
终身行人重识别旨在持续学习新增数据中不断涌现的新增行人鉴别性信息,同时保持对已知数据的识别能力,在公共安防、社区管理、运动分析等场景中具有重要的研究和应用价值。
随着白天可见光图像和夜晚红外图像被不断采集,现有终身行人重识别方法需要持续学习特定模态中的新知识(例如:仅适用于红外模态中的热辐射信息)。
然而,特定模态中新知识的学习过程阻碍了模态间公共旧知识(例如:同时适用于可见光与红外模态的人体体态信息)的保留,导致了单模态专用知识的获取与跨模态公共知识的保留间的冲突,进而限制了持续学习场景下平衡不同模态中行人鉴别性知识的能力。
针对这一问题,北京大学彭宇新教授团队提出了跨模态知识解耦与对齐的可见光-红外终身行人重识别方法CKDA,通过跨模态通用提示模块与单模态专用提示模块显式地解耦并净化不同模态通用与特定模态专用的鉴别性信息,从而避免二者间的相互干扰,并在一对彼此独立的模态内与模态间特征空间中分别对齐解耦后的新旧知识,实现跨模态知识的高效权衡。
本文提出的CKDA方法在四个常用可见光-红外行人重识别数据集组成的终身行人重识别基准上均取得了当前最优的性能。

论文链接:http://arxiv.org/abs/2511.15016
代码仓库:https://github.com/PKU-ICST-MIPL/CKDA-AAAI2026
实验室网址:https://www.wict.pku.edu.cn/mipl
背景与动机
终身行人重识别旨在通过持续学习学习采集自不同场景的行人数据,实现不同场景中同一行人的识别。随着实际场景中白天与黑夜的数据被持续采集,终身行人重识别算法通常需要匹配出现在白天可见光图像和夜晚红外图像中的同一行人,即可见光-红外终身行人重识别。
为了缓解可见光与红外模态知识的遗忘,现有方法大多借助数据重放、模型参数隔离、以及知识蒸馏策略实现跨模态知识的保留。
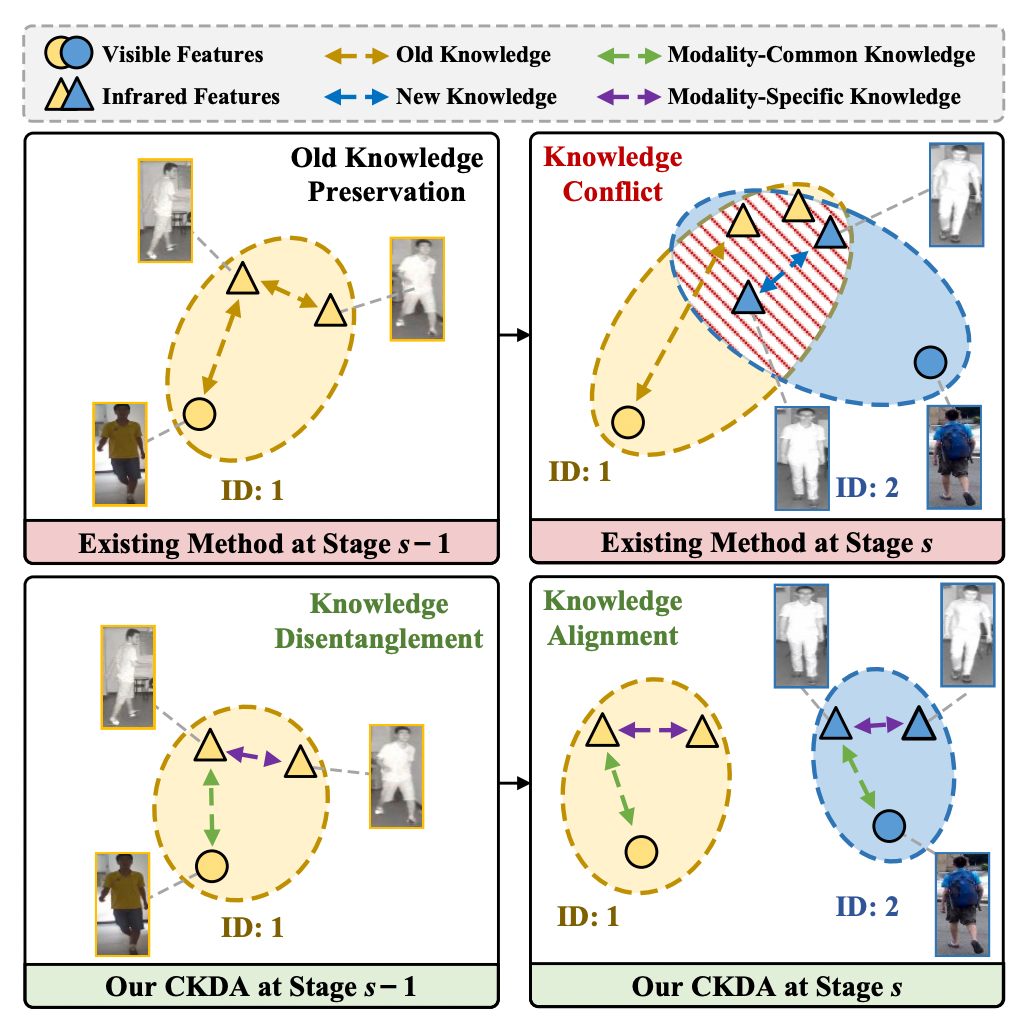
图1现有终身行人重识别方法和本方法的对比示意图
然而,现有方法忽略了单模态专用知识获取与跨模态通用知识保留间的冲突,进而导致了跨模态知识难以平衡。
具体而言,如图1所示,在持续学习新增可见光与红外数据时,现有方法由于不断地累积特定模态中的新知识(例如:仅适用于红外模态中的热辐射信息),不可避免地阻碍了模态间公共的旧知识(例如:同时适用于可见光与红外模态的人体体态信息)的保留,导致了单模态专用知识的获取与跨模态间公共知识的保留间的冲突,限制了持续学习场景下平衡跨模态鉴别性知识的能力。
技术方案
针对上述挑战,本文提出一种跨模态知识解耦与对齐方法CKDA,其核心思想在于避免可见光与红外模态中知识的互相干扰,实现跨模态知识的高效平衡。
如图2所示,CKDA主要包含三个模块:
跨模态通用提示:通过去除仅存在于可见光或红外图像的风格信息,提取在两种模态中共存的鉴别性知识,为跨模态知识对齐奠定基础;
单模态专用提示:通过放大可见光-红外模态间的差异,促进特定模态知识的保留与净化,从而显式地避免可见光与红外模态中行人鉴别性知识的相互干扰;
跨模态知识对齐:利用旧知识原型构建了一组相互独立的模态内与模态间特征空间并分别对齐解耦后的新旧知识,提升了终身行人重识别模型对可见光-红外行人鉴别性知识的平衡能力。
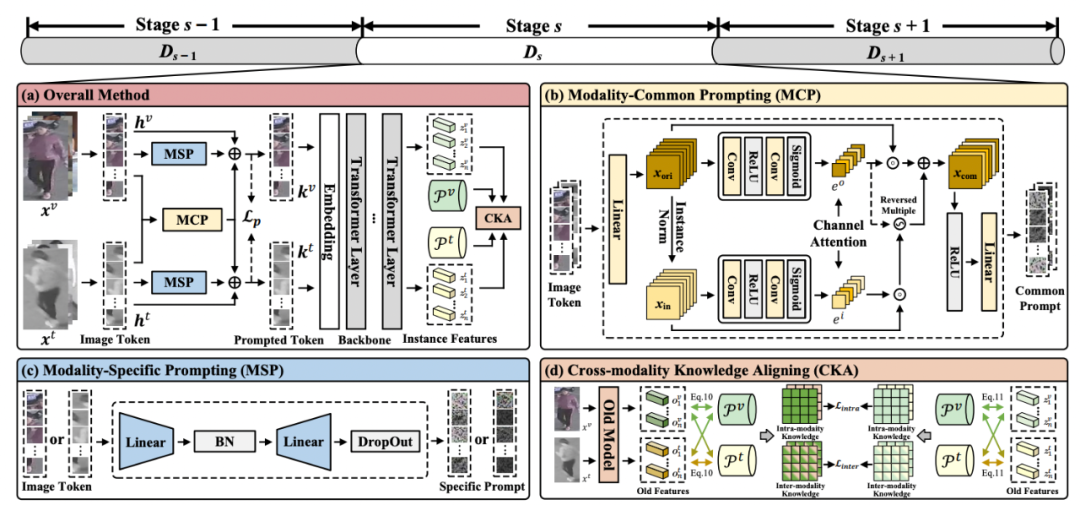
图2跨模态知识解耦与对齐方法(CKDA)框架图
模块1:跨模态通用提示
首先,具体而言,给定输入图像
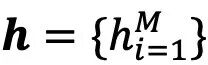
,并将每个图像块映射为一个d维的嵌入特征:
,先将其划分为M个图像块

其中,
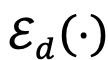
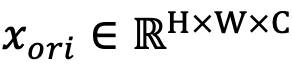
,并采用实例归一化缓解不同模态图像间的风格差异,并得到归一化的特征
重排为特征图
表示图像块的嵌入层。然后,将
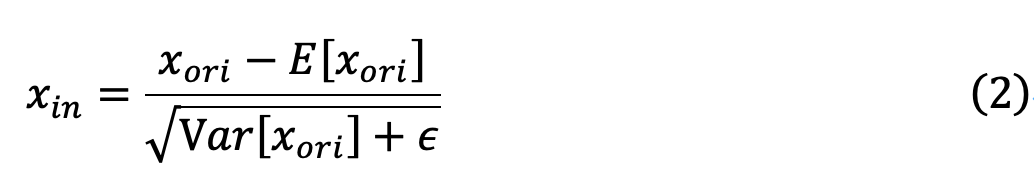
其中,ϵ用于避免除零问题,

和
计算得到:
间的跨模态通用知识分布可以通过生成的两个通道注意力
和
分别表示通道均值与方差。随后,
和
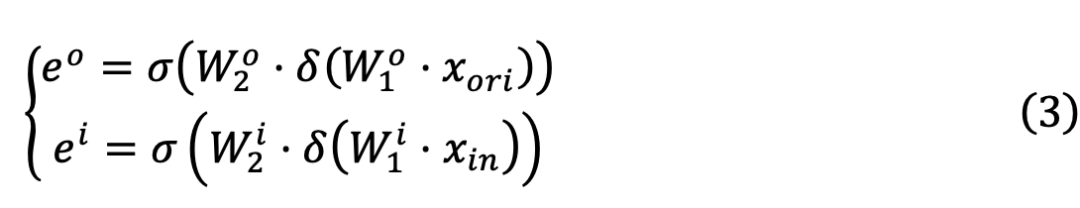
其中,
进一步提升跨模态通用知识的鉴别性与一致性:
和
为可学习参数。接着通过自适应地融合
,
和
表示ReLU与Sigmoid激活函数,
和
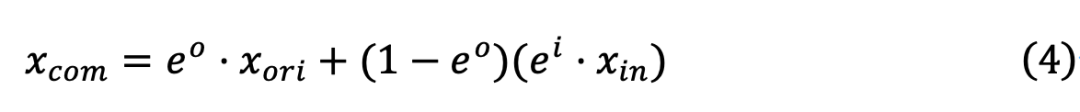
其中,
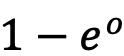
中模态公共知识的重要性对鉴别性信息进行动态补充。
则根据原始特征
表示在消除模态差异后跨模态通用知识的重要程度,而
最后,将得到的通用提示恢复输入维度,从而生成跨模态通用提示
与原始特征图对齐,并通过基于图像特征块划分得到的

其中,
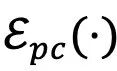
表示特征嵌入恢复层。
模块2:单模态专用提示
给定可见光或红外模态的图像块
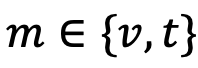
可以由如下方式计算得到:
表示可见光或红外模态,单模态专用提示
,其中,
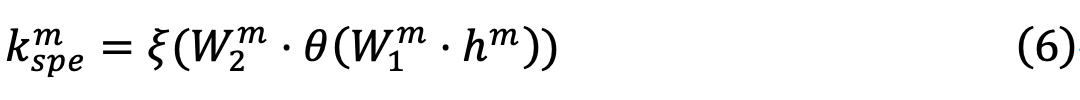
其中,
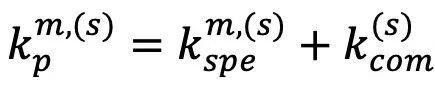
,即:
表示阶段s生成的图像提示,其优化目标为最小化提示损失
为可学习参数。接着,令
,
表示dropout层,
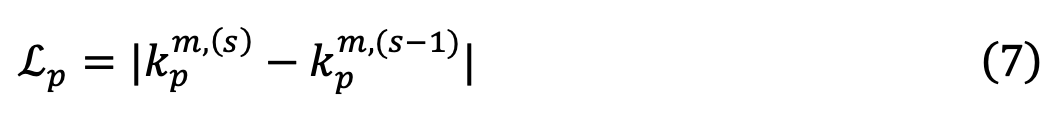
模块3:跨模态知识对齐
令
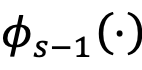
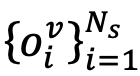
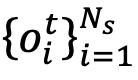
来构建旧的模态间特征空间O(以可见光模态到红外模态为例),其计算过程如下:和红外样本特征提取的当前可见光样本特征提取的旧数据的可见光和红外特征中心。然后利用由分别表示由与
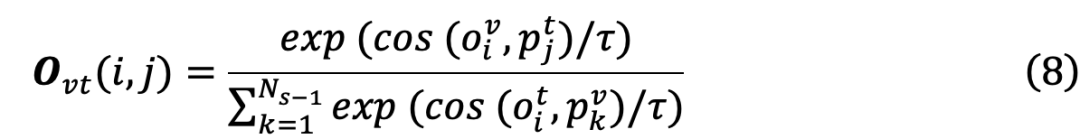
然后,进一步利用当前模型提取的可见光特征
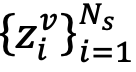
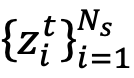
来表示获取新知识后的知识分布Z:
和红外特征
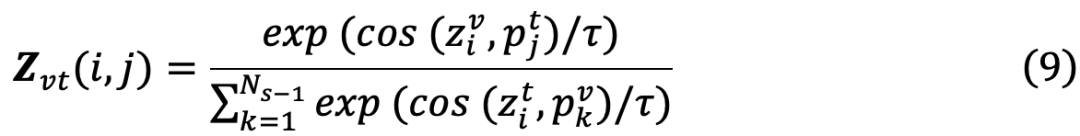
最后,为了缓解模态间及模态内知识的灾难性遗忘,采用

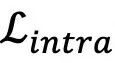
来对齐不同模态与相同模态样本间的相似度:
和
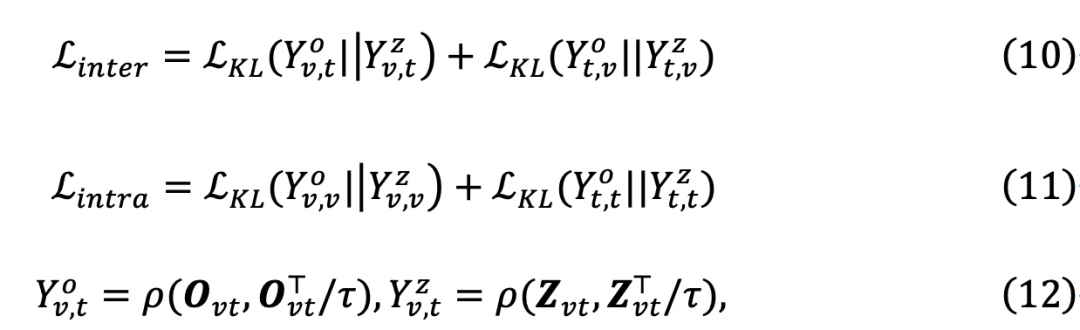
其中,
为Softmax函数。
实验结果
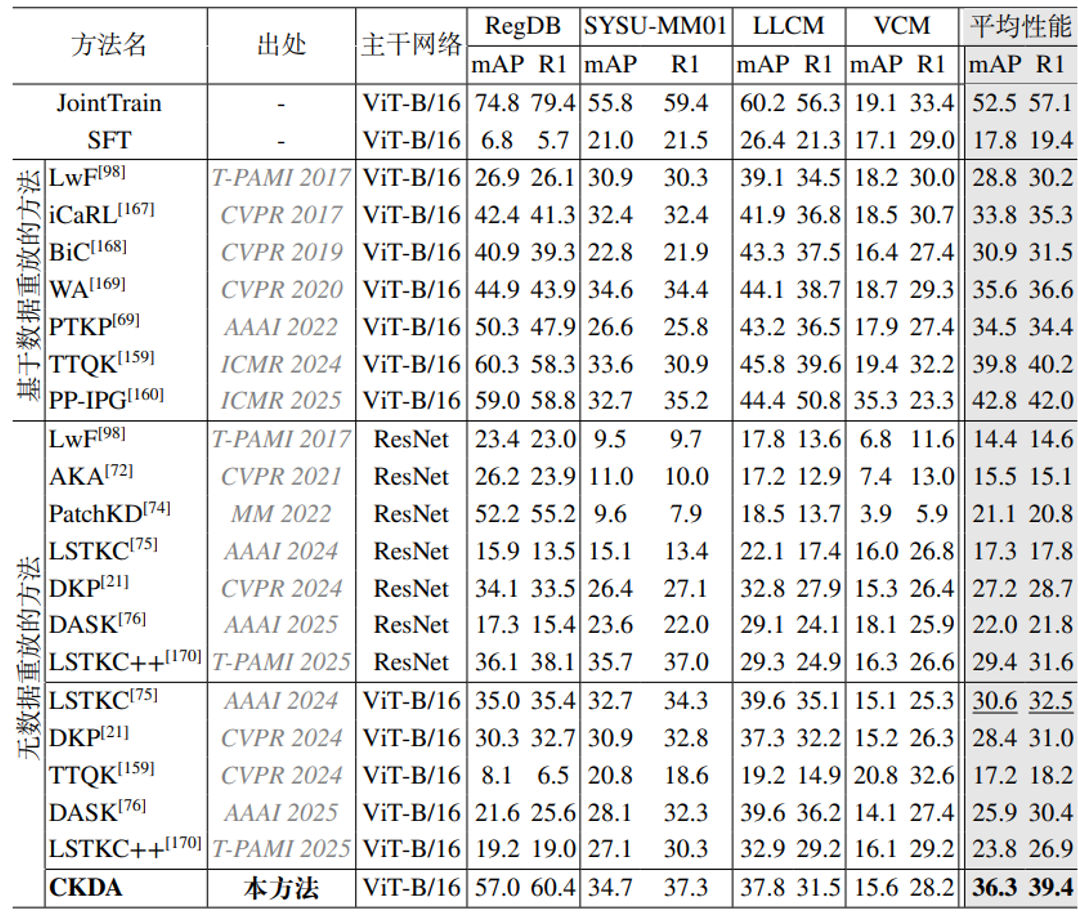
