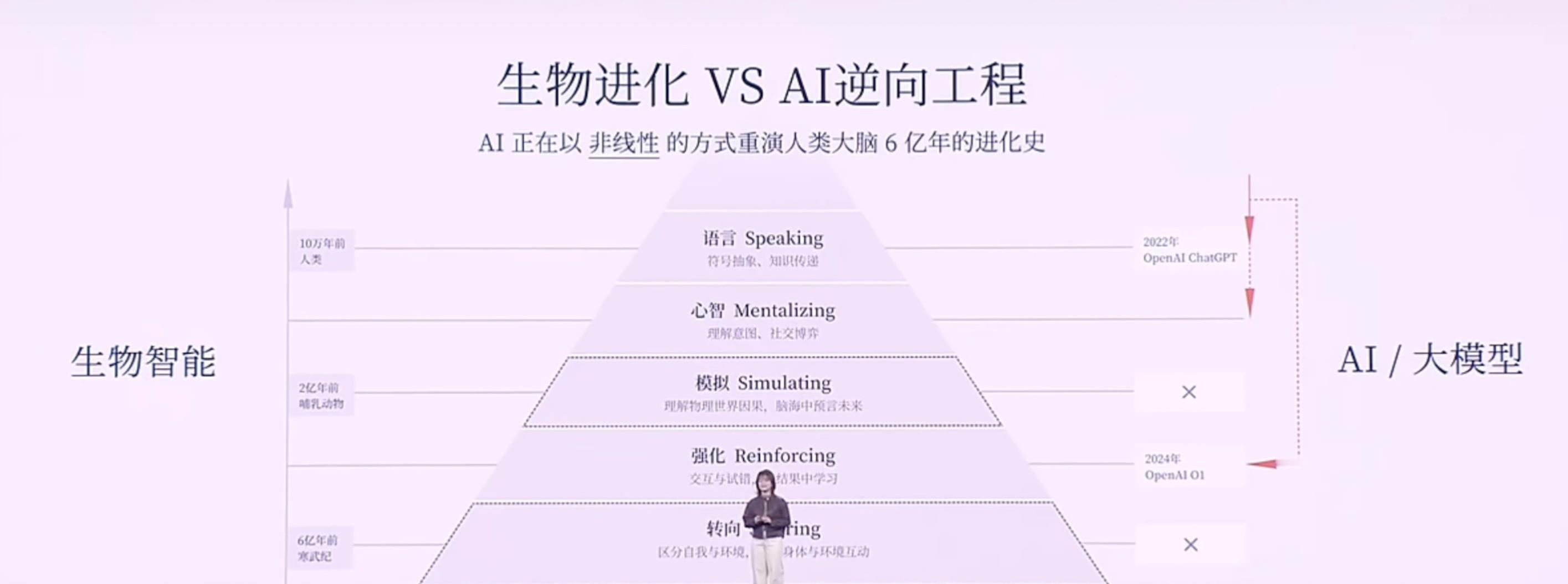
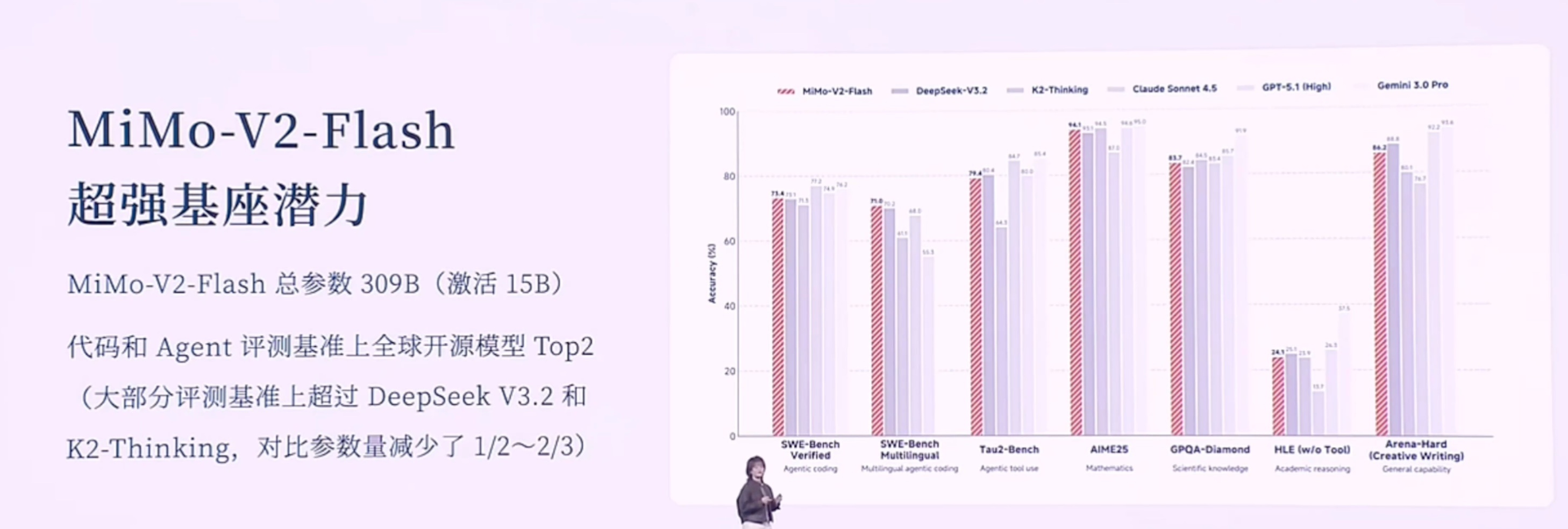
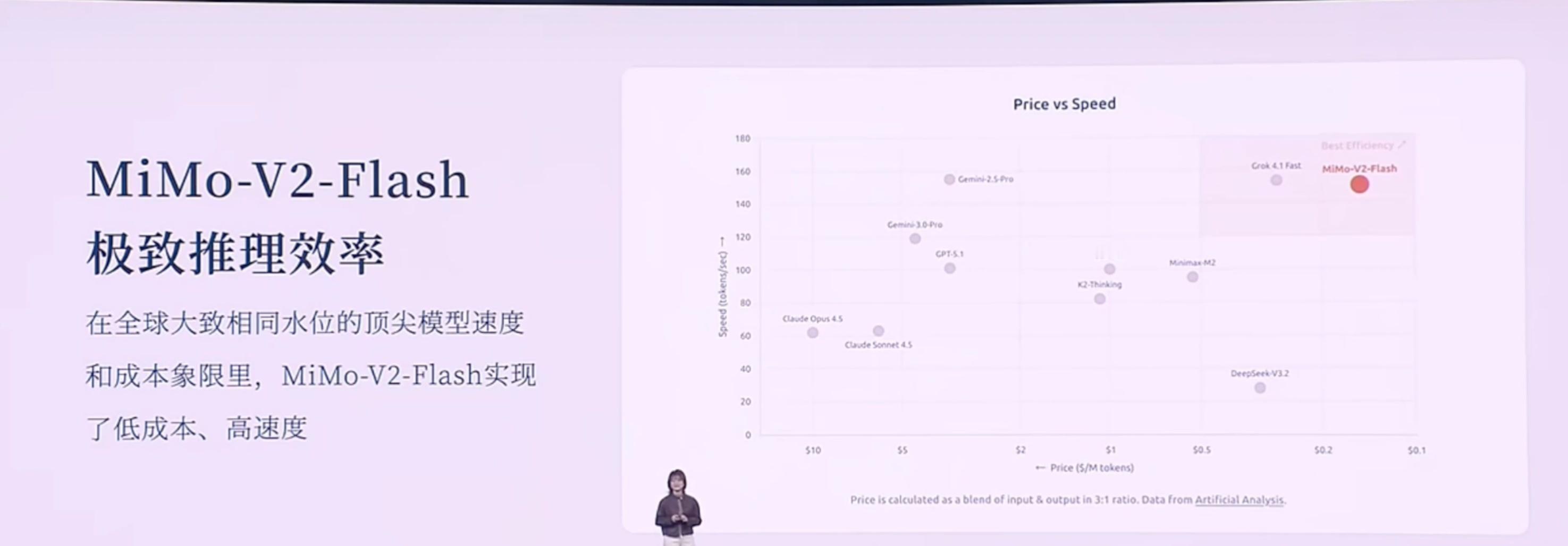
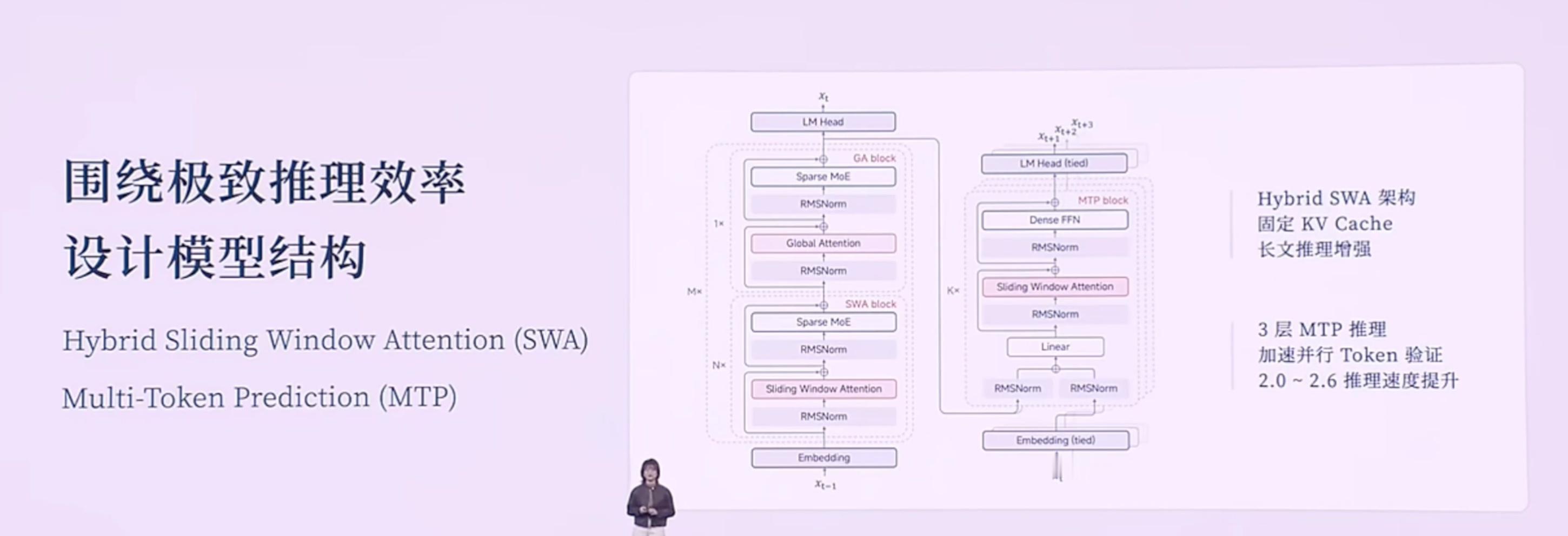
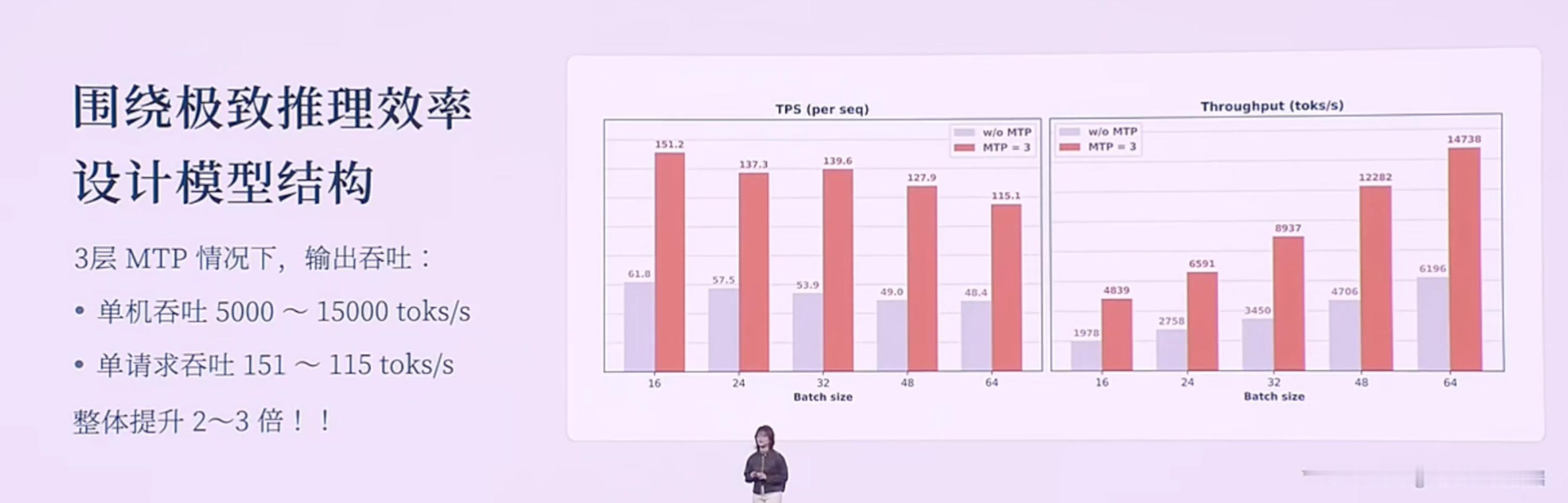
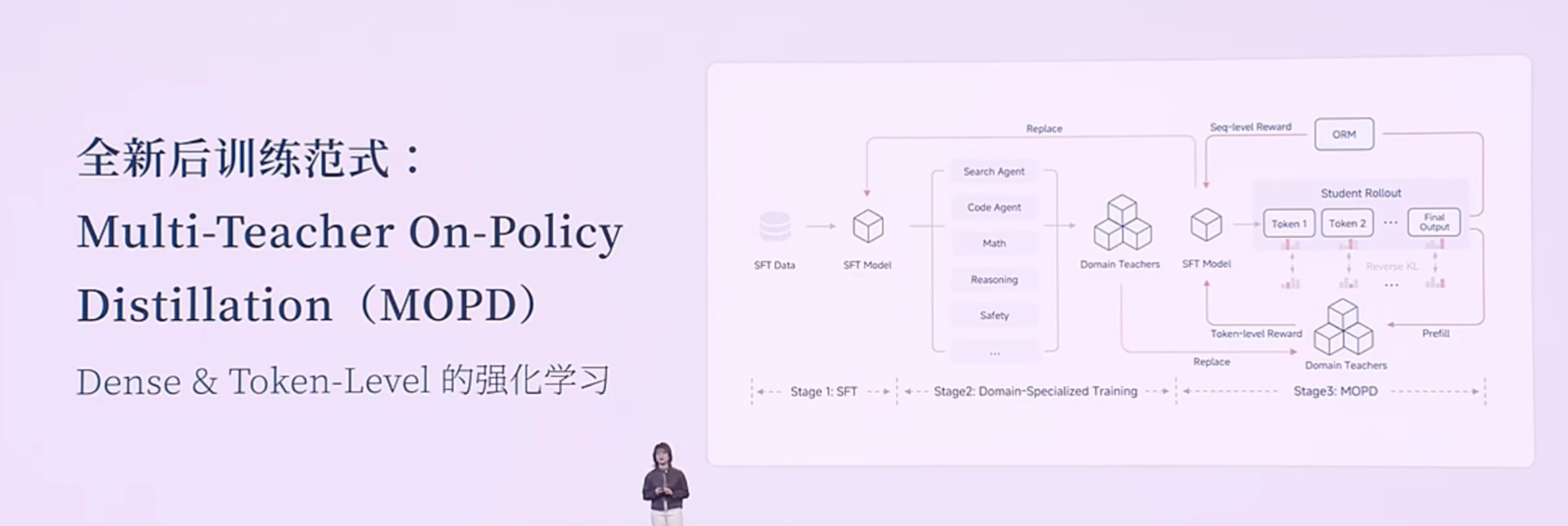
以下是小米2025人车家生态合作伙伴大会,小米MiMo大模型负责人罗福莉的主题演讲。该内容为AI根据录音转译,可能存在错误,供参考。Hello,各位开发者,大家上午好,我是罗福莉。今天我想带大家换一个视角,从11亿年生物进化的长河中,重新去审视我们正在经历的这场 AI 变革。如果我们回到生命进化的历程,会发现自然界在构建“智能”这座金字塔时,其实遵循着非常严密的逻辑。6亿年前: 生命首先学会了控制身体与环境互动;2亿年前: 哺乳动物的大脑首次具备了在行动前先在大脑里模拟未来的能力(进化出了多巴胺系统,通过强化学习进一步提升);最终: 人类才登上了智能的塔尖,掌握了“语言”这一抽象的符号系统。所以我们能看到,生物演化的规律是:先具备了对物理世界的感知和生存体验,最后才诞生了语言。[大模型的发展路径:一种“倒序”的进化]但是,大家都能发现,现在大模型的发展路径其实跟生物进化路径是不同步的,甚至说是一种倒序或跳跃。生物: 行动 -> 思考 -> 语言。大模型: 先学会了语言,再去补齐思考能力,最终再去补齐对物理世界的模拟以及具身感知。为什么大模型的智能首先产生在语言领域?因为语言不仅是符号的排列组合,更是人类思维以及对世界描述在文本领域的投影。我认为这个投影本质上是一种有损的压缩。当大模型通过 Next Token Prediction(下一词预测) 这种范式在海量文本里进行学习,当模型试图把 Loss(损失)降到最低时,我们发现它不仅是在拟合一个统计规律,而是在压缩人类数十亿年间关于这个世界的认知同构。这种压缩的过程,在我们看来就是一种智能。所以,大模型是通过语言的爆发,通过 Scaling(扩展)计算算力、Scaling 数据,从而理解了人类的思维和关于世界的理解。但其实它并不真正像人类一样具备对整个物理世界的感知。严谨来说,它应该是成功地解码了人类思维在文本空间的投影。但这是一种“自顶向下”的捷径,因为它是学习到了一种智能的结果,来倒推智能产生的过程。[小米的新一代模型:MiMo-V2 Flash]不管怎么说,语言包含了人类对世界极致的压缩,是智慧的结晶,同时也是高阶智能体之间高效协作的工具。因此,小米也从语言出发,构建了全新一代面向 Agent(智能体)的基座模型——MiMo-V2 Flash。在 MiMo-V2 Flash 研发之初,我们主要围绕三个关键问题展开:沟通语言: 当代的智能体必须有一个高效的沟通语言,即代码能力和工具调用能力。推理效率: 目前智能体之间的沟通带宽非常低,我们需要一个推理效率非常高效的模型。我们需要面向推理效率,去重新设计模型结构。训练范式: Scaling 的范式已经逐步从预训练(Pre-training)转向了后训练(Post-training)。如何去激发后训练的潜能,在强化学习上投入更多的 Training Compute(训练算力),这就非常需要一个稳定的后训练范式。在这三个问题的驱动下,我们看到了 MiMo-v Flash 超强的基座潜能。