前言:
多年前出现一个diy圈子里面出现一种特殊内存,叫做AMD专用内存,这东西是从利用报废服务器内存颗粒和AMD平台的技术宽容性,以极低的价格满足了部分老AMD平台用户升级或组装低价主机的需求。稳定性可靠性不高。
真正意义的AMD专用内存,其实应该是从AM5接口开始,AMD出台的EXPO,与Intel的XMP相比,AMD的EXPO走的是另外一条路。XMP侧重「高频带宽释放」,适配Intel酷睿的缓存架构;EXPO侧重「内存延迟控制」,贴合AMD Ryzen处理器的内存控制器特性。
简单来说,AMD平台内存看重的是时序,而不是频率。其中,DDR5 6000 CL28可以说AMD平台的甜点,今天给大家分享一款来自科摩思的CL28高性能内存,并且通过测试给大家解答一下,为什么AMD平台更看重低时序。

科摩思总部位于深圳,2011年成立,是一家深耕存储芯片领域的国家级专精特新小巨人企业。

一、核心参数与硬件架构

1.颗粒与频率:海力士 A-die 的超频基因

承影机甲全系采用海力士原厂 A-die 颗粒(部分批次为 M-die),这是目前公认的超频性能最强的 DDR5 颗粒之一。以 6000MHz CL28 版本为例,其默认 XMP/EXPO 频率下时序为 C28-36-36-73,电压 1.4V;而 6800MHz 版本则为 C34-45-45-108,电压 1.45V。实测中,6000MHz 版本可轻松超频至 8200MHz(C36-48-48-128),读取速度突破 119GB/s,延迟压至 55.3ns,较默认频率性能提升 30% 以上。

2.散热设计:1.5mm 厚马甲的效能突破

采用 CNC 切割 + 氧化工艺打造的1.5mm 厚金属散热片,实测在8200MHz高频运行时,内存温度稳定在 55℃以内(环境温度 25℃),较无散热片产品降温15℃以上,确保长时间高负载下的稳定性。
3.兼容性与协议支持:双平台一键超频

同时兼容 Intel XMP 3.0 和 AMD EXPO 双协议,主流主板(如华硕 Z790、微星 B760M 迫击炮、AMD X670E)可一键开启预设超频档位,无需手动调整参数。尤其适配 AMD Zen4 架构—— 在锐龙 9 7950X 平台上,6000MHz CL28 版本可稳定运行,FCLK 频率同步至 3000MHz,实现内存性能最大化。
二、AMD平台低时序需求深度解析:为何时序比频率更关键?
1.架构根源:Infinity Fabric 总线的延迟敏感特性

AMD Ryzen 系列处理器的核心互联依赖Infinity Fabric(无限结构)总线,这条 “内部数据高速公路” 的频率(FCLK)与内存控制器频率(UCLK)、内存颗粒频率(MCLK)存在理想的 1:1:1 同步关系。当内存时序过高时,即使频率达标,也会直接拖慢总线数据传输效率:

以 Zen4 架构的锐龙 9 7950X 为例,搭配 6000MHz CL36 内存时,FCLK 虽能同步至 3000MHz,但内存延迟高达 89ns;换用科摩思承影机甲 6000MHz CL28 版本后,延迟降至 77.7ns,Infinity Fabric 数据吞吐效率提升 13%。
若强行追求 7200MHz 高频但时序放宽至 C40,会导致 FCLK 与 MCLK 被迫切换为 1:2 分频(FCLK 1800MHz),总线速度腰斩,反而出现游戏掉帧问题。
2.性能瓶颈:AMD 内存控制器的优化方向

与 Intel 侧重高频高带宽的策略不同,AMD 内存控制器更追求 “高效能低延迟”。Zen 架构内存控制器的原生延迟高于 Intel,低时序成为弥补这一差距的关键:
实测对比:在锐龙 7 9800X3D 平台上,承影机甲 6000MHz CL28(延迟 76.8ns)较同频率其他品牌CL34 内存(延迟 85.2ns),《CS2》1% Low 帧提升 18%,Blender 渲染速度快 9%。
颗粒优势:海力士 A-die 颗粒的低时序潜力,使其能在 6000MHz 频率下稳定运行 CL26-34 时序,延迟进一步压至 75ns 以内,完美契合 AMD 平台的优化需求。
3.EXPO 协议的适配价值

AMD EXPO 协议的核心是 “高频 + 低时序” 的预设组合,科摩思承影机甲的 6000MHz CL28 版本正是为此设计:
一键开启 EXPO 后,内存自动加载优化时序与电压参数,无需手动调试即可实现 “频率 6000MHz + 延迟 < 80ns” 的甜点性能。
对比手动超频:EXPO 预设的时序参数(C28-36-36-73)经过原厂验证,在锐龙平台的稳定性优于自行压缩时序,适合非专业玩家。当然了,一般用户并没有时间和能力去满满调试,所以我们直接选择科摩思的CL28低时序内存就省力省心了。
三、性能实测与场景表现
1.理论性能:突破 100GB/s 的读写天花板
相比于理论和架构分析这些枯燥的文字分析,我们还是更加乐意看到实际数据。理论必须有实践数据作为支持,手上的平台不算强大,但也足够给大家体现出低延迟带来的性能提升。




