IBM研究员发布新模型Bamba混合架构提升两倍推理速度
既有Transformer的长序列处理能力,又有SSM的运行效率?
IBM研究院在29日发布了Bamba v2,一款基于Mamba-2架构的纯解码器语言模型,旨在处理广泛的文本生成任务,其核心特性即将被整合至IBM Granite 4.0当中。
通过显著降低Transformer键值缓存的内存需求,90亿参数的Bamba模型在保持同等精度下,运行速度可达同类规模Transformer的两倍以上。
Bamba的最初诞生源于Transformer架构固有的“平方级瓶颈”,生成文本的累积成本呈平方级增长。
这不仅造成了模型问答的延迟,同时也造成大量冗余计算。早在2022年ChatGPT普及Transformer时,研究者们就已开始寻找替代架构。
状态空间模型(SSMs)及SSM层与Transformer混合架构,已成为两大潜在解决方案。
2023年,门控SSM变体Mamba2被提出,推动了一系列混合架构的出现。英伟达去年证实,这些新型混合架构不仅能超越单一架构性能,还能大幅提升推理速度。
最新推出的Bamba v2相较v1,新增1万亿token训练数据,性能显著提升。
- 基准测试
在L1和L2基准测试中,Bamba v2的表现超越了训练数据量近5倍的Llama 3.1 8B模型。
