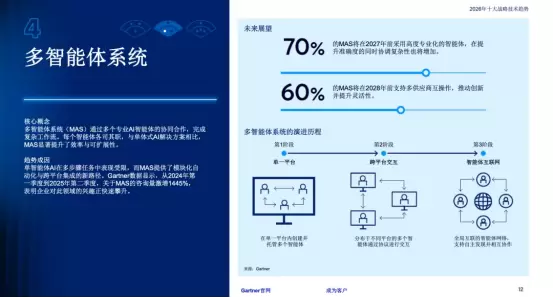
序言:奇点临近,可观测性的代际跨越
站在2026年的时间节点回望,我们正处于IT基础设施历史上最深刻的变革之中。这不仅是云计算的延续,更是一场由人工智能(AI)主导的“认知革命”。如果说云原生(CloudNative)时代解决了资源的弹性问题,那么AI原生(AINative)时代则致力于解决决策的自主性问题。
Gartner的战略预测早已指出,到2026年底,由于缺乏足够的AI风险护栏,甚至可能出现数千起因AI决策失误导致的法律索赔案件。这一预测不仅揭示了AI技术的双刃剑效应,更深刻地指出了当前技术栈中最大的空白——对于自主智能体(AutonomousAgents)的深度可观测性与治理能力。

在2026年的企业环境中,由于AgenticAI的普及,软件不再仅仅是执行预定义代码的静态指令集,而是变成了具有推理、规划和执行能力的“数字员工”。这些智能体像F1赛车的维修团队一样协作,以模块化的方式处理复杂的业务逻辑。然而,这种自主性带来了前所未有的不确定性:一个简单的用户请求可能触发成百上千次非确定性的模型推理、工具调用和数据库交互。传统的应用性能监控(APM)工具,基于确定性的堆栈跟踪和静态的拓扑图,已无法完全解释这种动态生成的行为链路。

与此同时,数据重力的法则依然生效且愈发严苛。随着生成式AI和多模态交互的爆发,企业产生的数据量呈指数级增长,但IT预算的增长却远远滞后。如何在数据爆炸的背景下,既保持对所有信号的敏锐捕捉,又严格控制存储成本,成为了SRE和CIO面临的头号难题。传统的“索引一切”(IndexEverything)的日志管理模式在经济上已然破产,市场迫切呼唤一种全新的、基于存算分离架构的数据底座。
本文将作为观测云(Guance)2026年的产品技术展望,深入剖析在这一大变革背景下,我们如何通过产品演进解决测试、业务、数分、SRE等多角色的核心痛点。我们将沿着“从上层业务应用到底层基础设施”的逻辑脉络,抽丝剥茧,呈现一个全栈可观测的2026图景。
1.市场趋势:驱动变革的四股力量
在展开产品细节之前,我们需要厘清推动2026年可观测性技术变革的宏观力量。
1.1AIAgent的崛起与黑盒治理危机
2026年,AI不再是辅助工具,而是核心生产力。Gartner指出,AI原生开发平台正在让自主Agent协作完成复杂任务。然而,Agent的引入带来了全新的不可预测性:
·非确定性路径:Agent的决策逻辑是动态生成的,传统的基于固定代码路径的APM难以追踪其思维链。
·Token经济学:每一次API调用都对应着真金白银。监控系统的核心指标从CPU使用率转向了“Token消耗率”与“任务完成成本”。
·黑盒风险:当Agent陷入死循环或产生幻觉时,传统的监控告警往往滞后,导致巨额的API费用浪费。
1.2数据引力与存算分离的必然
随着数字化转型的深入,企业数据量正以每年180EB的速度增长。传统的基于本地磁盘(SSD/HDD)的存储架构(存算耦合)面临巨大的成本压力:
·扩容困境:为了增加存储空间,不得不增加计算节点,导致计算资源闲置浪费。
·冷热数据鸿沟:90%的查询集中在最近24小时的数据,但为了合规,企业必须存储数年的历史数据。将所有数据都放在昂贵的块存储上在经济上已不可行。
·解决方案:市场正全面转向基于对象存储(S3/OSS)的存算分离架构,这也是GuanceDB演进的必然方向。
1.3平台工程(PlatformEngineering)与左移
DevOps正在进化为平台工程。开发者不再满足于被动接收告警,他们需要自服务的、可编程的观测能力。可观测性正在“左移”进入CI/CD流水线,开发者要求能够通过代码(MonitoringasCode)定义监控规则,并通过API触发自动化修复流程。
1.4FinOps与数据主权的博弈
随着全球数据法规(GDPR等)的收紧,大型企业越来越倾向于“控制面与数据面分离”的架构。他们希望利用SaaS厂商提供的先进AI分析能力(控制面),但要求原始遥测数据保留在自己的云账号下的对象存储桶中(数据面),即BYOS(BringYourOwnStorage)模式。
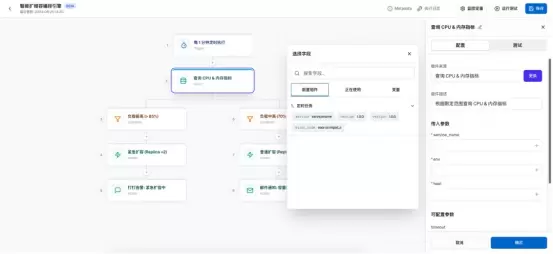
2.观测云新的产品功能:蓝图(Blueprint)
——可观测性编排与自动化引擎
在观测云2026的规划中,“蓝图”(Blueprint)不是一张静态的架构图或一套预设的Dashboard模板。基于最新的用户需求与UI设计,蓝图被重新定义为“官方组件支持计划”的核心载体,是一个低代码/无代码的可观测性编排与自动化引擎。
它通过可视化工作流(DAG-有向无环图)将分散的观测能力串联起来,形成从数据查询->逻辑转换->AI分析->行动的完整闭环。
2.1蓝图的核心架构:可视化DAG工作流
传统的监控告警是离散的:一个阈值触发一封邮件。而2026年的蓝图引擎引入了状态机与流式处理的概念。蓝图工作流由以下四类核心节点构成,支持用户通过拖拽方式构建复杂的运维逻辑:
2.1.1数据查询节点(Input/Sensor)
·DQL(DataQueryLanguage)驱动:支持复杂的查询逻辑,包含了简单的指标阈值(如CPU>80%),更加支持跨数据源的关联查询。
-示例:“查询最近5分钟支付接口的P99延迟,且仅当该延迟不仅超过阈值,同时伴随错误日志激增时触发。”
·多源异构:支持Metrics、Logs、Traces、RUM(用户体验数据)的混合查询。
2.1.2转换与逻辑节点(Processor/Logic)
·低代码处理:支持JavaScript/TypeScript片段或表达式语言(ExpressionLanguage)。
·上下文丰富:原始告警往往缺乏上下文。转换节点可以调用外部CMDB或K8sAPI,为告警数据打上“业务线”、“负责人”、“部署版本”等标签。
·价值:解决“告警疲劳”的核心手段。通过逻辑判断(如去重、抑制、时间窗聚合),将100条原始告警压缩为1条高价值根因分析。
2.1.3AI分析节点(Intelligence/ObsyAI)
·ObsyAI智能体介入:这是蓝图的智能核心。当逻辑节点检测到异常后,自动唤起ObsyAI进行根因分析。
·能力:自动关联该时间段内的变更事件(ChangeEvents)、错误日志聚类(LogPatterns)和异常链路等等。
·输出:一段自然语言描述的诊断建议:“检测到支付服务延迟升高,关联到3分钟前payment-service的v2.1发布,且DB连接池报错激增。”
2.1.4行动节点(Action/Actuator)
·OpenAPI闭环:这是蓝图与传统监控的最大区别。它通过OpenAPI与外部系统对接,执行实质性操作。
·场景覆盖:
-通知:发送富文本消息到Slack/钉钉/企业微信(包含AI诊断结果)等任意communicationchannel。
-监控器管理:自动静默非核心服务的告警,或在流量高峰期动态调整阈值。
3.更加全面的变更观测(ChangeObservability)
——根因分析的时间维度
3.1变更:系统熵增的核心问题
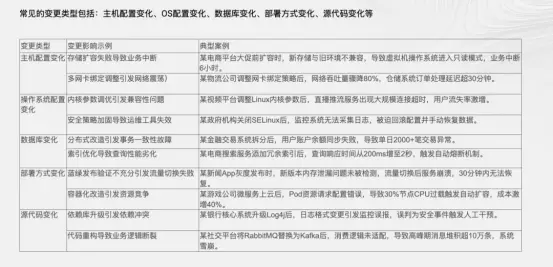
根据SRE的经验法则,80%的生产事故是由变更(Change)引起的。无论是代码发布、配置文件的修改、FeatureFlag的切换,还是基础设施的扩缩容操作,都是打破系统稳态的潜在因素。然而,传统的监控工具往往只记录了“结果”(Metrics的突变、Logs的报错),却丢失了“原因”(谁、在什么时候、做了什么变更)。
观测云2026将“变更”提升为与Logs、Metrics、Traces同等的一级数据公民(First-ClassCitizen),构建了全维度的变更观测(ChangeObservability)体系。
3.2变更数据的全栈采集与关联
3.2.1统一变更数据模型
为了捕捉系统中的每一次变化,观测云2026建立了一套标准化的变更数据模型:
·应用层:深度集成Jenkins、GitLab、GitHubActions等CI/CD工具,自动捕获部署事件(Deployment)、Commit信息、Artifact版本。
·基础设施层:监听KubernetesEvents(如PodKilling,Scaling)、云厂商审计日志(如AWSCloudTrail、阿里云ActionTrail),捕获资源的创建、销毁和规格变更。
·配置层:对接Nacos、Apollo、Consul等配置中心,实时记录配置项的Diff。记录配置变了,还记录从什么变成了什么。
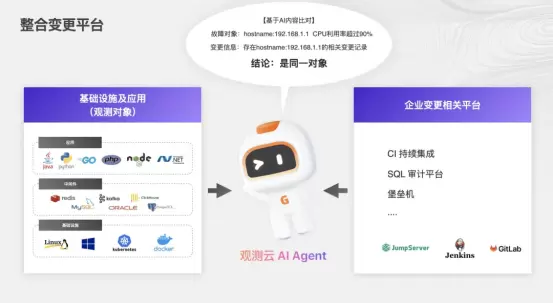
3.2.2变更叠加分析(ChangeOverlay)
变更观测的核心价值在于上下文的融合。在观测云的所有时序图表(MetricCharts)上,系统会自动叠加变更事件的标记(Annotations)。
·场景示例:
-传统视图:看到API错误率曲线在14:00突然飙升,SRE开始排查日志。
-变更观测视图:看到错误率飙升的同时,时间轴上显示13:59分有一个“支付服务v3.2Canary发布”的标记。鼠标悬停即可看到该发布的CommitMessage和变更人。
这种直观的视觉关联,能够将MTTR(平均修复时间)从小时级缩短至分钟级。运维人员不再需要去各个聊天群里询问“刚才谁动了线上环境?”,变更观测直接给出了答案。
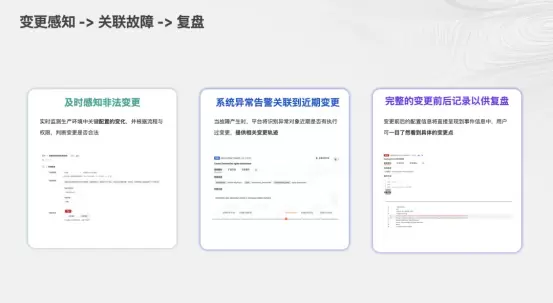
3.2.3变更风险评分与智能门禁
结合Arbiter引擎的历史分析能力,系统能对每一次变更进行风险评分。如果某次代码提交修改了核心链路的关键文件,且缺乏足够的测试覆盖率,或者历史数据显示该开发者的变更回滚率较高,系统将在变更发生前发出预警,甚至联动CI/CD流水线进行阻断。
4.ObsyAISREAgent推出:可交互的根因分析侦探
观测云2026颠覆了传统人找数据的排查模式,推出了一套基于动态假设树(DynamicHypothesisTree)的交互式排查界面。
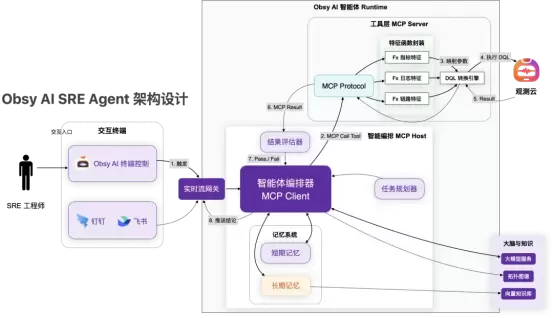
4.1触发与情境感知
当监控器发现异常(例如flight-query-api接口响应时间P99>2s),系统将直接启动ObsyAISREAgent。在观测云的Console中,用户会看到一个关联了错误上下文(ErrorTrace、LatencyChart)的交互式卡片。
4.2动态假设引擎(DynamicHypothesisEngine)
AIAgent不会盲目列出所有指标,而是像一位经验丰富的SRE工程师一样进行逻辑推演。它会基于当前的异常特征,生成多条排查路径(InvestigativePlans),并依据历史数据和专家知识库计算出每一条路径的置信度概率:
·PlanA(概率:高):假设为数据库超时(DBConnectionBlock/SlowSQL)。
·PlanB(概率:低):假设为上游依赖服务响应变慢。
·PlanC(概率:低):假设为网络网关故障。
4.3交互式思维导图与递归诊断
用户点击高概率的PlanA,界面将展开一个可视化的排查思维导图。这不仅仅是静态图表,而是AI正在执行的逻辑动作流:
·节点展开:Agent自动检查"RDS资源水位"->"数据库连接池状态"->"慢查询日志分析"。
·执行验证:每个节点会显示执行状态(CheckPassed/Failed)。例如,AI发现连接池正常,但捕获到了一条全表扫描的慢SQL。
·根因锁定:当AI找到确凿证据(如:flight_no字段缺失索引导致全表扫描),它会标记为“RootCauseIdentified”,并生成自然语言的结论报告。
4.4闭环与反馈
·对话式追问:在锁定根因后,用户可以直接与Agent对话:“如何修复这个问题?”Agent会根据知识库提供Runbook建议(如:添加索引的SQL语句)。
·多路径回溯:如果PlanA的排查结果显示一切正常(NegativeResult),Agent会智能建议用户切换至PlanB或PlanC。系统会自动保留已排查过的路径记录,避免重复工作,直到递归找到真正的问题源头。
·人工接管:整个UI包含清晰的"Abort/TakeOver"按钮,允许工程师随时打断AI的自动化逻辑,手动介入排查。
这套设计融合了现代工程美学与AI智能,将原本黑盒的AI思考过程透明化(White-box),让SRE既能享受AI的效率,又能保持对排查逻辑的掌控。
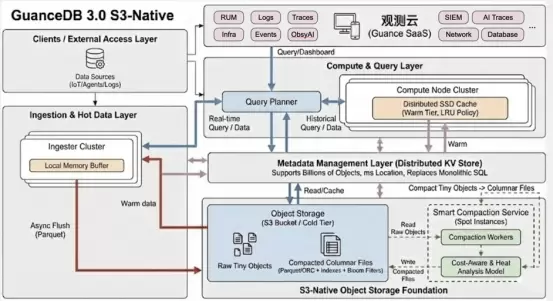
5.GuanceDB演进策略:云原生内核的重构
GuanceDB3.0是观测云强健的心脏。现有的数据库架构大多基于本地磁盘(Shared-Nothing架构),在面对PB级数据时,扩展成本高昂且缺乏弹性。GuanceDB3.0的核心目标是演进为基于对象存储(S3-Native)的存算分离架构。在这一演进过程中,我们必须正视目前与行业标杆的技术差距,并提出针对性的优化策略。
5.1关键演进挑战与探索方向
GuanceDB的演进要解决对象存储带来的物理限制:高延迟与元数据管理。
5.1.1挑战一:海量小文件元数据瓶颈(MetadataBottleneck)
·痛点:在实时写入场景下(如IoT),会产生数以亿计的小文件(Objects)。如果GuanceDB3.0的元数据层不够强大,查询时的“列出文件”操作就会成为瓶颈,导致查询超时。
·演进方向:分布式元数据架构
-探索:不再依赖单体SQL数据库存储元数据。探索分布式Key-Value存储来构建元数据层。
-目标:支持每秒数十万次的元数据读写,确保即使底层有百亿个S3对象,查询规划器也能在毫秒级定位到需要扫描的文件。
5.1.2挑战二:存算分离后的查询延迟(ColdStartLatency)
·痛点:S3的首字节延迟(TTFB)通常在几十到几百毫秒。对于“老板看数”的实时Dashboard场景,这种延迟是不可接受的。
·演进方向:智能分层与分布式缓存(SmartTiering&Caching)
-热数据(Hot):近期的数据查询直接走本地内存/磁盘,速度极快。
-温数据(Warm):引入分布式缓存层。对于经常访问的“昨天”或“上周”的数据,在计算节点的SSD上进行LRU缓存。
-冷数据(Cold):完全沉淀在S3。查询时按需拉取,接受秒级延迟,换取极致成本。
-价值:实现“像SSD一样快,像S3一样便宜”。
5.1.3挑战三:Compaction(压缩)策略与写放大
·痛点:为了优化查询,必须将S3上的小文件合并为大文件(Compaction)。但S3的PUT操作是收费的,且消耗网络带宽。
·演进方向:成本感知的智能Compaction
-策略:不盲目压缩。引入基于“查询热度”和“S3计费模型”的代价函数。
-探索:利用SpotInstances(竞价实例)在云厂商的闲时运行Compaction任务,将小文件合并为列式存储(Parquet/ORC变体),同时构建布隆过滤器(BloomFilters)和Min/Max索引,以减少未来的扫描量。
6.落地TargetingNeeds:场景化痛点的精准打击
技术必须服务于业务。不同的大客户场景对数据平台的需求是截然不同的,甚至是互斥的。我们不能用一套参数满足所有人,而是提供灵活,可以满足特种需求的数据引擎。
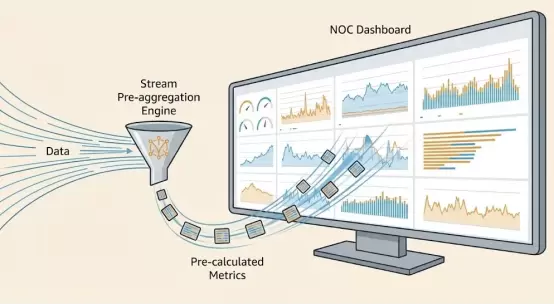
6.1场景一:实时查询(Real-TimeQuery)——老板看数
·用户:CIO、CTO、NOC监控大屏。
·痛点:Dashboard需要秒级刷新。读多写少,并发高。传统的OLAP引擎在处理聚合查询时延迟较高,且并发能力受限。
·观测云2026解决方案:流式聚合。
-原理:GuanceDB不再每次刷新都扫描原始日志。在数据摄取(Ingest)阶段,通过流式预聚合引擎(Pre-aggregationEngine)自动维护常用指标(如Global_Error_Rate)。
-效果:Dashboard查询实际上是在读取一张极小的预计算表,无论原始数据量是1TB还是1PB,大屏刷新始终保持在亚秒级。
6.2场景二:批量报表与数据挖掘——分析师的深潜
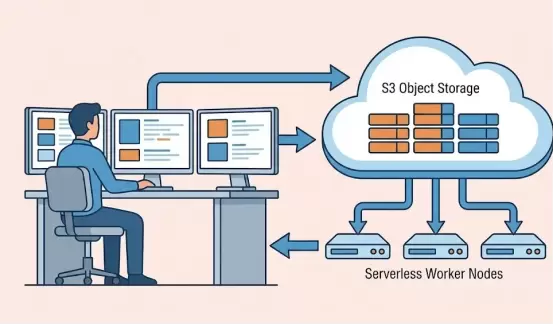
·用户:SRE专家、安全分析师、运营人员。
·痛点:读少,但IO极重。需要扫描过去30天的海量日志进行根因分析或生成月度运营报告。容易导致数据库OOM(OutofMemory)或查询超时。
·观测云2026解决方案:向量化执行引擎+Serverless扫描。
-原理:利用存算分离架构,当检测到此类大查询时,GuanceDB动态弹出一组Serverless计算节点(Worker),并行扫描S3上的数据块。利用SIMD指令集和向量化执行(VectorizedExecution)加速过滤。
-开放性:支持通过DQL导出数据到Notebook或外部数仓,满足深度挖掘需求。
6.3场景三:高并发写入——IoT与车联网数据海啸
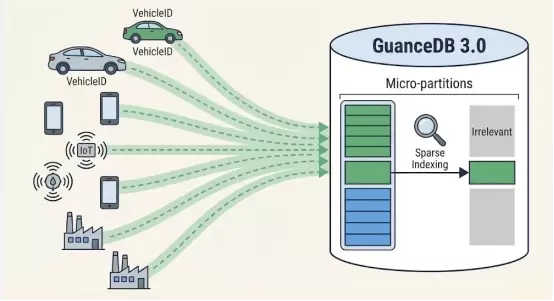
·用户:车企(V2X)、智能制造、IoT架构师。
·痛点:写多读少。Tag(标签)基数极高(HighCardinality)。例如,百万辆车,每辆车有唯一的VehicleID,传统时序数据库的倒排索引会因此膨胀爆炸,导致内存溢出。
·观测云2026解决方案:稀疏索引与列式存储优化。
-原理:放弃对高基数Tag建立全量倒排索引。GuanceDB借鉴先进的架构设计,采用稀疏索引(SparseIndexing)和数据分区(Micro-partitions)技术。
-效果:将VehicleID作为排序列,通过Min/Max索引快速跳过无关数据块。在不牺牲写入性能的前提下,支持对高基数标签的高效过滤,彻底解决“索引爆炸”问题。
6.4场景四:AI/LLM可观测——Agent行为治理
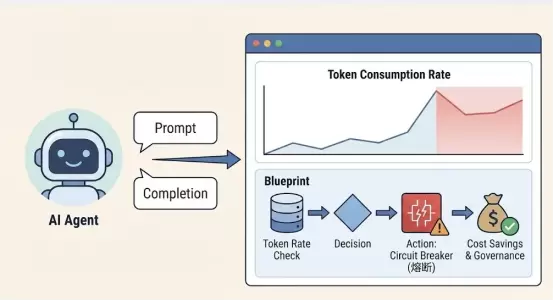
·用户:AI平台工程师、大模型应用开发者。
·痛点:Agent行为具有不确定性(幻觉、死循环),且Token成本昂贵。传统的CPU/内存监控无法反映AI业务的健康度。
·观测云2026解决方案:ModelTelemetry与成本归因。