表1本方法与现有方法在可见光-红外终身行人重识别任务中的性能对比
表1的实验结果表明,CKDA方法在由4个常用可见光-红外行人重识别数据集组成的终身行人重识别基准上均达到了当前最优的性能,分别达到了36.3%和39.4%的平均mAP和R1准确性。
图3的可视化结果表明,跨模态通用提示更倾向于关注在两种模态中共存的行人整体轮廓和体态信息。相比之下,单模态专用提示则关注仅存在于特定模态中的知识,例如可见光图像中行人服装颜色或红外图像中的热敏信息。
因此,组合后的可见光图像与红外图像提示能够以互补方式提升模型对可见光与红外模态信息感知与保留能力。
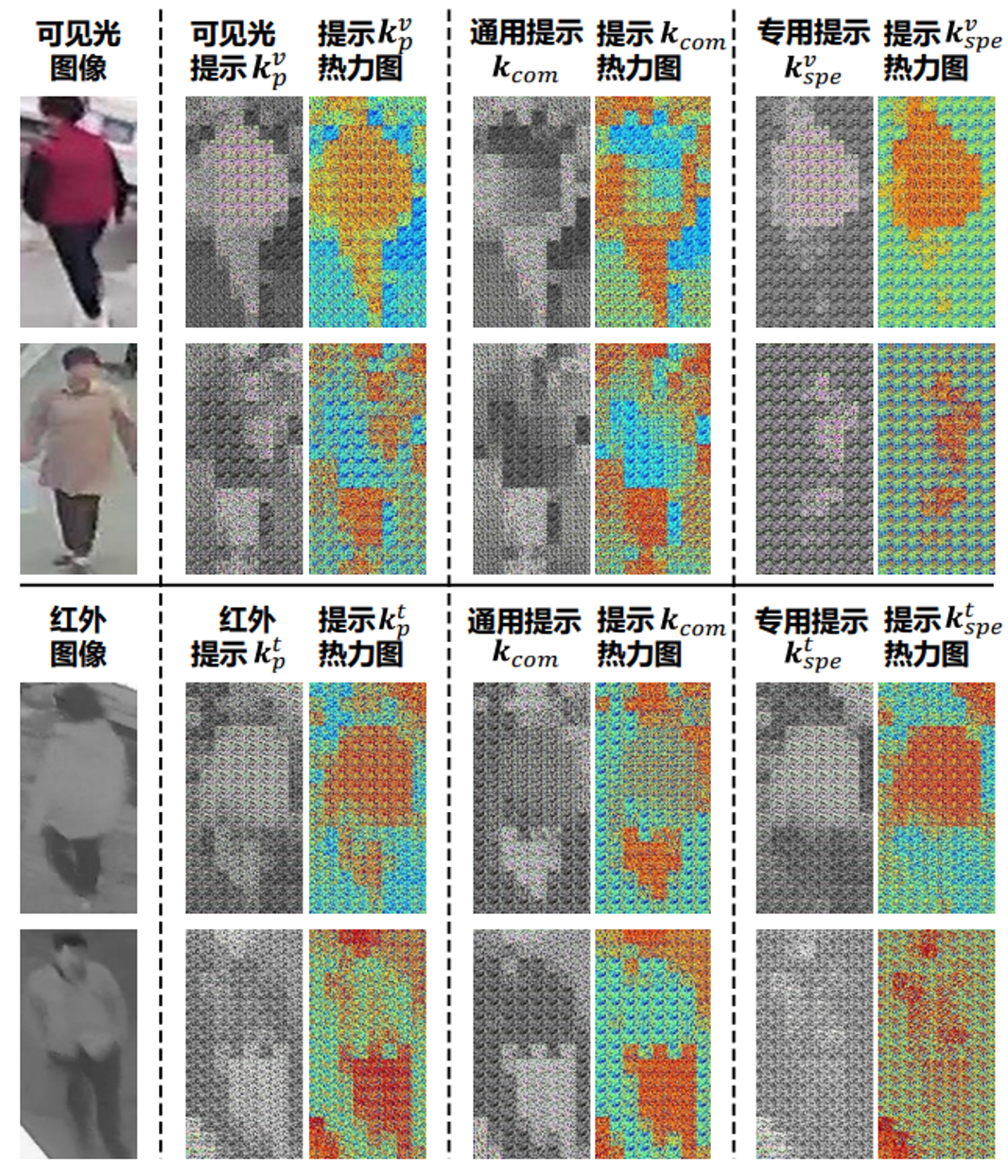
图3不同模态图像生成提示的可视化结果
更多详情,请参见原论文。
作者信息
崔振宇,男,北京大学王选计算机研究所2021级博士研究生,导师为彭宇新教授,研究方向为多媒体智能计算与机器学习。获得研究生国家奖学金,北京大学博士研究生校长奖学金,ACM-ICPC亚洲区域赛银牌等奖励。在CVPR,AAAI,TIFS,TCSVT等IEEETrans./CCFA类期刊与会议上发表十余篇论文,其中第一作者7篇。常年担任国际会议CVPR、ICCV、NeurIPS、ICLR、ECCV等多个重要国际会议,以及IEEETIP、TIFS、TCSVT、TMM等多个重要国际期刊的审稿人。