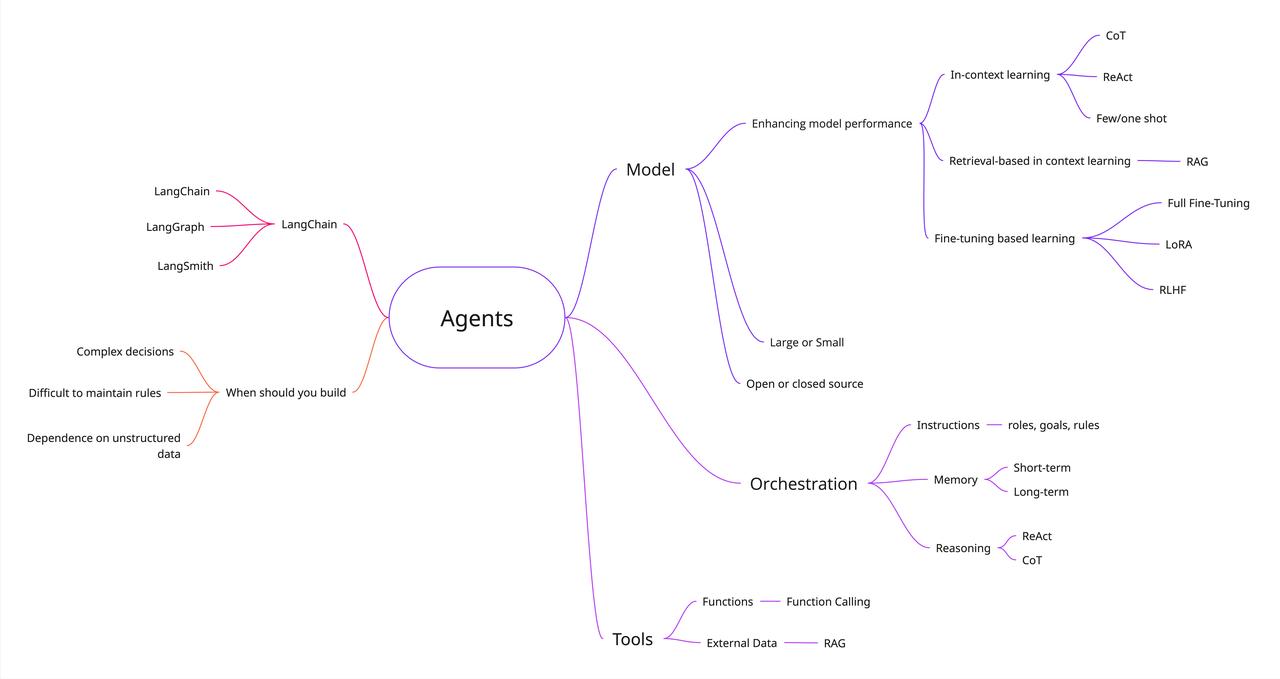
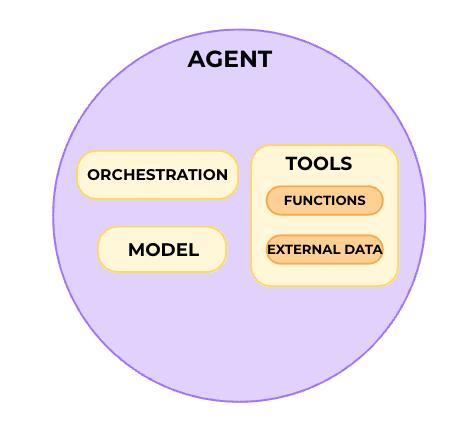
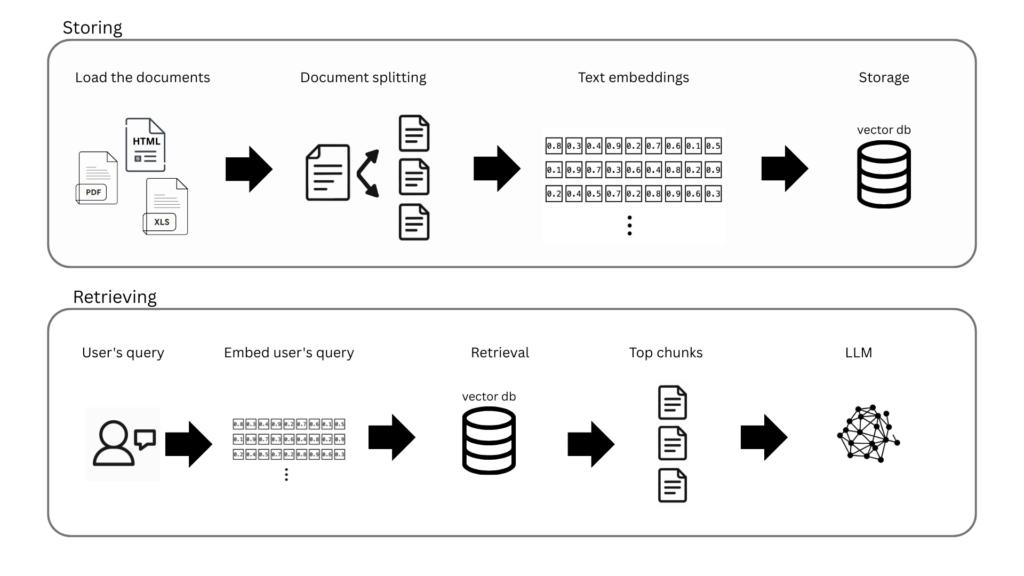
在2025年,想要开始入门LLM? 浩瀚的互联网内容,可能会让人不知所措。这篇文章提供了一份体系化的LLM指南,能够帮助你更快了解LLM【图1】 一、智能体 关于智能体的定义有很多,核心在于:自主运行以执行任务、决策后续行动方案、调用工具达成目标。 一个智能体的关键组成部分包括:模型、指令/编排和工具集。接下来,我们逐一探讨 二、模型 这里主要指驱动智能体的语言模型: 大语言模型:拥有数千亿甚至数万亿参数,需在海量数据上训练,消耗巨大计算资源。 小语言模型:专注于特定任务,在较小数据集上训练,平衡了性能与资源效率。 三、指令/编排 指令是智能体行为的指导原则与防护机制。为应对复杂场景,智能体常需编排,包含三个层级: 指令:设定模型目标、角色、行为规则及其他优化信息。 记忆:通过提示词(prompt)传递给模型的上下文内容。 短期记忆:模型在交互过程中能够获取的即时上下文信息 长期记忆:突破上下文窗口限制,通常会通过外部存储机制调用的重要信息。 基于模型的推理/规划:推理技术,结构化地获取信息、执行内部推理并做出决策。 思维链(CoT):要求模型逐步生成解释或推理过程,避免跳过中间步骤导致推理失误。 ReAct:使智能体能对用户查询进行推理并采取行动,持续循环直至任务完成。 