AI大模型的记忆困境正在被DeepSeek的Engram技术打破。这项突破性研究不再让AI死记硬背,而是通过'条件记忆'机制实现知识快速检索,为产品带来更低的成本、更强的专业性和更流畅的长文本处理能力。本文将深入解析这项技术如何重构AI产品的底层逻辑与用户体验。

“如果把大模型比作一名员工,现在的模型大多属于‘聪明但没记性’类型:为了回答一个常识问题,非要动用全身的逻辑细胞去推算半天,既费时间又费算力。
最近,DeepSeek发布的最新论文《Engram》打破了这个僵局。他们不再执着于让AI变得更‘深刻’,而是给AI装上了一个‘外挂硬盘’。这篇论文不仅是技术上的突破,更是在成本、效率和知识容量之间,为我们产品经理画出了一道全新的‘帕累托改进曲线’。
今天,我们不聊晦涩的算法公式,只聊DeepSeek这个‘新外挂’,将如何改变AI产品的游戏规则。”
论文核心解读:不再让AI“死记硬背”
现在的LLM(大语言模型)就像一个极其聪明但没有笔记本的学生。为了记住“鲁迅写过《孔乙己》”这个简单事实,它必须动用大脑中数以亿计的神经元进行复杂的放电计算。
DeepSeek这篇论文提出了一个划时代的思路:Engram(条件记忆)。
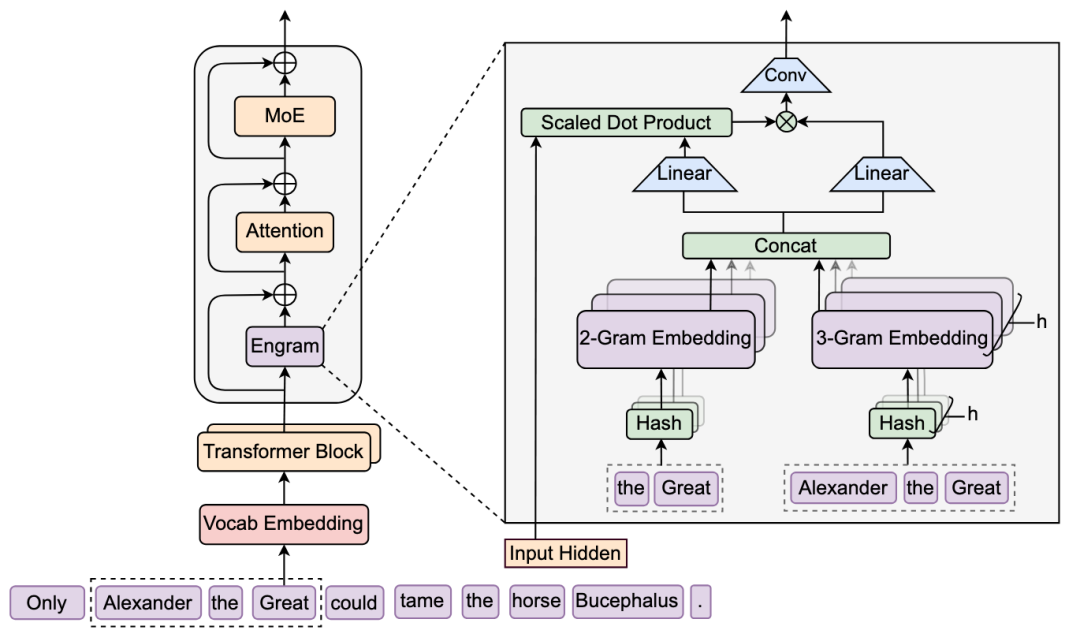
引入“查表”机制:论文认为,现在的模型太累了,什么都要靠“算”。Engram给模型配了一张超大的“N-gram查找表”。遇到固定的知识点,模型不需要再通过层层神经元计算,直接去“查字典”就行。
新的稀疏维度:以前我们通过MoE(混合专家模型)让计算变得稀疏(只动用部分大脑),现在Engram实现了记忆的稀疏化。
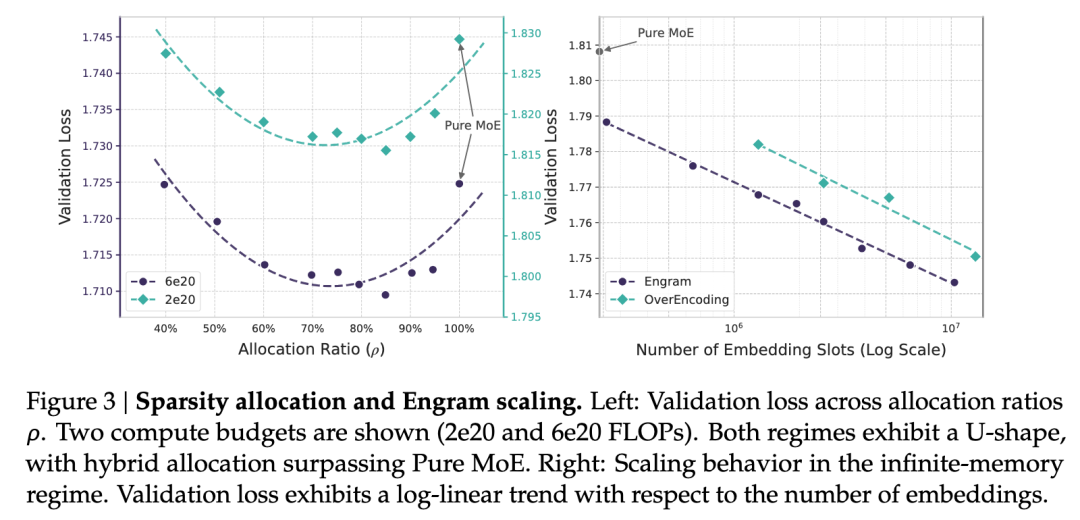
U型分配定律:论文发现了一个有趣的规律:模型不是越深越好,也不是存储越大越好。在相同的资源下,拨出约20%-25%的参数专门去做这种“查表式记忆”,模型的性价比最高。
技术应用场景:它能为产品带来什么?
对于产品经理来说,这项技术意味着更低的成本、更强的专业性、更好的长文本处理能力。

行业知识库的“零成本”植入
现状:现在的垂直领域模型,要么靠昂贵的微调(Fine-tuning),要么靠RAG(检索增强生成)。
Engram的便利:我们可以直接通过扩展Engram的“嵌入表”,把海量的法律条文、医学百科、企业年报变成模型的“原生记忆”。它查得比RAG快,理解得比微调深。
“过目不忘”的长文本助手
场景:读一本50万字的小说,或者审阅几百份合规文件。
便利:论文显示,Engram大幅提升了模型在长文本下的表现(NIAH测试接近满分)。因为它把底层的静态知识交给了存储,腾出了宝贵的“注意力资源”去处理逻辑关系。
极低延迟的实时交互
场景:车载系统、语音助手等对响应速度要求极高的场景。
便利:查表的操作是$O(1)$的,几乎不占用计算时间。这意味着我们可以用更小的计算代价,实现更丰富的知识储备,让AI响应更快,不卡顿。
未来展望:从“计算密集”到“存储密集”
作为产品经理,我们需要敏锐捕捉到模型架构演进的趋势:
AI的“冯·诺依曼架构”回归:计算机的发展是从计算与存储分离开始的。早期的LLM试图用计算代替存储,而DeepSeek的Engram标志着“存储”重新回归模型核心。未来,我们可能会看到拥有“PB级存储”但“轻量级计算”的模型,这种模型将极其擅长处理百科全书式的任务。
硬件层面的重构:既然“查表”这么有效,未来的AI芯片可能不再只卷算力(TFLOPS),而是会卷显存带宽和内存容量。这对整个供应链都是巨大的改变。
个性化AI的终极形态:想象一下,每个用户都可以拥有一个专属的Engram插件,里面存储了你过去十年所有的聊天记录、笔记和喜好。模型不需要重新训练,只需要挂载你的专属“记忆表”,就能瞬间变成最懂你的助手。
结语
DeepSeek的Engram告诉我们:智慧不一定要靠昂贵的思考,有时“博闻强识”的查找反而是更高效的路径。
对于产品经理而言,未来的竞争可能不再是谁的模型参数更多,而是谁能更好地平衡逻辑(计算)与记忆(存储),在有限的成本下,给用户提供最精准的答案。