随风 9 2025-02-02 21:13 谁抄谁显而易见 Soros 回复 02-04 12:58 这个不叫抄,所谓蒸馏技术是指AI大模型使用其他模型输出的数据(即其他模型筛选、消化过的数据)进行训练,这样相对于使用通用数据(互联网原始数据)能大幅提升训练效率。所有的AI模型都在使用蒸馏技术,它们掌握的知识本身都源自互联网,数据都是共享的。但每个AI自己筛选、消化知识的方法不一样,这个称之为算法,这是别人拿不走的。 随风 回复 02-05 00:04 请你不要造谣,我已经验证了,请不要在法律边缘游荡
Soros 回复 02-04 12:58 这个不叫抄,所谓蒸馏技术是指AI大模型使用其他模型输出的数据(即其他模型筛选、消化过的数据)进行训练,这样相对于使用通用数据(互联网原始数据)能大幅提升训练效率。所有的AI模型都在使用蒸馏技术,它们掌握的知识本身都源自互联网,数据都是共享的。但每个AI自己筛选、消化知识的方法不一样,这个称之为算法,这是别人拿不走的。
Ren 3 2025-02-03 15:33 记得有一次OpenAI回答的是根据文言一心的规定不能回答此问题[哭笑不得]其实国外人工智能大量蒸馏国内数据,不然他们是不可能有中文训练数据的。 sopio 回复 02-04 04:36 那是谷歌模型。openai也满世界抓数据,不过他们是用ai洗稿造数据。

hhhhhhhhb
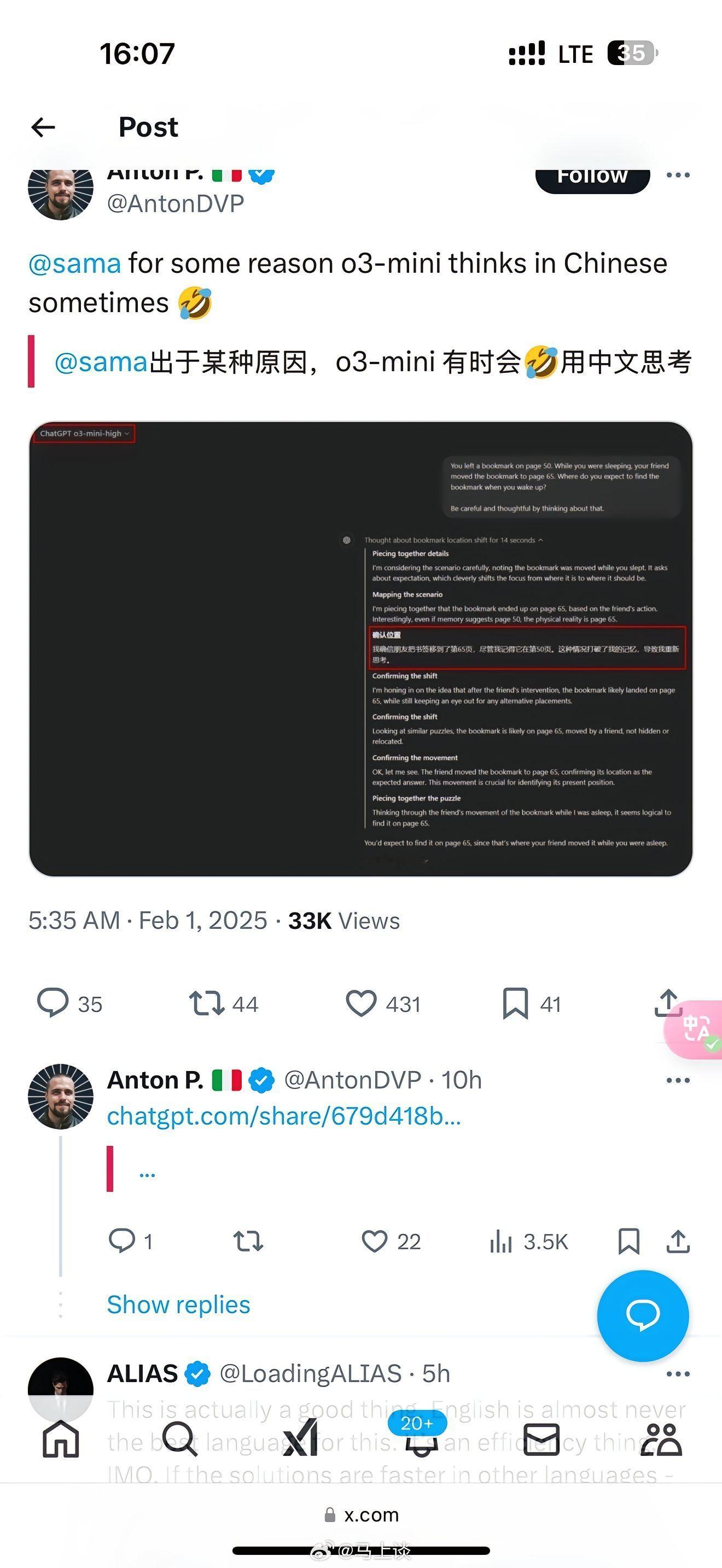
这是不合理的想象,合理解释是P图。因为我自己也写程序,这种情况是匪夷所思的,不该出现不同语言。
随风
谁抄谁显而易见
Soros 回复 02-04 12:58
这个不叫抄,所谓蒸馏技术是指AI大模型使用其他模型输出的数据(即其他模型筛选、消化过的数据)进行训练,这样相对于使用通用数据(互联网原始数据)能大幅提升训练效率。所有的AI模型都在使用蒸馏技术,它们掌握的知识本身都源自互联网,数据都是共享的。但每个AI自己筛选、消化知识的方法不一样,这个称之为算法,这是别人拿不走的。
随风 回复 02-05 00:04
请你不要造谣,我已经验证了,请不要在法律边缘游荡
Yf7509
这是百分百抄了DeepSeek 啊,老霉何时要过脸?
Ren
记得有一次OpenAI回答的是根据文言一心的规定不能回答此问题[哭笑不得]其实国外人工智能大量蒸馏国内数据,不然他们是不可能有中文训练数据的。
sopio 回复 02-04 04:36
那是谷歌模型。openai也满世界抓数据,不过他们是用ai洗稿造数据。
用户10xxx50
蒸馏中国技术
淮河渔翁
把反应釜搬到Deepseek这“蒸馏”来了。