音频超分辨率(Audio Super-Resolution, Audio SR),即从低采样率音频恢复出高采样率版本,是提升语音清晰度、音乐细节与沉浸式音频体验的关键技术。
无论是在老旧录音修复、语音通信增强,还是音乐制作与多模态生成中,高分辨率音频都能显著提升听感与表现力。然而,由于高频细节在低采样率信号中被严重损失,这一任务一直是音频生成领域的核心挑战。
值得注意的是,近期由OpenAI推出的有声视频模型Sora 2已能生成采样率高达96 kHz的音频,为高保真音频生成树立了新的技术标杆。而现有学术界的音频超分模型大多仍局限于48 kHz以内,缺乏能够稳定支持更高采样率的通用框架。
在这一背景下,清华大学与生数科技(Shengshu AI)团队围绕桥类生成模型与音频超分任务展开系统研究,先后在语音领域顶级会议ICASSP 2025和机器学习顶级会议NeurIPS 2025发表了两项连续成果:
轻量化语音波形超分模型Bridge-SR,以及面向高达192 kHz母带级音频的多功能超分框架AudioLBM。
其中,AudioLBM覆盖语音、音效与音乐等多类内容,在通用高分辨率音频生成方面展现出重要的扩展潜力。
从数据到数据:Bridge-SR的探索2025年发表于ICASSP的Bridge-SR工作首次将薛定谔桥(Schrödinger Bridge)模型引入语音超分任务,在“数据到数据”的生成范式下建立了低分辨率波形与高分辨率波形之间的可解桥接过程。
不同于扩散模型从随机噪声逐步生成信号的“噪声到数据”方式,Bridge-SR直接利用低分辨率波形作为生成先验,使模型在轻量化网络(仅1.7M参数)下就能以“数据到数据”范式实现高效、高保真的语音超分,并在VCTK语音测试集上优于多项主流方法。
这一工作为先验驱动的音频超分提供了新思路,也为后续更通用、更高质量的音频超分模型奠定了理论与实验基础。
 △图一:波形空间的轻量化桥类超分模块设计
△图一:波形空间的轻量化桥类超分模块设计 通过非对称的噪声调度设计,频域幅度谱、相位谱的辅助监督,与一阶PF-ODE采样,Bridge-SR在音频波形空间采用基线模型中最轻量级的1.7M网络即实现了语音超分的质量突破。