配合最新vLLM优化,其推理速度达到同规模Transformer模型的2-2.5倍。
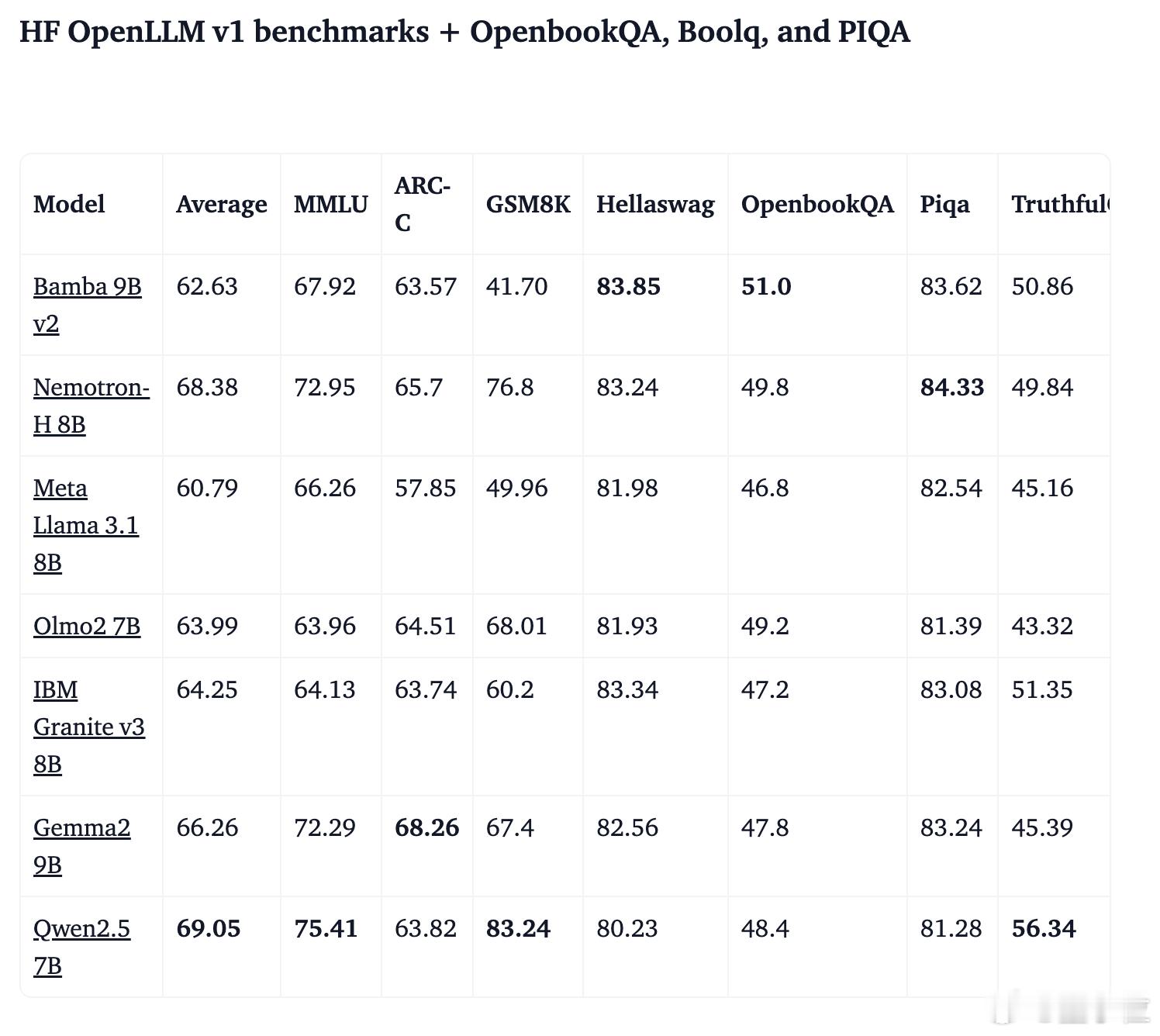
- HF OpenLLM v1 基准测试(含 OpenbookQA、BoolQ 和 PIQA 评测)【图2】
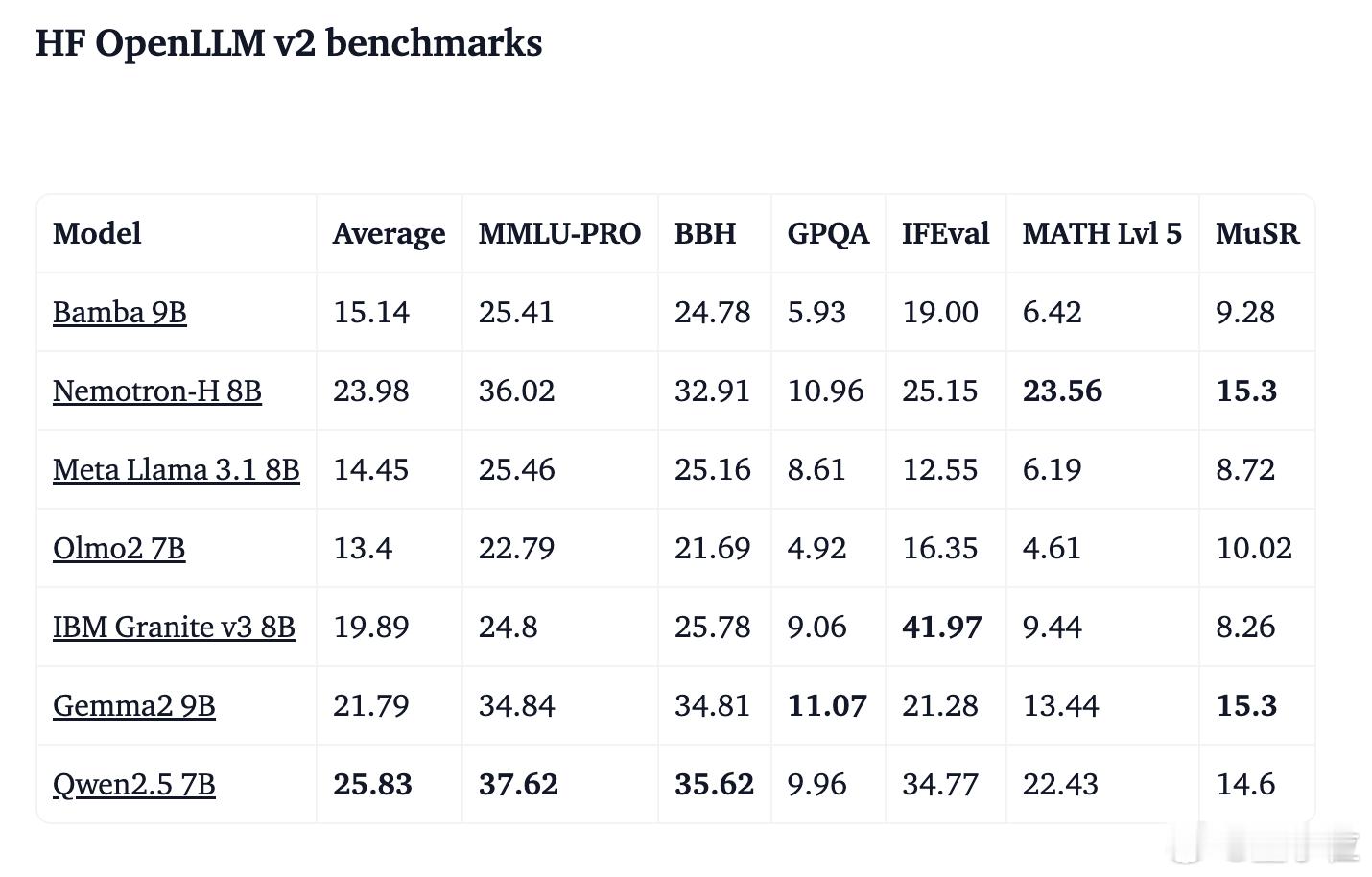
- HF OpenLLM v2 基准测试【图3】
- 训练过程
鉴于GPU资源有限(仅192块A100显卡),团队采用了两种方案:一是为现有模型注入新数据,二是尝试模型融合技术。【图4】
训练流程可分为三步:
1. 以2万亿token的基础检查点为起点,融入Olmo Mix数据集进行扩展训练,采用恒定学习率2e-5,将训练规模从2万亿token提升至2.5万亿token
2. 混合使用Nemotron-CC和Hugging Face数据,继续训练5000亿token使总量达到3万亿。进行恒定学习率和余弦衰减学习率对比实验,验证两种学习率策略的互补效果
3. 对两个模型进行1000亿token的高质量数据精炼,并使用MergeKit进行融合,通过加权平均生成最终Bamba 9B v2模型
团队透露,他们接下来要攻克的难题,是优化vLLM来运行SSM模型。
技术博客:
开源仓库: