
要让 AI 真正读懂、预判并重塑现实,“世界模型”已成下一代智能的点火钥匙。它把物理规则、时空流转与场景因果揉成一套可演算的数字镜像,让机器首次拥有“透视”世界如何运转的瞳仁。而视频生成,被视作锻造这把钥匙的最快钻头——在逐帧压缩几何、语义与动力学知识的过程中,AI 得以在硅基空间里先彩排一遍现实,再反向优化决策。
瞄准这一靶心,美团 LongCat 团队推出 LongCat-Video:一枚统一权重即拿下文生、图生双赛道开源 SOTA 的视频引擎。团队以“续写式”预训练喂饱模型,使其一口气连贯吐出分钟级长片,跨帧时序锁死,物理运动不崩,专治长视频散架顽疾。
凭借对真实世界运行态的高保真复刻,LongCat-Video 成为美团叩开世界模型之门的第一块基石,也为后续自动驾驶、具身智能等重交互业务预埋好技术炸药。

统一模型架构:多任务一体化视频基座
作为以 Diffusion Transformer(DiT)为基座的统一视频生成底座,LongCat-Video 用“条件帧数”一把尺子划清任务边界:零帧即文生,单帧成图生,多帧接力做续写。三大场景同权重共生,无需外挂分支,天然闭环“文-图-续”全链路。
文生视频:可生成 720p、30fps 高清视频,能精准解析文本中物体、人物、场景、风格等细节指令,语义理解与视觉呈现能力达开源 SOTA 级别。
图生视频:严格保留参考图像的主体属性、背景关系与整体风格,动态过程符合物理规律,支持详细指令、简洁描述、空指令等多类型输入,内容一致性与动态自然度表现优异。
视频续写:视频续写是LongCat Video的核心差异化能力,可基于多帧条件帧续接视频内容,为长视频生成提供原生技术支撑。
长视频生成:原生支持5分钟级连贯输出
凭借视频续写式预训练、Block-Causal Attention 与 GRPO 后训练的三板斧,LongCat-Video 一口气稳定输出 5 分钟超长画面,零掉帧、零掉质,稳居行业头把交椅;同时把色彩漂移、画质衰减、动作断裂等顽疾掐灭在源头,跨帧时序锁死,物理运动顺滑,为数字人、具身智能、世界模型等长时动态模拟场景提供“稳态时空引擎”。 模型还引入块稀疏注意力(BSA)+ 条件 token 缓存双刀流,削去长序列推理冗余——哪怕 93 帧起步,也能画质与速度两手抓,彻底捅破“时长越长,质量越差”的天花板。
高效推理:二阶段生成+稀疏注意力+模型蒸馏优化
针对高分辨率、高帧率视频生成的计算瓶颈,LongCat-Video 通过 “二阶段粗到精生成(C2F)+ 块稀疏注意力(BSA)+ 模型蒸馏” 三重优化,视频推理速度提升至10.1倍,实现效率与质量的最优平衡:
二阶段粗到精生成(C2F):先生成 480p、15fps 低分辨率视频,再经 LoRA 精调模块超分至 720p、30fps,在降本提效的同时优化画面细节;
块稀疏注意力(BSA):将 3D 视觉 token 分块后,仅选取 top-r 关键块计算注意力,使计算量降至标准密集注意力的 10% 以下;支持稀疏注意力适配并行训练,进一步提升大模型训练与推理效率;
模型蒸馏优化:结合 Classifier-Free Guidance(CFG)与一致性模型(CM)蒸馏,将采样步骤从 50 步减至 16 步。

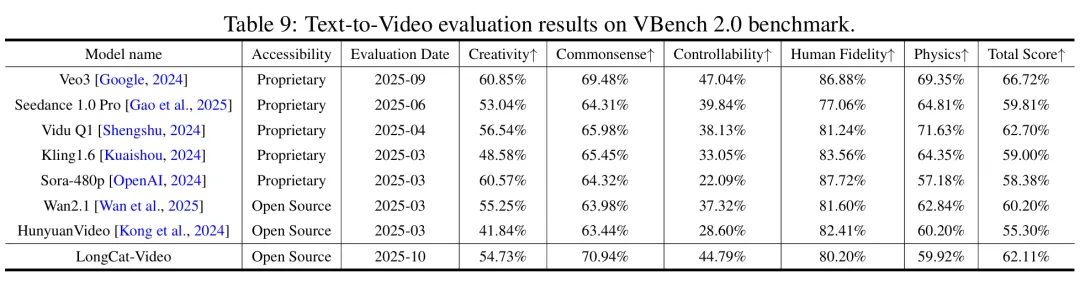
LongCat-Video 的模型评估围绕内部基准测试和公开基准测试展开,覆盖 Text-to-Video(文本生成视频)、Image-to-Video(图像生成视频)两大核心任务,从多维度(文本对齐、图像对齐、视觉质量、运动质量、整体质量)验证模型性能:
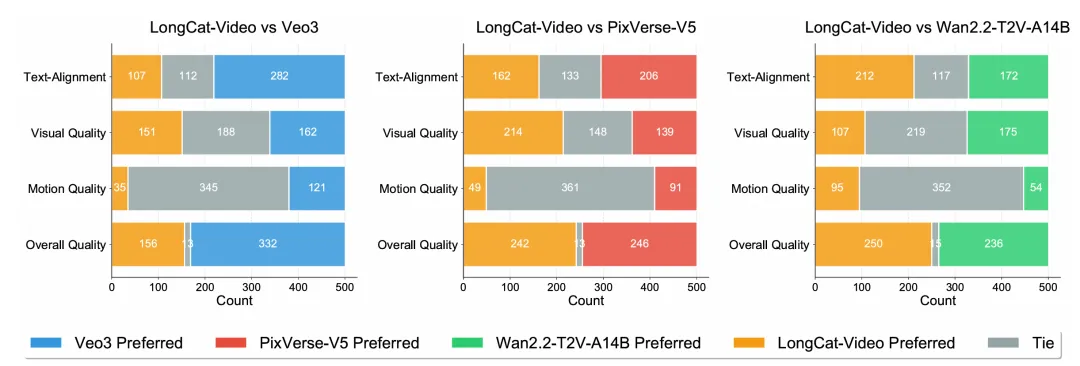
全面测评结果印证,LongCat-Video 通用战力拉满,稳稳站上开源顶流:
136 亿参数的生成基座,无论文生还是图生,综合分数均刷新开源榜;
围绕文本-视频对齐、视觉、运动与整体四大维度打分,文本契合度与动作流畅度两项关键指标一路领跑;
在 VBench 公开擂台与其他对手同台竞技,LongCat-Video 依旧拿下总榜前排席位。
注:文章转载自美团大模型公众号