[模型参数与性能]虽然它被称为“Flash”,但在我看来它是一个非常精巧的模型(虽然总参数量看起来很大)。参数量: 总参数 309B,但激活参数只有 15B(属于 MoE 架构)。能力排名: 代码能力和 Agent 能力在公信力榜单上已进入全球 Top 1、Top 2 的梯队(在开源模型中)。对标竞品: 大部分评估基准已经比肩或超过DeepSeek V3.2、与Kimi K2 thinking 差不多。值得注意的是,这些竞品模型的总参数量大约是 MiMo-V2 Flash 的两倍到三倍范围。[技术创新:极致的效率优化]虽然模型“小”(指激活参数),但我们通过了很多优化达到了极致的推理效率。1. 混合注意力机制 (Hybrid Attention)我们的模型结构主要依靠两个创新。第一是 Hybrid Attention 结构,采用了 Sliding Window Attention(滑动窗口注意力) 和 Full Attention(全注意力) 的混合,比例大约是 5:1。为什么选 Sliding Window?虽然看起来简单(只关注邻域 token),但经过大量实验验证,看似复杂的 Linear Attention 结构在综合性能(如长短文推理、知识检索)上并不如简单的 Sliding Window。优势:KV Cache 是固定的,能非常好地适配当代的 Infra(基础设施)推理框架。2. 多 Token 预测 (MTP - Multi-Token Prediction)我们也更好地挖掘了 MTP 的潜力。MTP 最初是被提出来做推理加速的,后来 DeepSeek 将其用于提升基座模型能力。我们在训练时加入了一层 MTP 层,进一步提升基座潜能。在微调(Fine-tuning)时加入了更多层的 MTP,用极少量的算力就提升了 MTP 层的接受率。最终推理时使用了 3 层 MTP。这种加速并行进行 Token 验证的方式,在实际推理场景中能做到 2.0 到 2.6 倍的实际加速提升。[成本与速度对比]在同等水位的大模型中,MiMo-V2 Flash 具有低成本、高速度的优势:对比 DeepSeek V3.2: MiMo-V2 Flash 比 V3.2 更便宜一点,但推理速度大约是 V3.2的 3 倍左右。对比 Gemini 2.5 Pro: 推理速度相当,但推理成本比 MiMo-V2 Flash 贵了大概 20 倍。[训练范式创新:MOPD]为了充分利用高效结构扩展强化学习(RL)的算力,针对 RL 训练不稳定的问题,我们提出了一种 Multi-Teacher On-Policy Distillation (MOPD) 范式。核心: 依赖于一个 Token-level(词元级)的 Dense Reward(密集奖励)进行监督学习。流程: 通常 Post-training 是通过 SFT 和 RL 拿到各领域专家的模型。MOPD 则先让 Student(学生)模型基于自身概率分布生成序列,然后用专家模型(Teacher)对这些序列进行打分,提供非常稠密的 Token-level 监督信号。效果: 学习效率极高,几步就能将各领域专家模型的能力蒸馏到 Student 模型上。甚至发现当 Student 很快超越 Teacher 时,可以用 Student 替换 Teacher 继续自我迭代提升。[能力展示与应用]MiMo-v Flash 具备初步的在语言空间模拟世界的能力。当然它只是通过语言去模拟。Demo 1: 通过 HTML 写一个操作系统,功能大部分可实现。