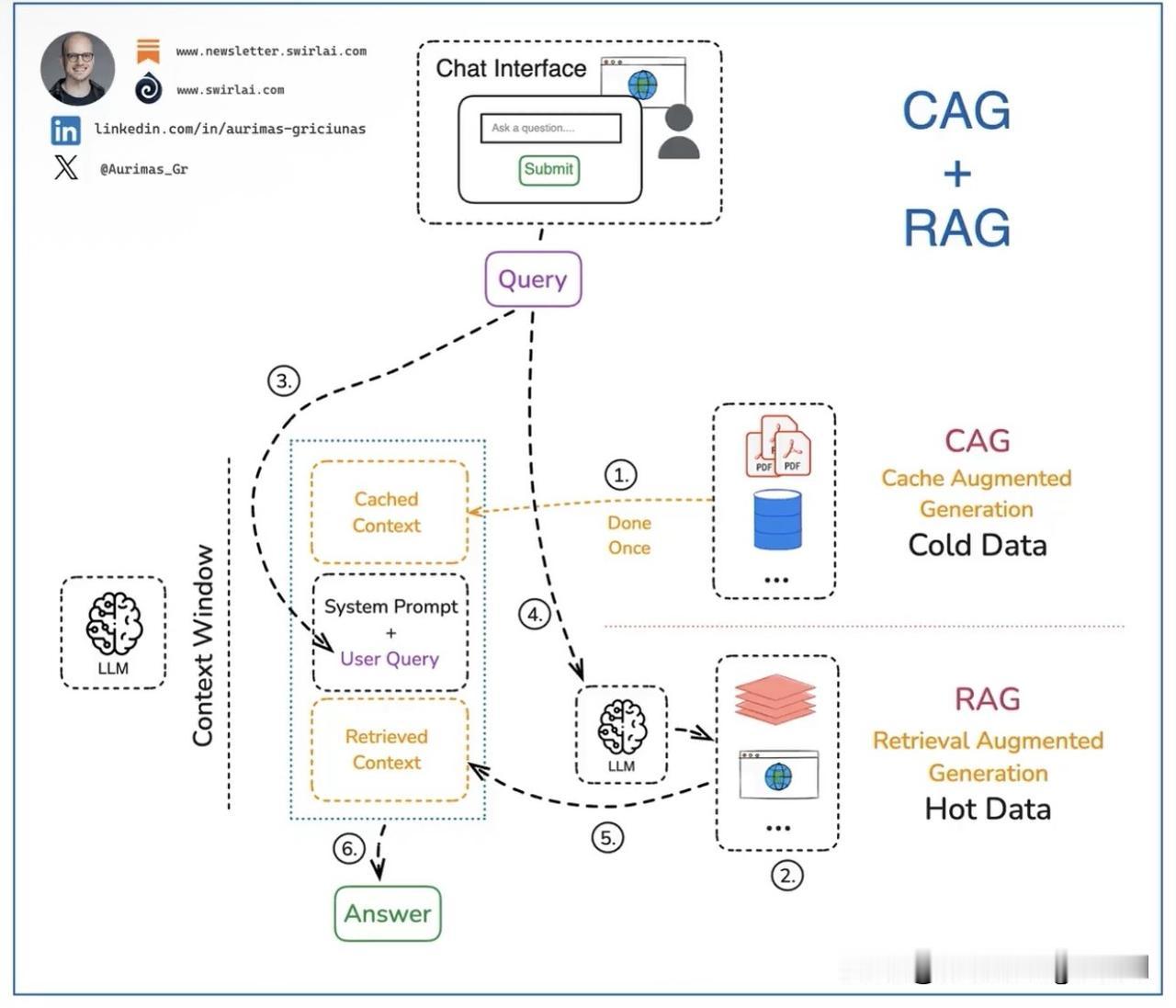
融合𝗥𝗔𝗚 (检索增强生成)和𝗖𝗔𝗚 (缓存增强生成)。作为 AI 工程师,您能从中受益吗? 最近,一种名为 CAG 的技术被大肆炒作。虽然它本身就很强大,但真正的魔力在于将 CAG 与常规 RAG 结合起来。让我们看看它会是什么样子,以及应该考虑哪些其他因素。 以下是实现 CAG + RAG 架构的示例步骤: 𝘋𝘢𝘵𝘢 𝘗𝘳𝘦𝘱𝘳𝘰𝘤𝘦𝘴𝘴𝘪𝘯𝘨 : 𝟭 。我们仅使用很少变化的数据源进行缓存增强生成。除了数据很少变化的要求之外,我们还应该考虑哪些数据源经常被相关查询访问。只有获得这些信息后,我们才会将所有选定的数据预先计算到 LLM 的键值缓存中。并将其缓存在内存中。这只需执行一次,以下步骤可以多次运行,而无需重新计算初始缓存。 𝟮 。对于 RAG,如有必要,预先计算向量嵌入并将其存储在兼容数据库中,以便在步骤 4 中进行搜索。有时,更简单的数据类型对于 RAG 来说就足够了,常规数据库可能就足够了。 𝘘𝘶𝘦𝘳𝘺 𝘗𝘢𝘵𝘩 : 我们现在可以利用预处理的数据。 𝟯编写一个提示,包括用户查询和系统提示,并说明 LLM 应如何使用缓存上下文和检索到的外部上下文。 𝟰嵌入用户查询,用于通过向量数据库进行语义搜索,并查询上下文存储以检索相关数据。如果不需要语义搜索,可以查询其他来源,例如实时数据库或网络。 𝟱 . 利用步骤 4 中检索到的外部上下文来丰富最后的提示。 𝟲 .将最终答案返回给用户。 𝘚𝘰𝘮𝘦 𝘊𝘰𝘯𝘴𝘪𝘥𝘦𝘳𝘢𝘵𝘪𝘰𝘯𝘴 : ➡️上下文窗口不是无限的,即使某些模型拥有巨大的上下文窗口大小,但大海捞针问题尚未解决,因此请明智地使用可用的上下文并仅缓存真正需要的数据。 ✅对于某些业务场景,将特定数据集作为缓存传递给模型非常有价值。想象一下,一个助手必须始终遵守存储在多个文档中的一长串内部规则。 ✅虽然 CAG 最近才在开源领域流行起来,但它已经通过 OpenAI 和 Anthropic API 中的 Prompt Caching 功能实现了一段时间。在那里开始原型设计非常容易。 ✅您应该始终将热数据源和冷数据源分开,仅在缓存中使用冷数据(很少更改的数据),否则数据将变得陈旧并且应用程序将不同步。 ❌请非常小心地对待您缓存的内容,因为所有用户都可以查询这些数据。 ❌除非您有一个单独的模型,并且每个角色都有自己的缓存,否则很难确保缓存数据的 RBAC。 你已经尝试过CAG和RAG的融合了吗?请在评论区分享你的结果👇 AI模型集成