[CL]《CDE: Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models》R Dai, L Song, H Liu, Z Liang... [Tencent AI Lab] (2025)
Curiosity-Driven Exploration(CDE)为强化学习优化大型语言模型(LLMs)中的推理能力提供了突破。
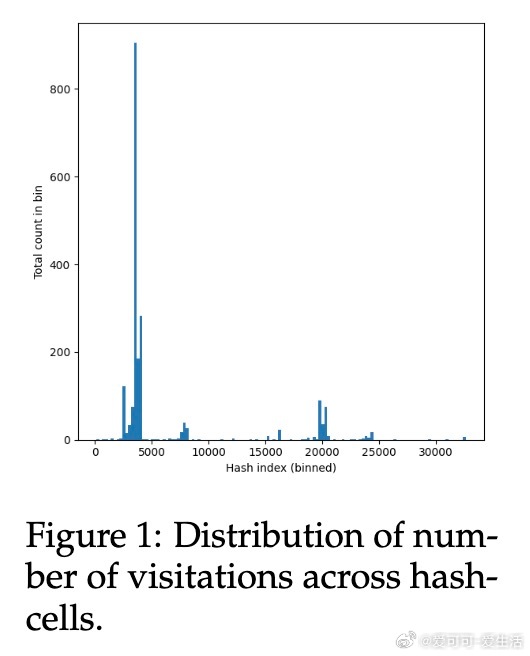
• 解决传统RLVR探索不足导致的早熟收敛与熵崩溃问题,提升训练稳定性和效果。
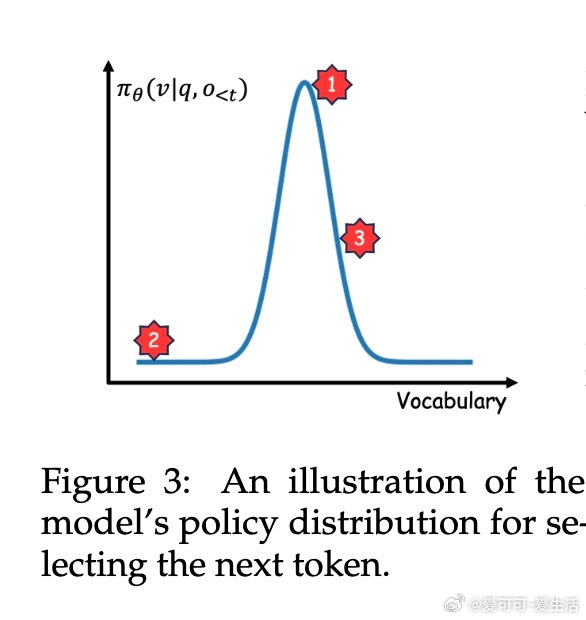
