其实在年初的时候,就有群友队于VLA做了一个预测(图一),八九不离十(万能的群友[种树])
讲几个感兴趣的点:
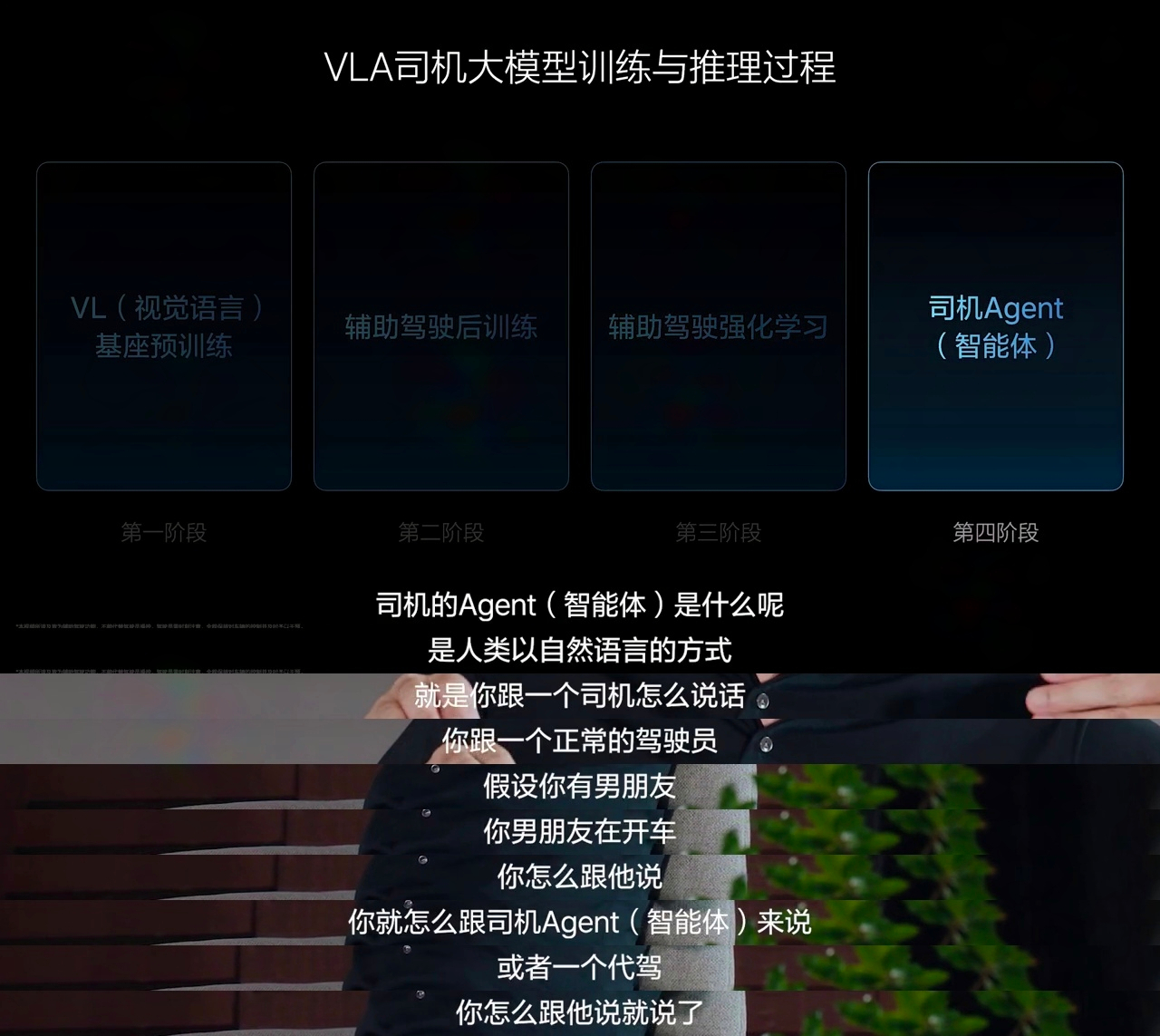
①整个VLA模型的推理过程其实已经讲的很清楚了:
第一阶段:对于VL(视觉语言),就是讲收录的信息,进行预训练;
第二阶段:对于Action进行后训;
第三阶段 :强化学习
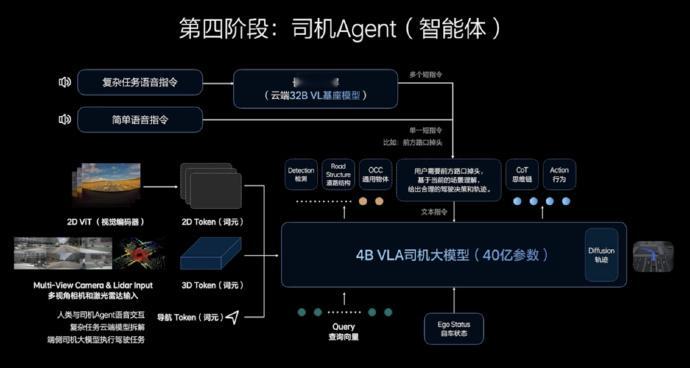
第四阶段:加入Agent(智能体)
②VLA的设计呢就是云端+车端。云端是一个32B参量的模型+车端4B的推理模型
③想哥在AI Talk里说了一个全参量的3.2B的基座VL模型是难以跑通的,是采用了8个专家组成的MoE(混合专家模型),【推测】采用了数据冻结的方式,在遇到对应场景时激活相应的专家库,这样做的好处是,可能只需要跑0.x B的模型(效率完全OK)
④理想的VLA在做完Action后还有一个diffusion的扩散,能做到4~8秒的轨迹和环境预测,这是很夸张的程度。目前普遍的只能跑2~3秒[雪糕][雪糕]
想哥也说了VLA应该是目前能力最强的架构(效率最优?不清楚),其实大家可以看一下。一旦技术路线公布,那么工程落地的效果是可以预测的~期待VLA实车![举手][举手]
理想AI Talk第二季 李想谈辅助驾驶到了新十字路口 李想说当前竞争环境下要练基本功