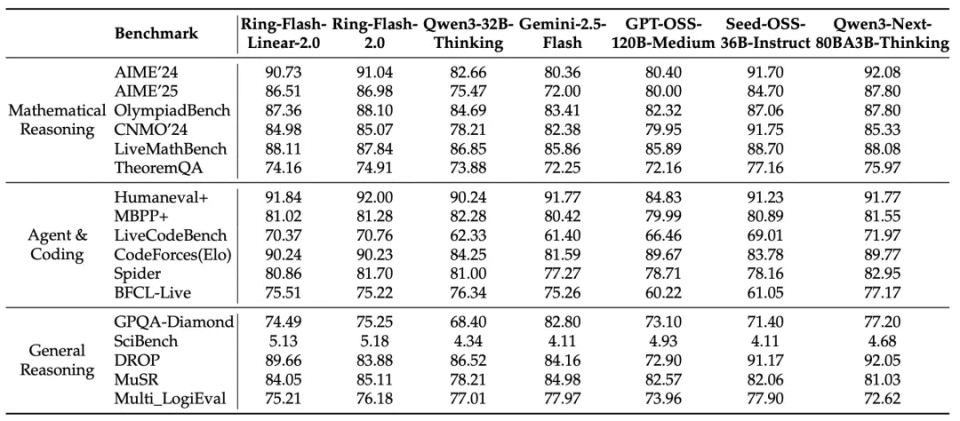
今天,我们进一步开源了该系列模型的升级版本Ring-flash-linear-2.0-128K。相较于之前的Ring-flash-linear-2.0版本,我们将其上下文窗口进一步扩展至128K,并通过 SFT 与强化学习的稳定训练,使模型在各项高难度复杂推理任务上均达到了 SOTA 表现。与之前的 32K 模型版本相比,Ring-flash-linear-2.0-128K更适合用于超长文本的代码编程以及 agent 等场景。

Ling 2.0 Linear 架构融合了线性注意力和标准注意力机制,通过提高线性注意力的占比,使模型具有近线性计算复杂度,在高并发和长上下文场景下,能显著降低模型训练和推理的计算成本。我们经过系统性实验对线性注意力层进行了多项改进,实验结果表明,这些改进能够提升训练的稳定性并增强模型的外推效果。Ling 2.0 Linear 架构沿用了 Ling 2.0 的架构设计,凭借 1/32 的专家激活比、MTP 层等优化,实现了七倍以上的架构性能杠杆。概括来说,Ring-flash-linear-2.0 仅以 6.1B 激活,可以媲美 40B 以下的 dense 模型架构。
为了进一步提高模型的训练和推理效率,我们通过精细化的算子融合和自适应重计算量化技术,研发了更高效的 FP8 融合算子,极大地提升了 FP8 混合精度训练的计算效率。
在推理端,我们完成了在 SGLang 和 vLLM v1 等框架上的适配,并开发了更高效的线性 attention 融合算子,支持更多推理模式,从而进一步提升了推理引擎的吞吐量。
训练流程
Continued Pre-Training
该阶段首先复用 Ling-flash-base-2.0-20T 的模型参数,将每 8 层 softmax 注意力层中的 7 层替换为线性注意力层,并在4K长度下加训了1T token,以恢复模型的原始能力。进一步地,我们在Mid-training阶段,将模型的上下文窗口逐步从 4K 扩展至 32K,最终扩展至128K,同时提升推理类语料的质量和占比,为后续 Post-Training 阶段打好基础。经过这一过程,我们从 Ling-flash-base-2.0 的基础模型出发,以相对低成本的方式,完成了到 Ring-flash-linear-2.0-128K 基础模型的过渡和适配。
Post-Training
Post-Training阶段主要包括SFT和RL两个阶段的训练。SFT阶段承接前序训练流程,以128K的窗口进行训练。数据上兼顾高难度推理与通用知识,覆盖数学、编程、科学、创作、医学等多领域。此外,为防止过拟合并便于后续RL训练,我们选择了较早的模型checkpoint用于后续的RL阶段。
RL 阶段以足够的窗口长度(如64K)进行训练,以做到效果的充分释放和效率的兼顾。我们注意到,在较高难度的训练数据下,以更小的窗口(如32K)进行训练会面临高截断率和低上限的潜在痛点,而以足够的窗口长度进行训练是更好的选择,截断率基本可以忽略,且训练达到的效果上限更高。要特别强调的是,为保障RL的长期且稳定训练,我们系统性的解决了RL 训推差异的问题,从相同逻辑实现、保持合适精度、消除不确定性三个方面来对齐训练和推理框架,对KV Cache、LM_Head、RMSNorm、RoPE、Attention、MoE等关键模块均进行了训推对齐。基于此,算法上就无需做任何额外修改,整个RL训练阶段便可以平稳运行,并带来模型效果的突破。
注:文章转载自百灵大模型微信公众号