Ming-omni 家族再升级!首发千亿级开源全模态大模型 Ming-flash-omni-Preview,依托 Ling 2.0 稀疏 MoE 架构,总参 103B、激活仅 9B。相较人气款 Ming-lite-omni-1.5,新模型全模态理解与生成全面跃升,综合性能稳居开源榜首,可控图像生成、流式视频解析与语音识别尤为亮眼。
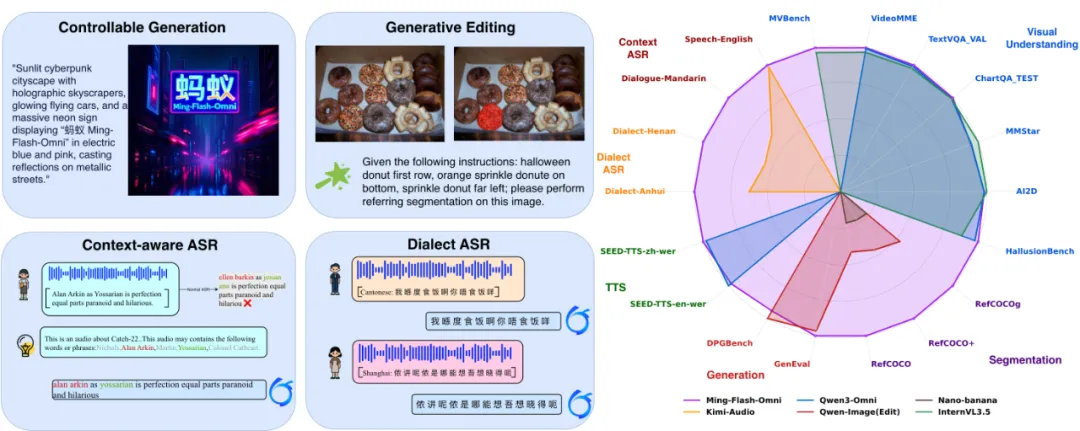
能力一览
可控图像生成
在图像生成这一高频场景,Ming-flash-omni-Preview 率先提出“生成式分割”新范式,把传统“图像分割”改写成语义不变的编辑任务(Generative Segmentation-as-Editing),从而做到像素级空间语义精准操控。该模型于 GenEval 基准斩获 0.90 分,力压全部非强化学习生成方案,可控性表现一骑绝尘。
流式视频理解
很多用户希望 AI 能围绕真实场景与自己持续对话,并即时解读眼前所见。Ming-flash-omni-Preview 恰好满足这一诉求:如下方视频所示,它对流式视频进行逐帧级细粒度理解,识别画面中的物体与交互行为,同步给出贴合语境的解说,让用户在真实环境里随时获得即时、准确的智能支援。
语音及方言理解
Ming-flash-omni-Preview 支持上下文感知语音识别(ContextASR)与方言辨识,在全部 12 项 ContextASR 子任务刷新 SOTA;针对湖南、闽南、粤语等 15 种地方口音,识别精度显著提升,为“听不懂”的方言场景提供即时转译与实时释意,让用户不再因方言迷路。
音色克隆
Ming-flash-omni-Preview 将语音生成由离散 tokenizer 升级为连续 tokenizer,音色克隆表现大幅跃升,中英混读保持稳定,可把原对话音色精准迁移至新生成内容,seed-tts-zh WER 仅 0.99,优于 qwen3 omni 与 seed-tts。
模型架构及能力简介
Ming-flash-omni-Preview 的模型结构图
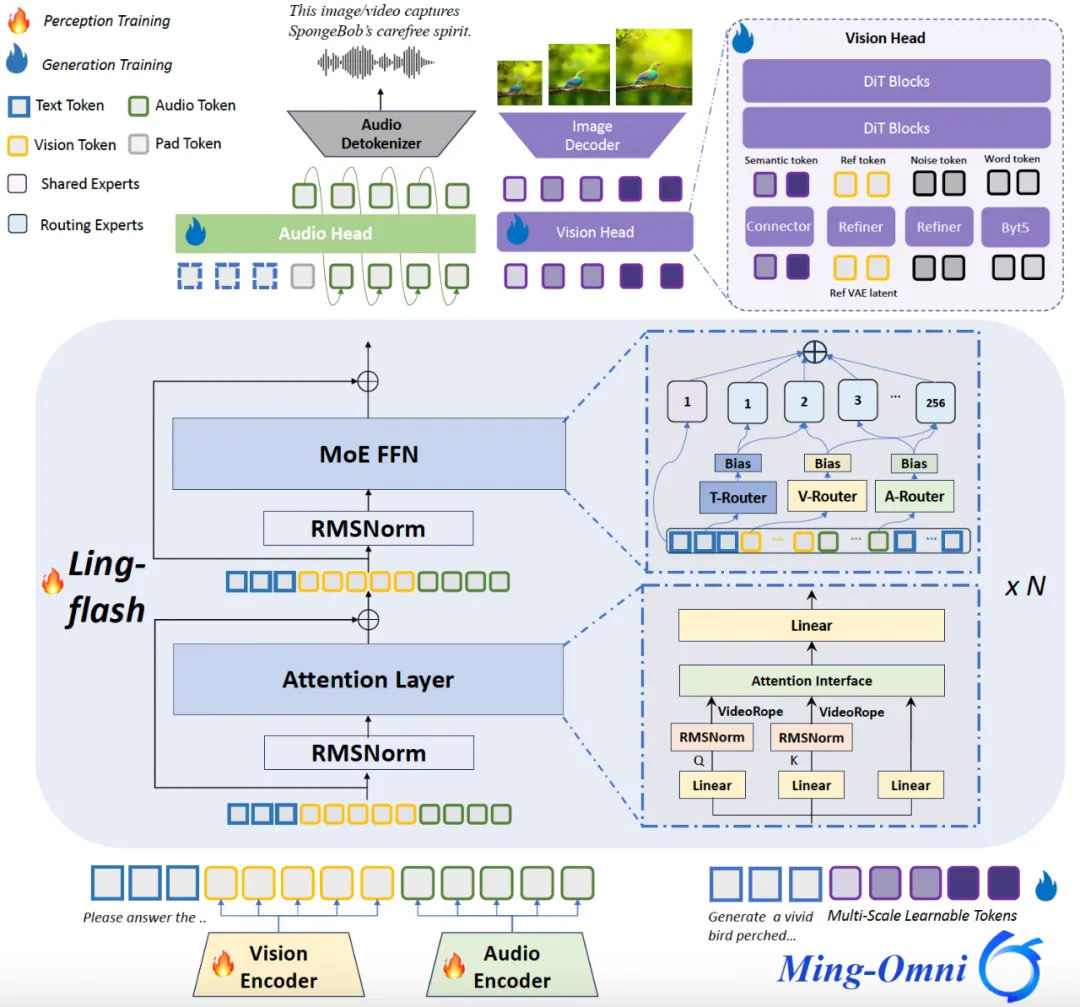
1) 基于稀疏专家架构的全模态训练
Ming-flash-omni-Preview 把 Ling-flash-2.0 稀疏 MoE 框架延伸至全模态,沿用 Ming-lite-omni 提出的模态级路由,对各模态的数据分布与路由概率联合建模,做到“容量大、激活少”。通过在 Attention 层植入 VideoRoPE,强化长视频时空关联,显著升级视频交互体验。训练侧配套双重策略:
稳定稀疏训练——混合专家均衡方案(辅助负载损失+路由器偏置更新)保证稀疏 MoE 全模态训练既均匀又收敛;
上下文感知 ASR——将任务/领域信息作为解码条件,专有名词识别与转录一致性大幅提升;同时注入高保真方言语料,湖南、闽南、粤语等 15 种地方话识别准确率全面跃升。
2)生成式分割编辑一体化
打造统一多模态模型时,最难的是把图像“看得懂”与“画得出”高效拧成一股绳。Ming-lite-omni-1.5 的做法是冻结语言通路,用多尺度 QueryToken 把层级语义灌进去,理解指标稳住了,生成也能搭便车。然而理解跟生成的优化方向天生不同,再精细的层级语义也搬不动物体属性、空间关系这类细粒度视觉知识,生成质量与可控性依旧撞墙。
为此,Ming-flash-omni-Preview 抛出“生成式分割即编辑”的协同训练框架:把分割改写成语义守恒的编辑任务——例如“把香蕉变紫”。这一招强行把理解与生成目标拧成同一根绳:想改得准,必须先精准定位轮廓;改得好,反过来又给理解送上一股高纯度监督。细粒度时空语义控制由此被直接拉满,文本生成里的组合性难题也被顺带缓解。
GenEval 上,模型拿到 0.90 分,横扫全部非 RL 方案;GEdit 里,删物、换物等细活平均分从 6.9 涨到 7.9。两组数字共同盖章:用“生成式分割即编辑”练出的像素级时空控制力,不仅把精准编辑抬上新台阶,还无缝迁移到纯文本驱动的图像生成战场。
3) 高效全模态训练架构
训练全模态基座模型时,横亘着两大障碍:数据异构——各模态输入尺寸千差万别;模型异构——专用编码器难以并肩作战。二者合力造成负载失衡、内存碎片与流水线空泡,训练效率被大幅拖慢。
为此,我们在 Megatron-LM 底座上为 Ming-flash-omni-Preview 引入两项核心改进:
序列打包 (Sequence Packing):解决数据异构性。将变长序列密集打包成定长批次,大幅提升内存利用率和计算密度;
弹性编码器分片 (Flexible Encoder Sharding):解决模型异构性。扩展 Megatron-LM 支持模态编码器在 DP/PP/TP 上的细粒度分片,消除流水线气泡,实现负载均衡。
这些优化措施使 Ming-flash-omni-Preview的训练吞吐量比基线提升了一倍。
注:文章转载自百灵大模型公众号