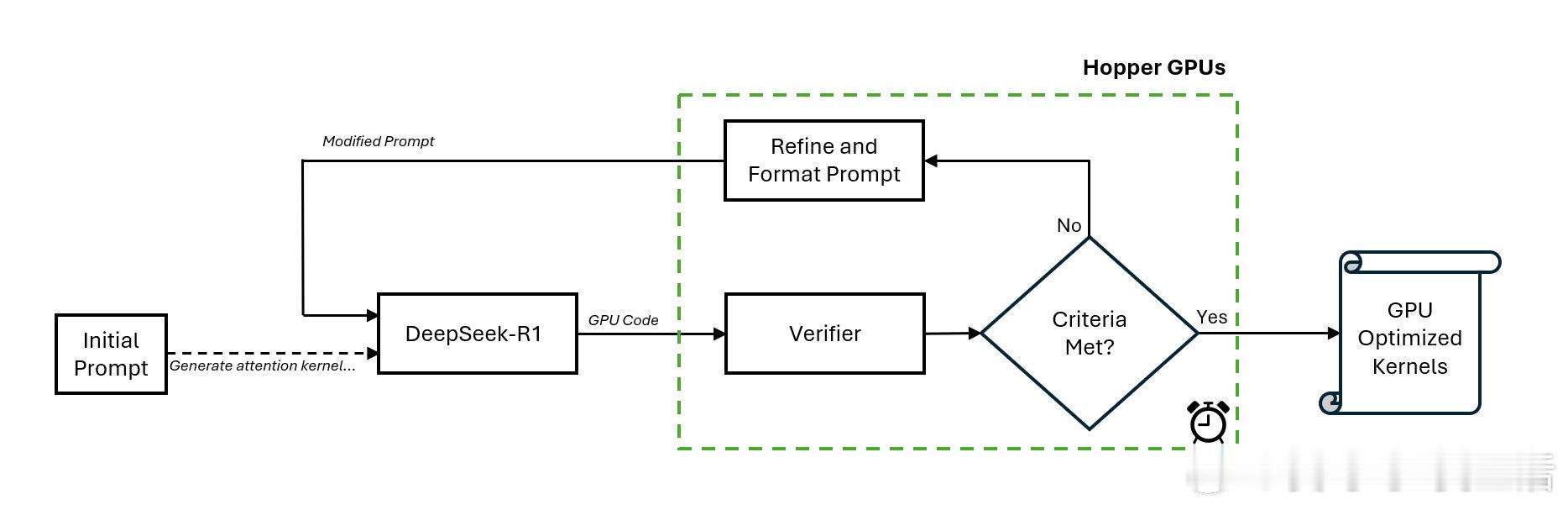
【用 DeepSeek-R1 模型和额外的计算能力在推理时自动生成优化的 GPU 注意力核,通过实验证明其在某些情况下优于经验丰富的工程师手工编写的核】
- 推理时缩放:AI 模型可以通过在推理时间内分配额外的计算资源来提高性能,这种方法被称为推理时缩放或测试时缩放,它使得 AI 能够更好地解决复杂问题。
- DeepSeek-R1 模型的应用:NVIDIA 工程师使用 DeepSeek-R1 模型自动生成 GPU 注意力核,这些核在数值上是正确的,并且针对不同的注意力机制进行了优化。
- 注意力机制的重要性:注意力机制是大型语言模型(LLM)发展的关键,它使 AI 模型能够在处理任务时专注于最相关的输入部分,从而提高预测准确性和发现数据中的隐藏模式的能力。
- 编写优化 GPU 核的挑战:为多种注意力变体编写优化 GPU 核是一个复杂的任务,需要大量的技能和时间,并且对于多模态模型(如视觉变换器)来说,这个任务更加复杂。
- 闭环工作流的优势:通过一个闭环的工作流,DeepSeek-R1 模型和特殊验证器能够在推理时间内不断优化代码生成过程,这种方法已经在基准测试中证明了其有效性。
- DeepSeek-R1 模型的潜力:尽管 DeepSeek-R1 模型在生成优化代码方面取得了一定的进展,但仍需要更多的工作来确保在更广泛的问题上持续得到更好的结果。
'Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling'