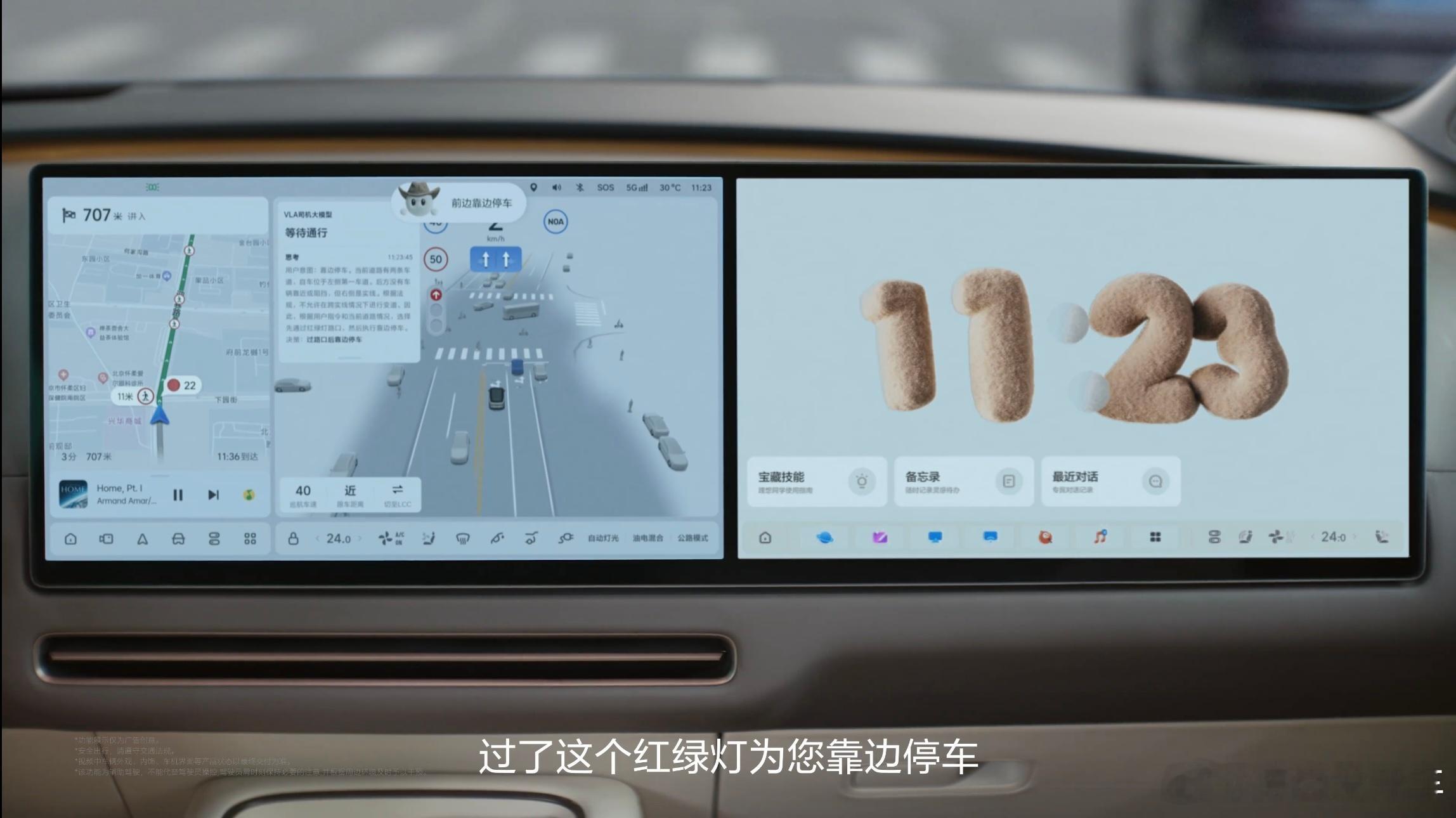
理想最新的VLA司机大模型,思考推理过程包括理解用户意图并输出决策,
以广告片截图中靠边停车场景为例:
- 用户意图:靠边停车。
当前道路有两条车道,自车位于左侧第一车道。
后方没有车辆靠近或阻挡,但右倒是实线。
根据法规,不允许在跨实线情况下进行变道。
因此,根据用户指令和当前道路情况,
选择先通过红绿灯路口,然后执行靠边停车。
- 决策:过路口最靠边停车
————————
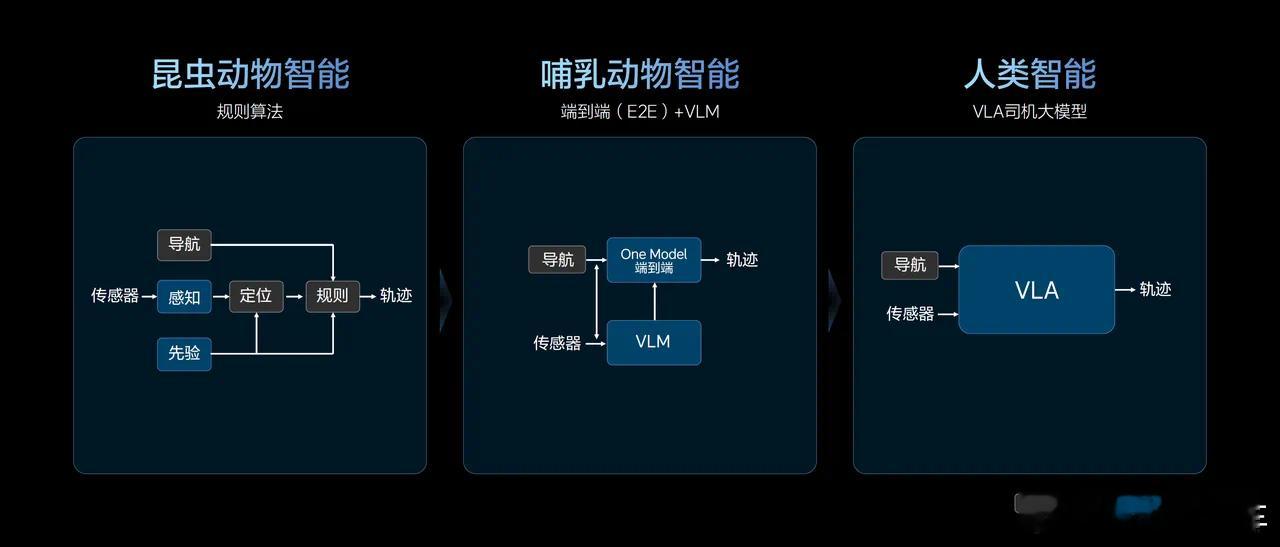
这背后是理想重新设计的VLA大模型各个模块,而不再是此前的端到端+VLM并联协同方案,
理想VLA从底层构建了全新基座模型,采用MoE架构与稀疏注意力技术,实现智能「按需唤醒」,兼顾大模型能力与端侧效率。
空间编码器通过语言模型与逻辑推理进行空间理解,并结合Diffusion预测优化驾驶轨迹。
模型通过RLHF学习老司机式习惯,提升安全与博弈能力,最后用户只需一句话,VLA即可完成全场景智能驾驶操作,实现自然交互。
理想汽车[超话]理想i8理想VLA司机大模型