当美国制裁让芯片制造工艺受限,华为选择了一条全新的突破路径——用系统级创新弥补单芯片差距,让中国AI算力实现“换道超车”。
2025年9月18日,在华为全联接大会2025上,华为轮值董事长徐直军公布了昇腾AI芯片未来四年的详细路线图。
这是华为首次系统披露昇腾系列芯片的长期规划,涵盖了从2026年到2028年的四款新品,同时推出了基于“灵衢”互联技术的超节点与集群解决方案,宣称将打造“全球最强算力集群”。
回应市场需求:自DeepSeek开源大模型引发行业震动以来,华为收到大量客户反馈需要更清晰的算力规划
展示技术实力:证明即使在芯片制造工艺受限的情况下,中国仍然可以通过系统级创新实现算力突破
构建产业信心:为国内AI产业发展提供明确的算力保障,消除合作伙伴的顾虑
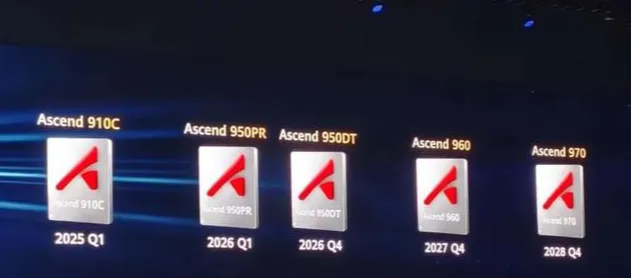
四年四款,算力翻倍增长华为公布了清晰的昇腾芯片发展路线图:
芯片型号
主要特点
发布时间
昇腾950PR
面向推理Prefill和推荐场景,采用华为自研HBM HiBL 1.0
2026年第一季度
昇腾950DT
面向推理Decode和训练场景,互联带宽提升至2TB/s
2026年第四季度
昇腾960
算力、内存容量、带宽相比950系列翻倍
2027年第四季度
昇腾970
FP8算力达到4PFLOPS,FP4算力达到8PFLOPS
2028年第四季度
这一路线图体现了华为“几乎一年一代、算力翻倍”的研发节奏,确保中国AI算力持续增长的需求得到满足。
超节点技术:系统级创新的突破面对单芯片制造工艺的限制,华为选择了通过系统架构创新实现突破。
超节点架构:物理上由多台机器组成,但逻辑上以一台机器学习、思考、推理
Atlas 950 SuperPoD:支持8192张昇腾卡,预计2026年第四季度上市
Atlas 960 SuperPoD:支持15488张昇腾卡,预计2027年第四季度上市
性能对比优势:
相比英伟达NVL144,Atlas 950超节点卡规模是其56.8倍
总算力是其6.7倍,内存容量是其15倍(达到1152TB)
互联带宽是其62倍(达到16.3PB/s)
这种超节点架构的性能较传统架构提升显著,有效弥补了单芯片性能的差距。

实现万张芯片协同工作的关键是华为自研的“灵衢”互联协议,该技术突破了大规模超节点的互联技术巨大挑战:
超低时延:达到纳秒级故障检测和保护功能
超大带宽:实现TB级超大带宽传输
高可靠性:光互联可靠性提升100倍,满足高可靠全光互联要求
开放生态:华为宣布开放灵衢2.0技术规范,欢迎产业界伙伴基于灵衢研发相关产品和部件
这项技术让8192张甚至15488张芯片能够像“一台计算机”一样协同工作,避免了传统计算中“卡间时延高、数据传输慢”的痛点。
🌐 五、应对制裁:中国算力的独特发展路径徐直军坦言:“由于我们受到美国的制裁,不能到台积电去投片,我们单颗芯片的算力相比英伟达是有差距的。”
但他同时强调:“华为有三十多年联人、联机器的积累,所以我们在联接技术上强力投资、实现突破,使得我们能够做到万卡级的超节点,从而一直能够做到世界上算力最强!”
这种发展路径体现了中国算力产业的务实策略:
不追求单点极致:在单芯片性能受限情况下,通过系统架构创新实现整体性能突破
发挥联接优势:利用华为在通信领域三十多年的技术积累,实现“换道超车”
构建开放生态:通过开放灵衢等技术规范,吸引产业链企业共同发展

华为此次公布的昇腾芯片路线图和超节点解决方案,展现了中国在算力领域的一条独特发展路径:通过系统架构创新弥补单点技术差距,通过开放合作构建产业生态。
正如徐直军所言:“我们单颗芯片与英伟达是有差距的,但是长期投入连接技术,我们构筑的超节点,可以做到世界上最强”。
这条路径不仅为中国AI产业提供了算力保障,更为全球算力发展提供了新的思路和方向。在AI竞争日益激烈的今天,算力自主的重要性不言而喻,华为此次发布的技术路线,无疑为中国AI发展注入了一剂强心针。
📌 互动话题:你看好华为的超节点技术路线吗?认为它能帮助中国AI实现“换道超车”吗?欢迎在评论区分享你的观点!
(图片均来源网络,侵联删)