具体平台如下:
CPU:AMD 7600X
主板:技嘉X760
内存:科摩思承影机甲DDR5 6000 CL28
显卡:影驰RTX2060 super

科摩思 DDR5 6000支持AMD的EXPO,直接在bios里面打开即可实现CL28低时序。
下面,我们就来看看CL28时序性能。

测试前,我们先来检测一下科摩思DDR5的工作状态。在BIOS里面打开了EXPO后,内存工作在6000MHz频率,时序为28-36-36-73。对于Intel用户来说,打开XMP也是可以实现这个最佳时序的。
其他方面的信息,我们可以看到,内存颗粒来自于海力士,而且还是特挑的A-die颗粒,超频潜力更强。
下面,我们开始测试,通过基准测试、游戏测试对比。
1、CPUZ多核多线程基准测试
CPUZ主要的作用是检测CPU以及内存信息的,里面提供的基准测试有一定的参考价值,但不多。

CPUZ的多核多线程测试中,C28时序的成绩是5886。
1、AIDA64 内存性能测试
AIDA64是一个综合性检测软件,而且还是一款内存性能测试与轻量级别硬件稳定性测试。
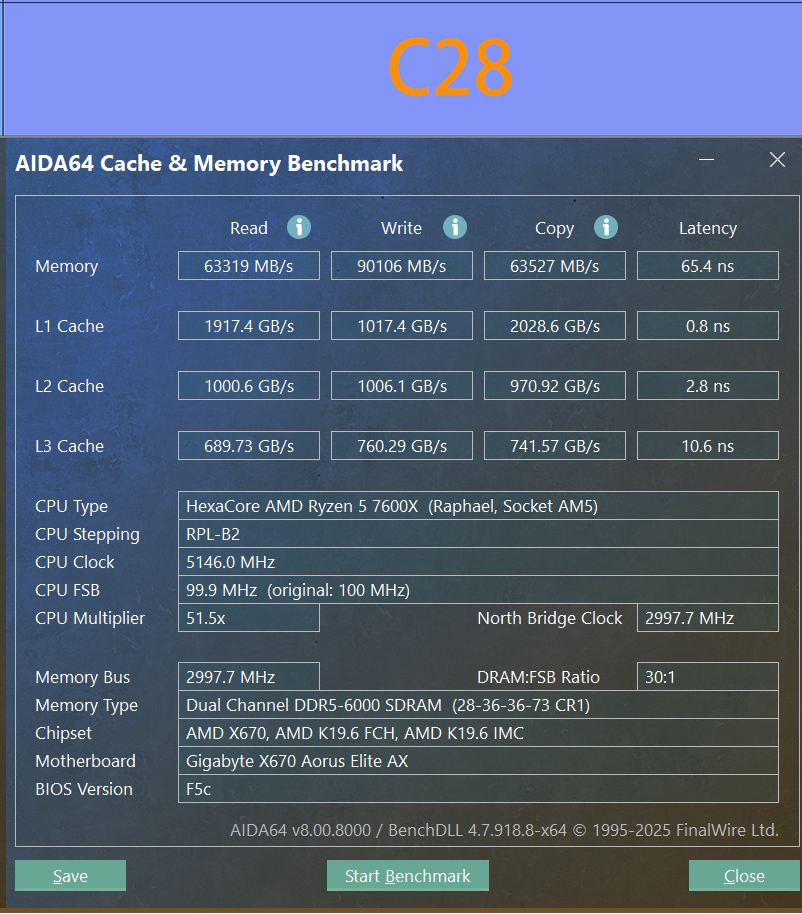
AIDA64内存测试内存内存读取性能,C28时序的成绩是63319MB/s。
1、SuperPI 单核浮点性能与内存性能测试
虽然是上古的测试软件,但是严谨性还是足够的,尤其是对于内存频率、时序变化的测试,还是有非常好的参考意义的。

以前跑百万位测试的对于内存差距体现不会太明显,我们玩高级一点的。
superPI 八百万位测试,C28时序的成绩是1分3秒735,这个已经非常不错了。
1、3DMARK 图形、CPU多项性能测试

3DMARK CPU性能测试中,C28时序的成绩是7243。

DX11图形性能测试,C28时序的成绩是10758。
1、古墓丽影11 DX12游戏测试

我手上的显卡只能说和主流的RTX4060差距不大,但毕竟性能有限,而且要体验内存性能的话,低分辨率下面反而明显一点,毕竟4K分辨率、光线追踪全开的话,基本上就没CPU和内存的事情了。
同样的6000MHz频率下面,C28时序是139帧。
也就是说,在显卡负载不高,比方说电竞游戏方面,低时序能带来的游戏帧数提高也是非常直观的。
1、黑悟空benchmark

黑悟空这个IP相信就不用介绍了,毕竟这可是给国内游戏长脸的事情。在新的3A大作下面,我的显卡瓶颈就很明显了,高时序和低时序的帧数仅仅差了1帧,完全可以忽略。
小结一下测试,3A游戏大作还是显卡说了算,低时序带来的更多是加载、读档时候速度提高,帧数几乎没有变化。倒是电竞游戏的帧数提高明显一点,也更加流畅。

视频剪辑方面,无论是剪映还是达芬奇,都能明显体现到低时序带来的响应速度提高,如果手上有RTX4080级别显卡的朋友,可能低时序带来的性能收益会更加明显。
总结:

由于AMD平台的特殊性,低时序对于性能提升的红利高于高频率。而低时序反而更加难以调整,毕竟涉及到的是四个小参而不是单纯拉频率。

事实上。现在内存超频已经变得不容易,现在的内存不大吃电压,拉高了频率,要是时序差一样是白搭。
相比而言,科摩思直接采用特挑海力士颗粒,直接出厂实现低时序的方案更加方便好用。低时序给整机的性能带来3%-8%左右的小幅度提升,带来更高的内存带宽以及更快的响应速度。而且由于是出厂调校的,稳定性和可靠性更加高。