Demo 2: 写一个 HTML 模拟太阳系,甚至可以画一颗圣诞树并与其交互。发布情况: MiMo-v Flash 已于昨日发布,开源了所有模型权重和技术报告细节。同时也提供了 API,开发者可以实时接入 IDE 或 Web 端体验。[未来展望:从语言到具身智能]虽然现在的模型能聊天、写代码,但大家可能还是不敢把身边复杂的任务完全交给它。因为我认为真正的下一代智能体系统,不是一个语言模拟器,而是需要与我们的世界共存的智能体。下一代智能体必须具备两个潜能:从“回答问题”变成“完成任务”: 这不仅需要记忆、推理、规划,其背后研究深度很深。具备与物理世界交互的感知能力: 我们需要一个统一的动态系统,它是理解整个世界的关键基础。在此基础上,我们可以无缝嵌入到眼镜等智能终端,融入生活流。[总结与思考]回到开头的话题,大模型本质上是用算力的“暴力美学”攻克了最顶层的“语言”和第二层的“强化学习”,但跳过了中间对世界的感知/模拟,以及最底层的实体交互。现在大家认为大模型已经达到了“数学奥林匹克”水平,能模仿莎士比亚写作,但它其实不太懂“重力”等物理法则,经常产生具身幻觉。现在的 AI 只有完美的“语言外壳”,没有瞄定现实世界的“物理模型”。所以我认为,AI 进化的下一个起点,一定要有一个可以跟真实环境产生交互的物理模型。我们本质上要打造的不是一个程序,而是一个具备物理一致性、时空连贯性的虚拟宇宙。这代表了 AI 能力的本质跨越。真正的智能绝不是纯粹在文本里读出来的,而是在交互里“活”出来的。其实我刚刚说这一话呢,它是一个“非共识”。就有很多人还是比较坚信,包括 Ilya 其实都比较坚信说,在语言空间是能够实现所谓的 AGI 的。所以我带着这样一个命题,我去问了一下 MiMo-V2 Flash。