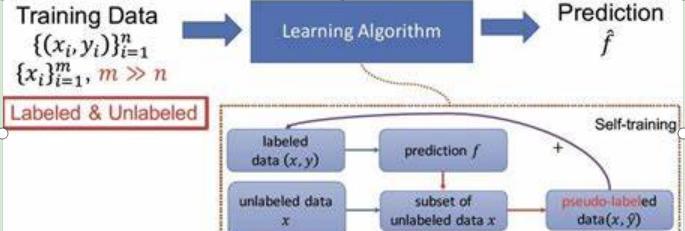
SSB方法的成功,从根本上改变了我们对开放集半监督学习的理解。它不再将"离群"样本视为敌人,而是潜在的朋友,这种思想转变带来了多方面的优势。 传统观念认为,"离群"样本会干扰分类器训练,应该被过滤掉。但SSB证明,如果使用得当,这些样本实际上可以提升分类性能。在CIFAR-10实验中,当使用一个理想的"离群"样本过滤器(只保留真正的正常样本)时,分类准确率反而从91.65%下降到88.28%。这意味着那些被高置信度分类的"离群"样本确实对模型训练有益。 为什么会这样?通过可视化分析发现,很多被高置信度分类的"离群"样本与对应的正常类别有很高的视觉相似性。例如,在CIFAR-100数据集上,被分类为"海洋"类的高置信度"离群"样本大多包含海景背景;被分类为"狼"类的样本展示了类似狼的动物。这些样本实际上丰富了训练数据的多样性,就像自然产生的数据增强,有助于提高模型的泛化能力。 SSB的设计还体现了极高的灵活性。通过非线性投影头分离特征空间,SSB允许分类器和检测器各自优化,不再相互干扰。这种灵活性使得SSB可以与各种半监督学习算法和开放集方法结合,产生协同效应。 比如,当与FlexMatch结合时,在CIFAR-10数据集上,SSB在保持FlexMatch原有分类准确率的同时,将异常检测性能提升了近20个百分点。反过来,当与OpenMatch结合时,不仅提升了检测性能,还改善了分类准确率。这种通用性使SSB成为一种"即插即用"的解决方案,可以轻松整合到现有系统中。 SSB的另一大优势是其简单性。相比其他需要复杂训练策略或精细调参的方法,SSB的核心思想清晰明了:基于置信度的伪标签、非线性特征分离和伪负样本挖掘。这种简单性不仅易于理解和实现,还降低了计算负担。在CIFAR-10上的实验表明,SSB的训练时间与标准半监督学习方法相当,远低于一些复杂的开放集方法。 尽管取得了显著成功,SSB仍有改进空间。一个主要局限是对未见"离群"样本的检测性能。在多个数据集上,SSB在检测训练中见过的"离群"样本时表现优异,但面对全新的"离群"样本时性能会下降。在CIFAR-10实验中,SSB对见过的"离群"样本的AUROC为96.82%,而对未见"离群"样本的AUROC为92.70%。 这种性能差距暗示模型存在过拟合风险。为了解决这个问题,未来的研究可以探索更强的正则化技术,或者引入更多样化的"离群"样本进行训练,以提高对未见异常的泛化能力。 另一个值得关注的方向是在长尾分布场景下的应用。现实世界中,数据通常呈长尾分布,某些类别的样本极少。SSB在处理这种不平衡数据时可能面临挑战,因为尾部类别的样本稀少,很难区分它们与"离群"样本。未来的工作可以考虑结合长尾学习技术,提高SSB在这类场景下的鲁棒性。 除了这些技术挑战,SSB的思想也可以扩展到其他领域。比如,在自动驾驶中,识别道路上的未知障碍物;在医学影像分析中,检测罕见的疾病表现;在网络安全中,识别新型的攻击方式。这些应用都需要同时具备准确的分类能力和有效的异常检测能力,正是SSB的强项。