-数据模型:引入专用的数据类型追踪Prompt和Completion的Token消耗、延迟、模型版本。
-蓝图集成:通过蓝图实时监控Token消耗速率。一旦发现某个Agent陷入死循环(Token消耗斜率异常),立即触发熔断机制(Action节点),并通知开发者。
-价值:进阶到AI业务治理,为企业节省真金白银的算力成本。
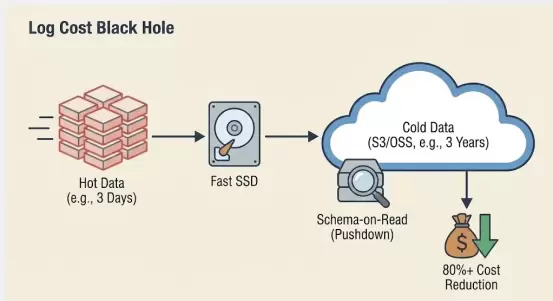
6.5场景五:日志成本黑洞——拒绝存不起,查不到
·用户:运维总监、合规审计部门、FinOps负责人。
·痛点:日志数据量呈指数级增长(每天几十TB),但99%的日志通常都用不上,只有故障时才需要回溯。传统方案要么全量索引导致存储成本天价,要么为了省钱只存3天导致关键数据丢失。
·观测云2026解决方案:冷热分层(TieredStorage)+Schema-on-Read(读时建模)。
-原理:GuanceDB引入智能分层策略。热数据(最近3天)存高性能SSD并建立全索引;温/冷数据(3天-3年)自动下沉至对象存储(S3/OSS),不建立繁重倒排索引。当需要查询冷数据时,利用算子下推(Pushdown)临时扫描目标块。
-效果:将日志的长期存储成本降低80%以上。让企业存得起海量日志,还能在需要审计时,无需数据迁移即可直接查询历史归档。
6.6场景六:微服务风暴——抓住百万分之一的异常
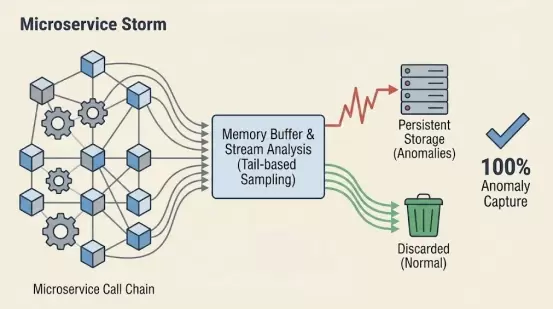
·用户:架构师、中台研发负责人。
·痛点:在成百上千个微服务的调用链中,每天产生数亿条Trace数据。传统APM采用头部采样(Head-basedSampling)(如只采1%),容易导致“关键的报错请求正好被丢弃了”,无法还原故障现场。
·观测云2026解决方案:100%全量摄取+尾部采样(Tail-basedSampling)。
-原理:数据进入系统时不做丢弃,先在内存缓冲区暂存。通过流式引擎实时分析整条链路的尾部状态(是否报错、是否高延迟)。只有有问题或高价值的链路才会被持久化存储,正常的无用链路自动丢弃。
-价值:在不增加存储预算的前提下,实现100%的异常捕获率。不再靠运气抓Bug,而是靠精准的算法。
当然以上仅是冰山一角。观测云的统一数据底座已打破场景壁垒,无论是日志降本还是链路追踪,皆能以一套架构,从容应对万千需求。
结语:观测云的2026
观测云2026的产品预告是对未来观测形态的一次预判与押注。
·市场在变:AIAgent带来了复杂性,FinOps带来了成本压力,数据主权带来了架构约束。
·产品在变:蓝图将会成为企业的自动化中枢;GuanceDB拥抱S3,打破存储的物理边界,用云原生的架构解决云时代的规模问题。
·价值在变:我们针对不同角色(CIO、SRE、IoT架构师、AI工程师等等)提供不同场景都可用的灵活解决方案。
对于CTO和CIO而言,选择观测云2026,不仅是选择了一个监控平台,更是选择了一套能够驾驭AI时代不确定性、从容应对数据洪流的系统。请查收这份产品路线图。