 △图二:VCTK Benchmark测试集的语音超分质量对比
△图二:VCTK Benchmark测试集的语音超分质量对比 近日,团队继续深入研究,开发针对语音、音效、音乐全音频信号的通用超分模型,设计“隐空间桥类模型”AudioLBM,在Any-to-48 kHz的音频超分任务中大幅超越基线模型,实现音频超分新范式。并成功实现了96kHz和192kHz音频超分的工程突破,使得母带音质不再稀缺。
从隐变量到隐变量:AudioLBM的突破在 Bridge-SR 的基础上,团队进一步提出了AudioLBM,论文已发表于 NeurIPS 2025。
该研究探索了从“波形域生成”到“隐空间建模”的转变,实现了基于桥类模型的通用音频超分。AudioLBM首次在波形连续隐空间中构建低分辨率到高分辨率的隐变量桥接生成过程。
研究团队通过变分自编码器(VAE)将波形压缩为连续隐空间表征,并在该空间中学习概率生成映射,从而保留输入波形的结构化先验信息,同时提升模型的泛化建模能力。
下图为,音频超分任务(上)、传统在频谱隐空间的扩散模型(中)、和波形隐空间桥类模型(下):
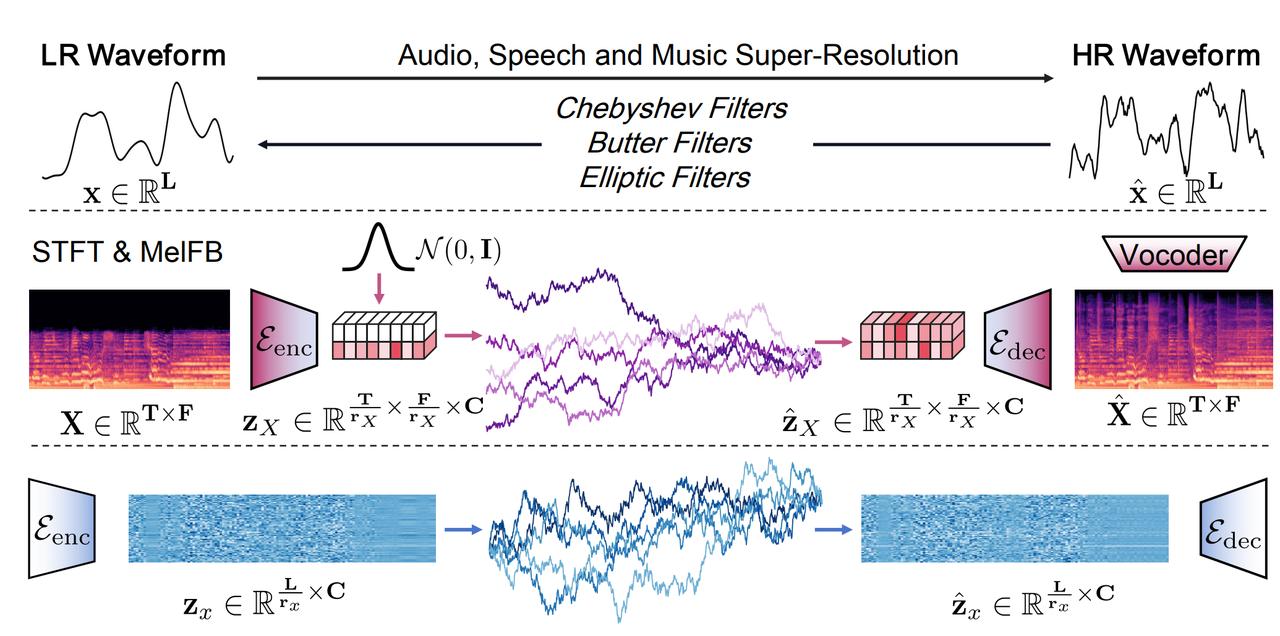
为应对高分辨率数据稀缺问题,提升训练效率,AudioLBM提出了频率感知机制(frequency-aware LBM),在训练中显式感知先验采样率与基于团队设计的信号处理手段自动检测的目标采样率,使模型能够学习“任意采样率到任意采样率”(any-to-any)的超分过程。
进一步地,为了有效实现采样率上限突破,团队设计了级联桥类模型(cascaded LBM),将模型能力从48 kHz扩展至96 kHz与192 kHz,首次实现了音频超分研究中覆盖192 kHz工业级采样率的探索。
通过先验增强(prior augmentation)与潜空间模糊(latent blurring)策略,模型能够在多阶段生成中保持高频细节与能量一致性。同时,团队对各阶段压缩网络和桥模型进行级联微调,有效利用低分辨率模型作为更高分辨率模型的强大先验。
 △图四:级联桥类模型设计
△图四:级联桥类模型设计 在跨语音、音效与音乐的多域评测中,AudioLBM在Any-to-48kHz超分任务上取得新的SOTA(state-of-the-art)表现:
 △图五:通用音频超分的质量对比
△图五:通用音频超分的质量对比 相较于基线模型AudioSR与FlowHigh,在对数谱距离(LSD)上均明显下降,同时在96 kHz与192 kHz任务中保持稳定性能。该方法在统一框架下实现了对语音、音效与音乐的高保真重建,显著提升了通用性。实现了从语音到音乐的统一高分辨率生成。
 △图六:音频超分结果的频谱展示
△图六:音频超分结果的频谱展示 针对音频数据的其他表征空间,如波形空间、谱空间,团队也做出消融实验。对于语音、音效、音乐通用音频超分任务,波形隐空间达到最佳效果:
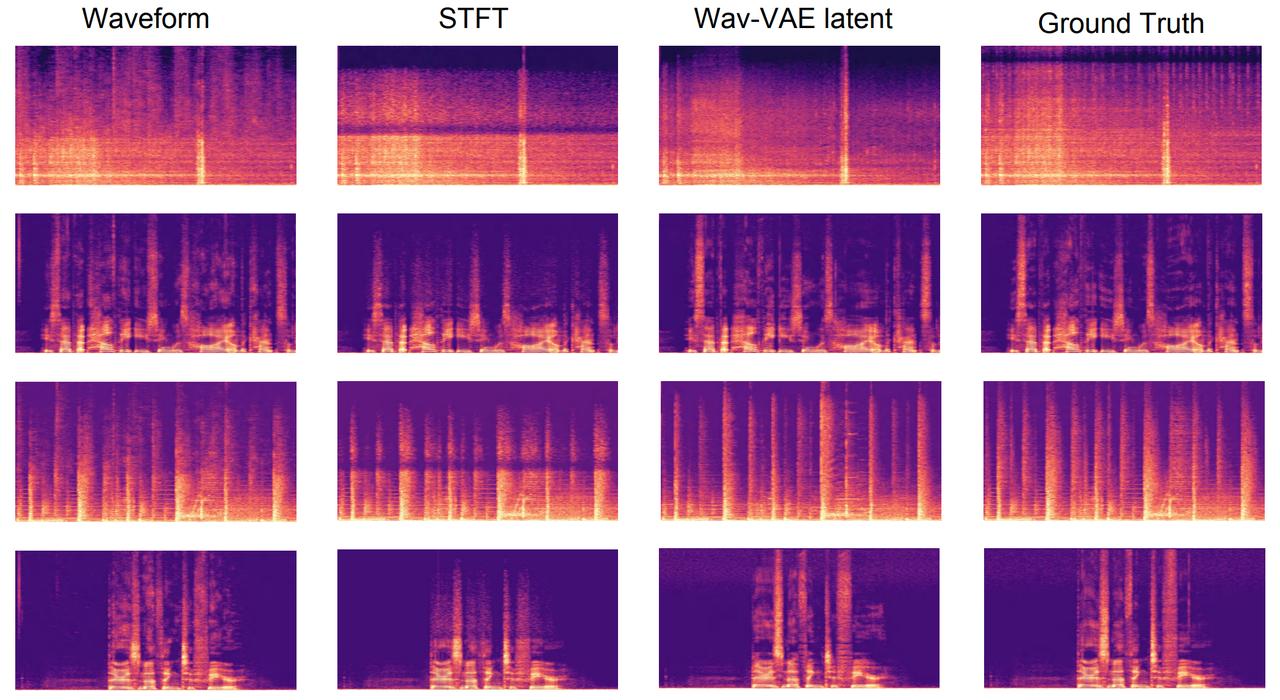 △图七:音频波形空间、谱空间、波形隐空间超分结果与真值的频谱展示
作者介绍
△图七:音频波形空间、谱空间、波形隐空间超分结果与真值的频谱展示
作者介绍 此两项目的第一作者均为李畅和陈泽华。
李畅是中国科学技术大学少年班学院的本科生,主要研究方向是语音,音频相关的生成建模与表征学习,曾以第一作者身份在多个CCF-A/B类会议发表音频相关学术研究。

陈泽华是清华大学计算机系水木学者博士后,博士毕业于英国帝国理工学院电气与电子工程系,主要研究方向为概率生成模型,及其在语音、音效、生物电信号合成等方面的应用。在语音和机器学习领域的重要会议与期刊上持续发表相关研究工作。

【Bridge-SR】论文地址:https://arxiv.org/pdf/2501.07897样本展示:https://bridge-sr.github.io/
【AudioLBM】论文地址:https://arxiv.org/pdf/2509.17609样本展示:https://audiolbm.github.io/
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态