中国正在悄悄赢得AI竞赛吗?这个问题,最近被 BBC 抛了出来。

不是在中美发布会,不是在华盛顿智库,也不是在深圳实验室,而是在Pinterest。
是的,就是那个每天有数亿用户刷灵感、买同款、找趋势的美国公司。
BBC 的报道里提到一件非常反直觉的事: Pinterest 正在测试、并逐步使用中国的 AI 模型,来驱动它的推荐系统。
而这家以“美国审美”“硅谷基因”著称的平台,本可以选择任何一家美国顶级 AI 实验室。
但它没有。
它选择了中国的 DeepSeek(深度求索)。

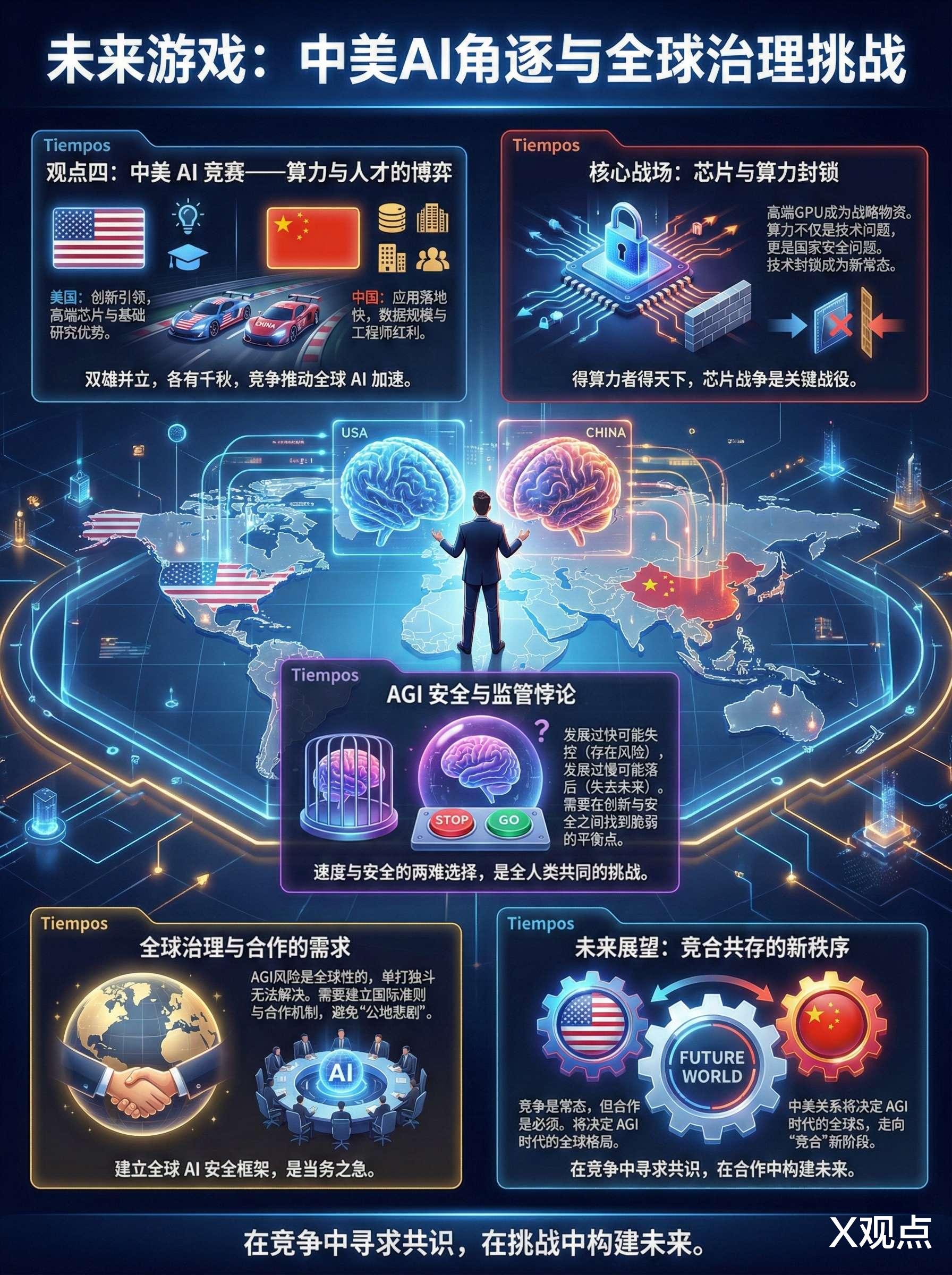
过去几年,中美在人工智能领域走了截然不同的两条路:
美国,专注“铺铁轨”:从Transformer架构到MoE(混合专家)模型,从TPU芯片到CUDA生态,美国牢牢掌控着AI底层技术的命脉。
英伟达、谷歌、Meta、OpenAI……这些名字代表的是算法、算力、框架和标准的制定者。他们不急于落地,而是不断向通用智能的深水区探索。

中国,则全力“走铁轨”:受限于高端芯片禁令,中国无法在底层硬件上与美国正面硬刚。但凭借庞大的市场、丰富的应用场景和极强的工程化能力,中国将AI快速嵌入千行百业。
从三甲医院的AI辅助诊断,到贵州山区的智慧农业;从广州“一网通办”的政务服务,到工厂里的智能质检机器人。截至2025年,中国已备案439款大模型,覆盖30多个行业,AI产业规模突破7000亿元。
简言之:美国在造火车头,中国在跑满全国的列车。

但变化正在发生。
2025年以来,以DeepSeek、通义千问、百川智能为代表的中国大模型公司,不再满足于“应用层创新”。他们开始反向攻坚底层:
DeepSeek开源R-1模型,性能对标GPT-4,推理成本却低一个数量级;阿里通义千问推出Qwen-Max、Qwen-Turbo系列,支持多模态、长上下文、Agent协作;华为昇腾+盘古大模型构建全栈自主生态;寒武纪、海光、龙芯等国产AI芯片逐步填补“卡脖子”空白。
与此同时,美国也开始意识到:没有场景的创新,终将沦为实验室的孤芳自赏。OpenAI加速商业化,Anthropic推出企业版Claude,连Meta都开始把Llama模型卖给银行和零售商。
于是,2026年成了一个拐点:中国在继续狂奔应用场景的同时,开始向上攀登技术高峰;美国在巩固底层优势的同时,不得不向下寻找落地出口。
两条原本平行的轨道,正在交叉。
真正的AI霸权,不属于只懂铺铁轨的人,也不属于只会跑列车的人,而属于既能造出高速轨道,又能调度千万列智能列车的国家。
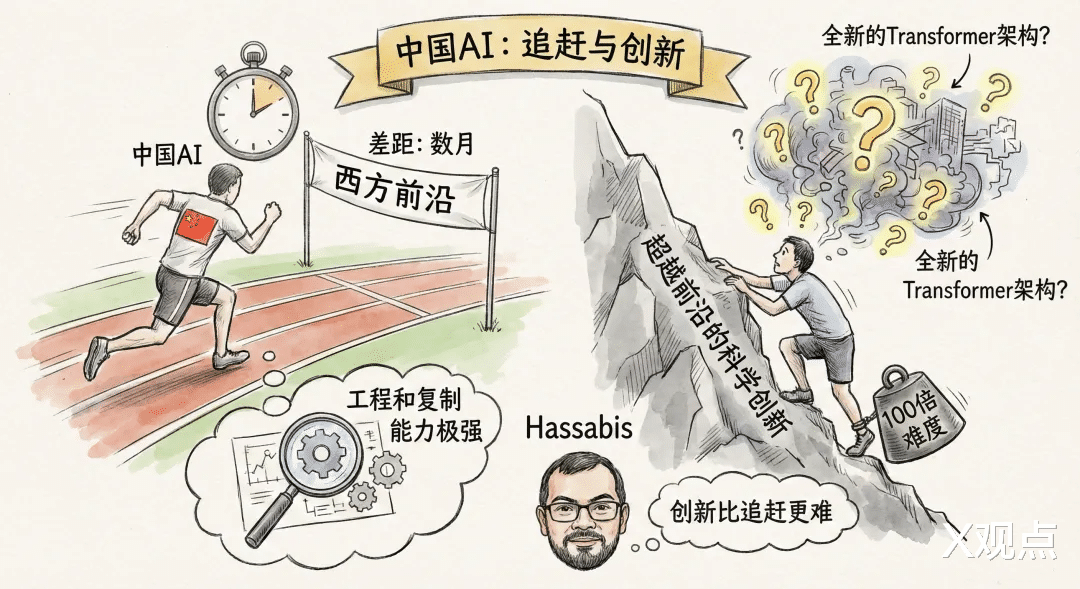
中国的优势在于“用中学”——在真实世界中迭代模型,在用户反馈中优化算法。这种“场景驱动”的模式,正在催生新一代具身智能、世界模型和可靠推理系统。
而美国的优势在于“思中创”——在理论前沿持续突破,在基础研究上保持领先。但若脱离市场,再精妙的模型也可能被束之高阁。
未来五年,胜负不在论文数量,不在芯片算力,而在谁能率先实现“底层创新 × 场景闭环”的正循环。
Pinterest的选择不是偶然。它背后是一个信号:中国的AI,已经从“能用”走向“好用”,甚至“更好用”。
当西方还在争论AI伦理与监管时,中国已在田间地头、手术室、工厂车间完成了数亿次真实验证。这种“接地气”的力量,正在反哺技术创新。
所以,中国是否正在赢得AI竞赛?答案或许是:我们不一定赢在起点,但很可能赢在终点——因为我们的AI,长在了这片土地上。