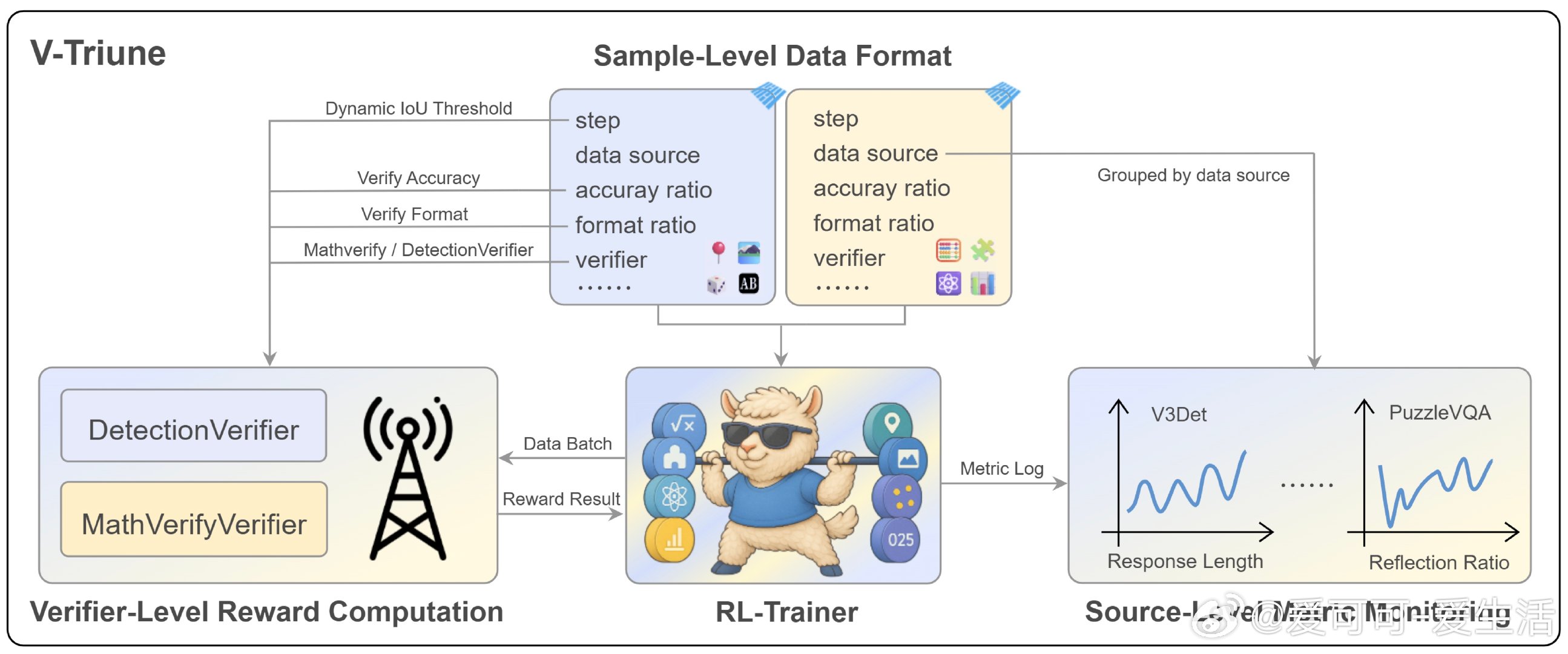
【[20星]One-RL-to-See-Them-All:让视觉语言模型在单一训练框架中同时掌握视觉推理和感知任务。亮点:1. 首个统一的强化学习框架,支持8种任务(4推理+4感知);2. 性能大幅提升,最高提升14.1%;3. 创新动态IoU奖励机制,增强模型稳定性】
'One RL to See Them All: Visual Triple Unified Reinforcement Learning'
GitHub: github.com/MiniMax-AI/One-RL-to-See-Them-All
视觉语言模型 强化学习 多任务训练 AI创造营