我是怎么问的呢?我说:“你是怎么解读关于‘物理世界导向’——也就是说我们要去强调多模态和真实世界的交互是通往 AGI 的关键——你是怎么解读这个事儿?”它给我的回复是,它认为这是一个非常核心和深刻的观点。它认为:智能是要根植于存在的,而并非符号。 因为符号体系里边,它只能建模模式匹配、建模概率预测,它并不具备一个(实体)。而 MiMo 认为,它必须具备一个具身的、嵌入式的环境,通过与这个真实的物理世界产生持续的交互,从而持续涌现更强的能力。我觉得这其实本质上就是人类这样一个高阶智能体,它所演变的一个逻辑。这并不是我们训练进去的,是它自己涌现出来的能力。其实,本质上我们认为,技术上是可以追赶的,算力和数据也并非最终的护城河。真正的护城河,其实我认为是科学的研究文化和方法。是将未知的问题转化成模型的优势,最终去结合可用产品的一个能力。小米的大模型 Core 团队其实就是在这样的长期愿景中诞生的。我们构建了一个研究、产品、工程深度耦合的一个年轻化的团队。它非常具备创业精神,我们团队里边每个人都极度好奇,追求真理,乘着自由的风,满怀着对这个世界极致的关怀,在一起去探索智能的边界。在演讲的结尾,我想跟大家回顾一下,2020年我刚进入大模型领域时,开源模型距离顶尖闭源模型至少有3年的代差。但如今,像 DeepSeek、Qwen、MiMo 等国产开源模型,距离世界顶尖闭源模型的差距可能只有数月了。开源的价值不仅是分享代码和模型,本质上是一种**“分布式的技术加速主义”**。开源是实现 AGI(通用人工智能)普惠化,确保所有人类智慧共同进化的唯一路径。从数据的极致压缩,到算法的范式创新,再到与物理空间的深度链接,小米与全球 AI 共同定义未来。谢谢大家!小米人车家全生态合作伙伴大会