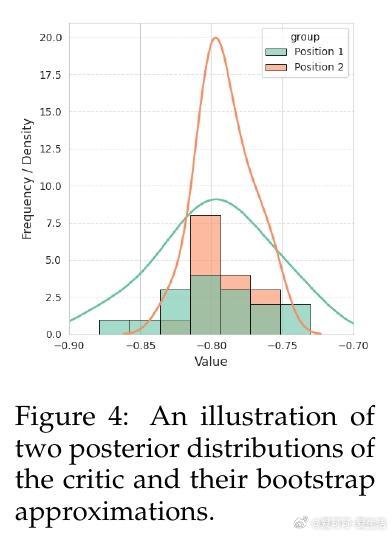
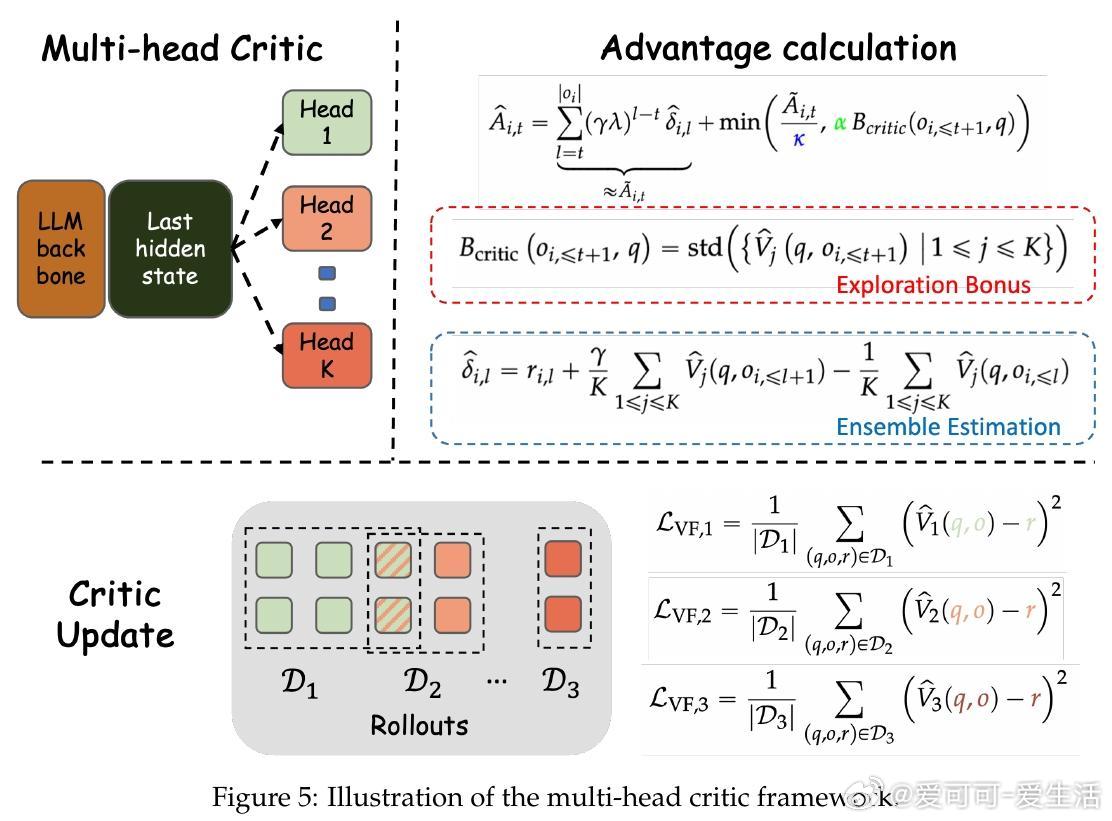
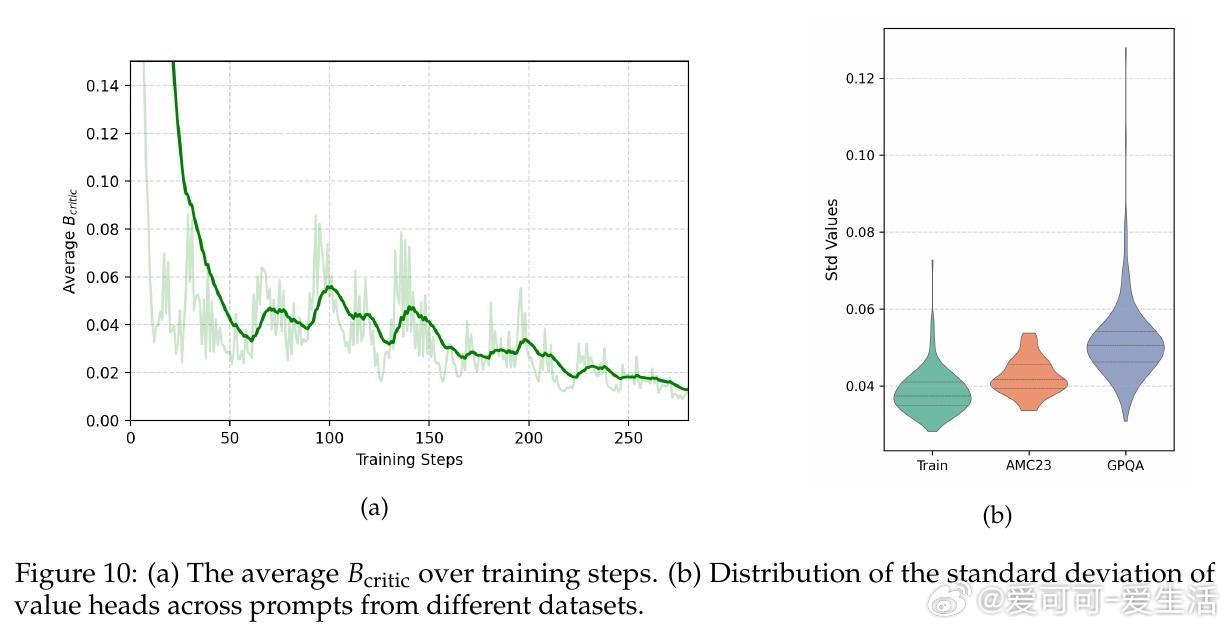
• 利用模型内在好奇心驱动探索:演员端以生成文本的困惑度(PPL)衡量惊讶度,批评者端采用多头架构估计价值函数方差,双重好奇信号作为探索奖励引导策略更新。
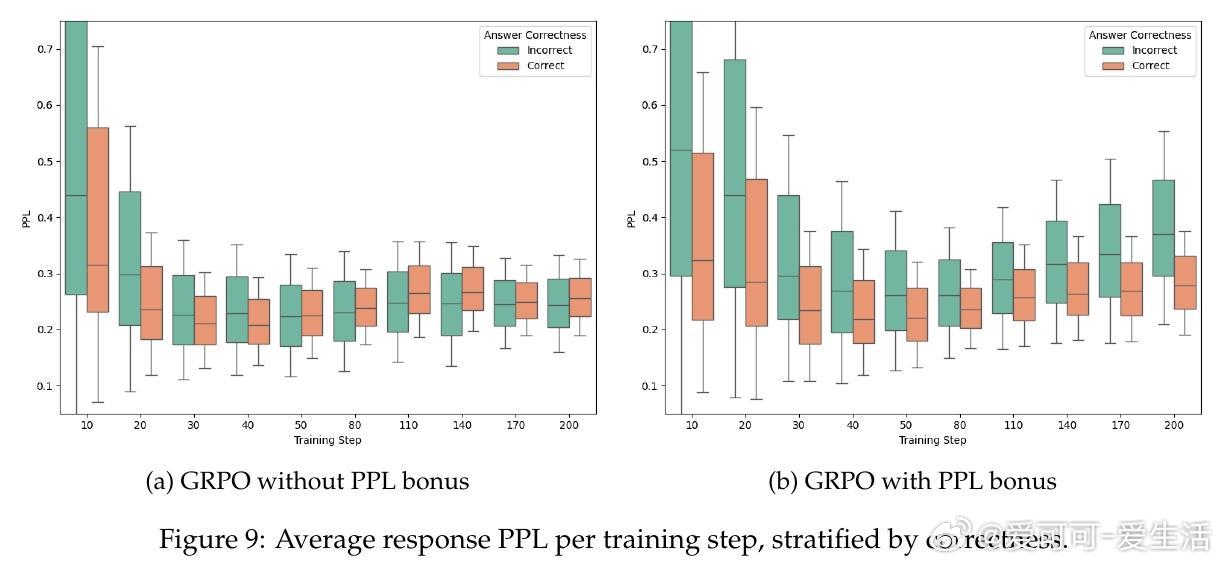
• 理论证明PPL奖励自动惩罚过度自信的错误并鼓励多样性正确答案;多头价值方差奖励在线性MDP中等价于经典基于计数的探索奖励。
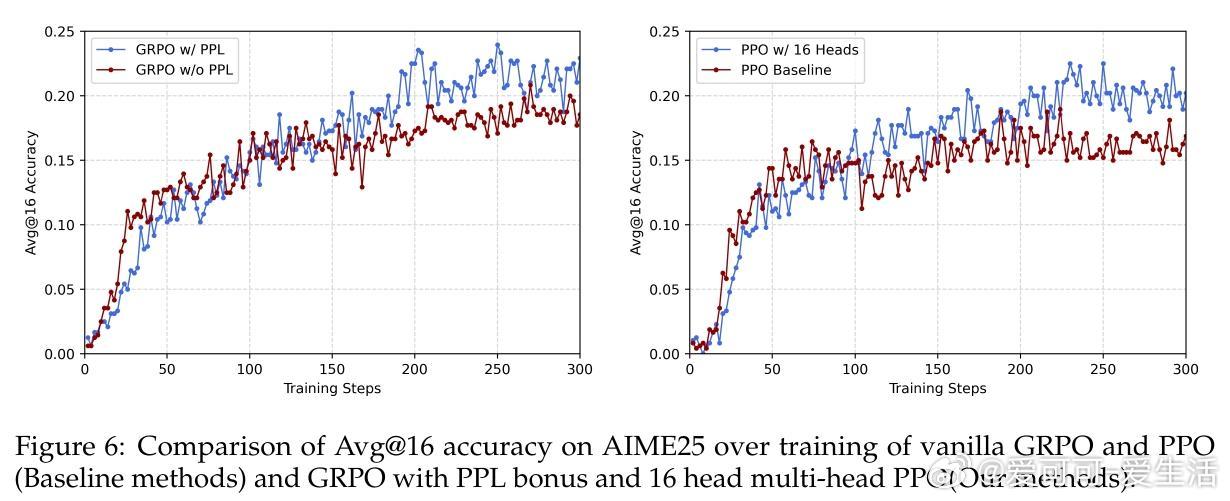
• 实验覆盖四大数学推理基准(AIME25/24、AMC23、MATH),GRPO/PPO结合CDE平均提升约3个百分点,显著缓解RLVR中的“校准崩溃”现象,提升模型置信度与准确率的一致性。
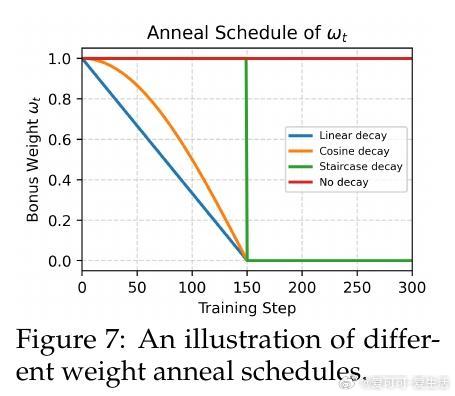
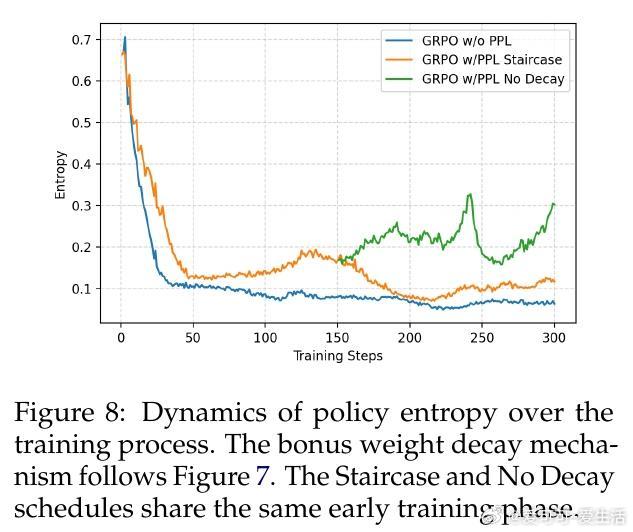
• 奖励衰减策略关键:阶梯式衰减在训练早期保持强探索,后期迅速收敛效果最佳,防止过度探索影响质量。
• 多头批评者(4至16头)显著增强探索能力,尤其在复杂任务中提升多样性和泛化,且训练表现稳定,样本效率高。
• CDE框架轻量且易集成,无需额外复杂模块,兼容现有RLVR算法,具备广泛应用潜力。
心得:
1. 内在好奇心作为探索奖励更适合高维长推理轨迹的LLM,突破了传统计数方法的维度诅咒和表达力限制。
2. 精细设计的探索奖励不仅提升性能,更能改善模型的置信度校准,增强推理结果的可靠性和解释性。
3. 训练过程中的奖励权重动态调整至关重要,合理衰减能平衡探索与利用,防止训练陷入局部最优。
详细阅读🔗arxiv.org/abs/2509.09675
强化学习大型语言模型探索策略推理能力人工智能