【对标DeepSeek,MiniMax发布M1模型】
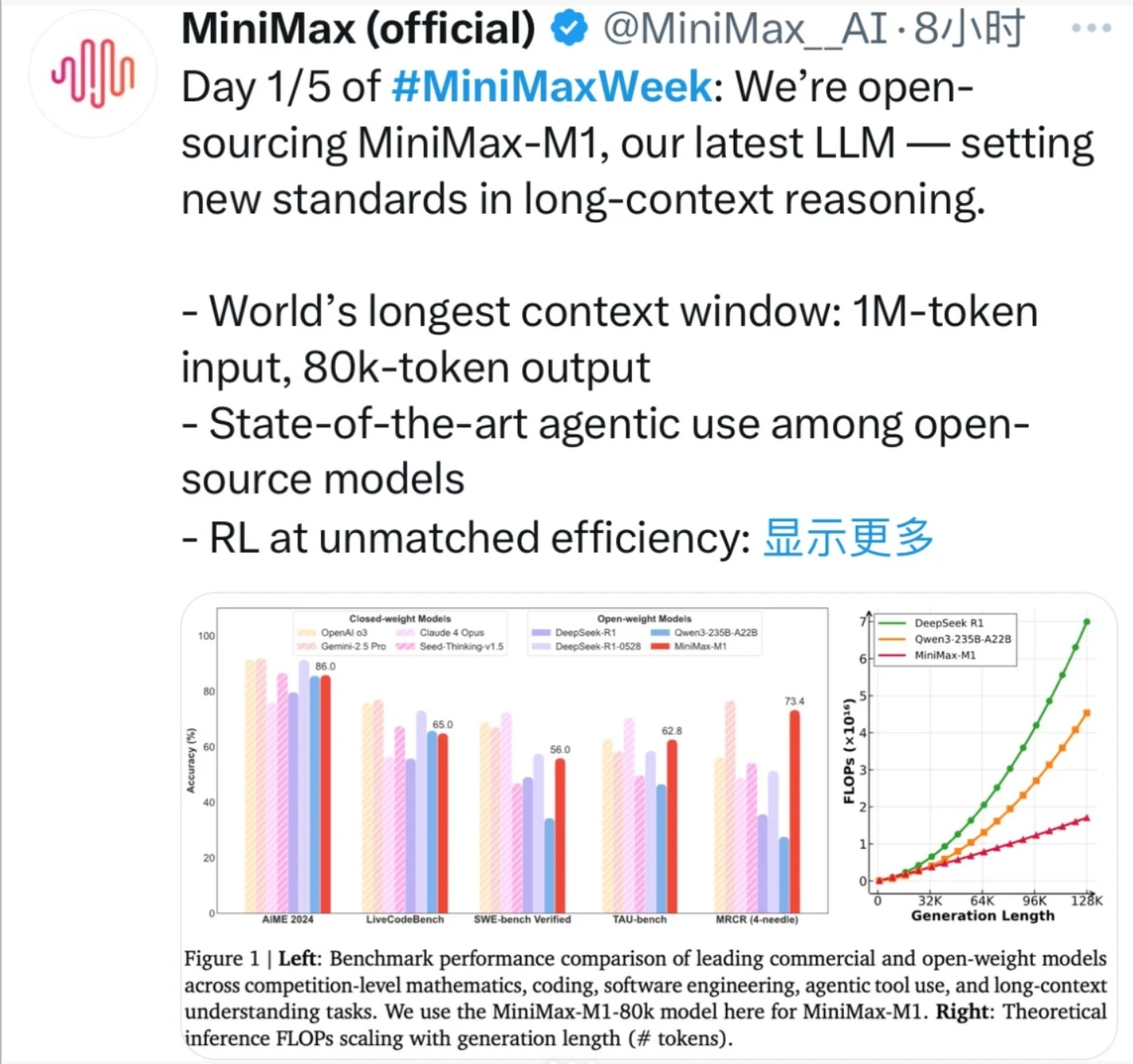
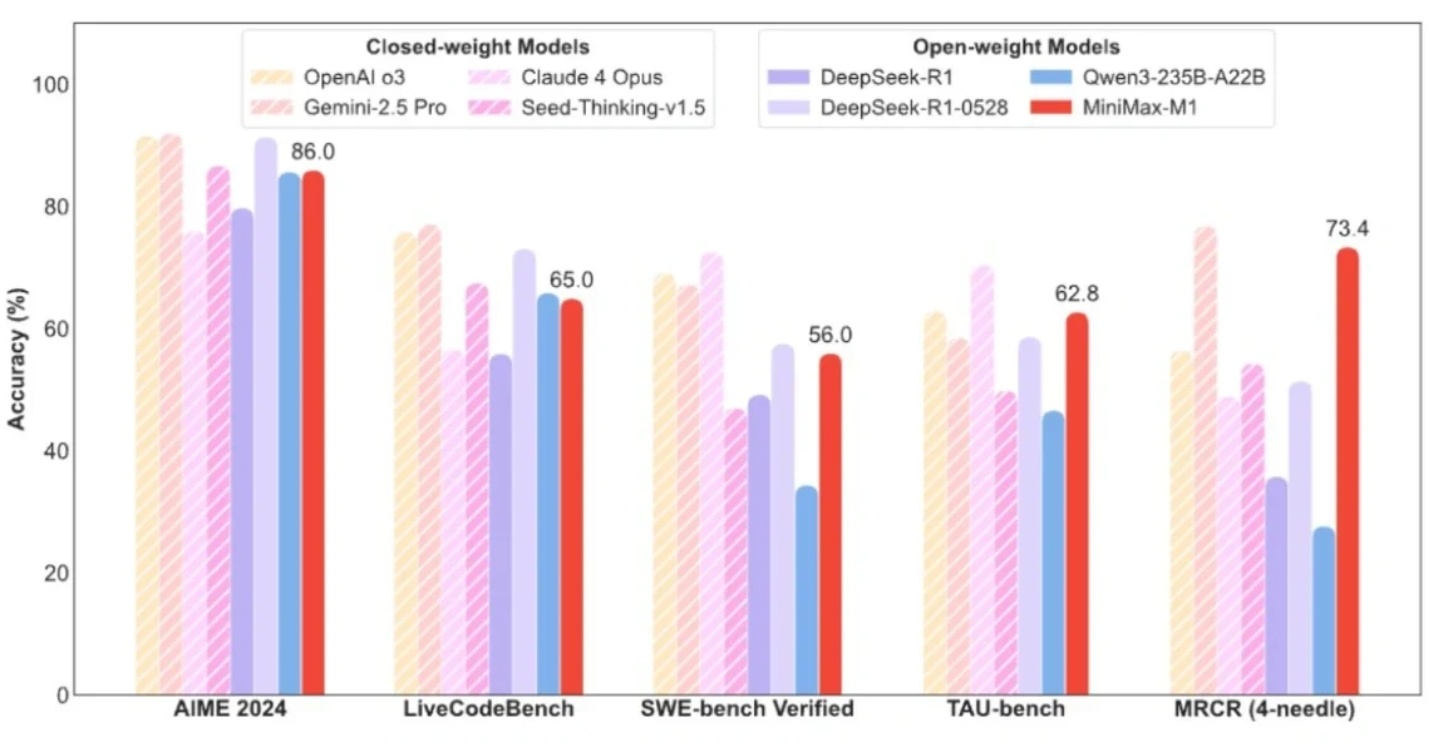
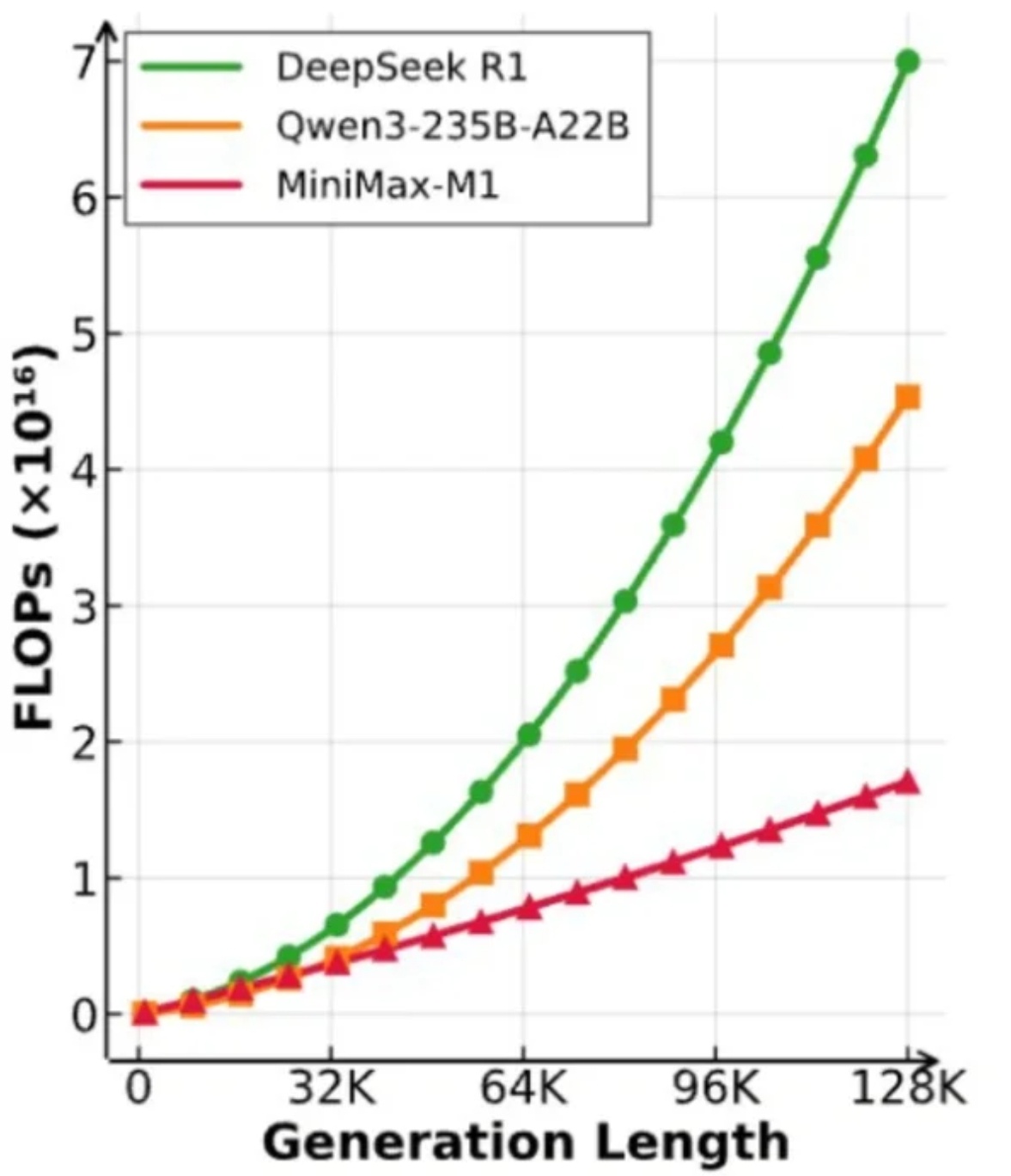
MiniMax今日发布首个推理模型 M1,亮点在于极致的性价比:M1生成100K token时,算力成本仅为DeepSeek R1的25%;整轮RL训练仅用512张H800、花了不到54万美元——官方称“比原预期少一个数量级”。
这要归功于其MoE架构+Lightning Attention:参数总量4560亿,但每token仅激活459亿,可支持100万Token上下文,和Gemini 2.5 Pro并列“上下文最长”。
MiniMax这次明显是奔着成本优势来的,看得出国内大模型竞争已经开始比谁跑得更稳、跑得省。M1主打超长上下文+极致低成本,这种组合在To B推理和 AI 工具类落地场景里的优势更明显了。ai