四、工具 借助工具,模型可以与外部系统交互,并获取训练数据以外的知识。 函数和函数调用:函数是可重复使用的代码模块。模型根据预定义函数的规格说明,判断何时使用及所需参数,但不自行执行函数。你需另外编写代码来实际执行这些函数。 外部数据:无需重新训练或微调模型,即可提供额外数据。最常见的途径之一是通过检索增强生成(RAG):【图3】 检索(Retrieval):LLM接收查询时,RAG系统从外部知识源搜索并获取相关信息。 增强(Augmented):将检索到的相关信息整合到原始提示中,形成增强版输入。 生成(Generation):LLM基于原始提示和新增的检索上下文,生成最终回答。 五、增强模型性能 上下文学习:直接在提示词中提供示例,无需改变模型底层权重,即可“教会”模型执行任务。 基于检索的上下文学习:模型检索外部上下文(如文档),并将其添加到提示中,以增强响应。 基于微调的学习(Fine-tuning based Learning):在特定数据集上进一步训练模型,使其“内化”新的行为或知识。这包括全参数微调、LoRA和RLHF等方法。【图4】 六、LangChain 的作用是什么? LangChain是一个专为简化基于大语言模型应用开发而设计的框架,包含: LangChain :作为LLM的基础连接层,它支持无缝切换不同服务商或组合功能模块,无需修改底层代码,同时还能简化整体代码结构。 LangGraph: 专注于智能体工作流的构建、部署与管理 LangSmith: 提供LLM应用的调试、测试及监控能力 原文链接:-to-llms-start-here/