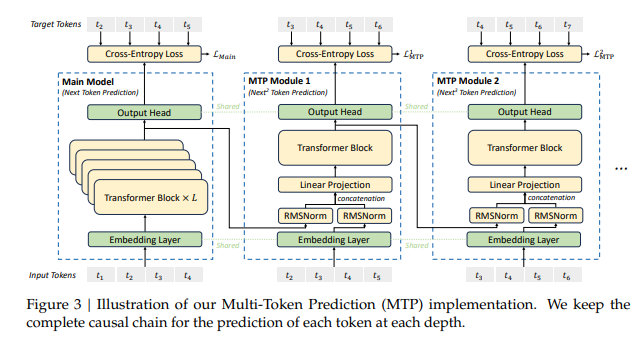
看了下大火的deepseek v3的论文,核心就是这个图。大模型要祛魅了
MTP看来概念要爆,多头并行预测,能把训练代价缩减成十分之一。似乎是把本来纯线性的训练方式改成了多项式级的。加了两个高阶项。
以前从来没有论文,把大模型的秘密解释得这么清楚。OpenAI弄出东西了,但是论文根本没说细节,云山雾罩的,背离了业界的开源传统。
之前AlphaGo战胜人类棋手,出论文把技术机密完全说清楚了。很多个人研究者都能照着训练成功,需要的卡也不多,技术不断优化。
现在,deepseek v3最重要的就是开源,代码和技术秘密都交待得很清楚。这对全球训练GPT的团队都有很大好处,真的不需要那么多卡。这样,能一起探索大模型能力边界的队伍会增加十倍以上,是大好事。
美国大公司优势大幅缩减。都来搞大模型训练,都搞得不错,大模型就会祛魅了。现在很多人以为美国干出了什么黑科技,其实不是,论文说的很清楚,就是这么弄出来的。等于知识压缩。
这也是我一直盼望的事件,训练不是堆积算力,而是有很大优化空间。那么复杂的过程,显然有很大优化空间。一个是算法能力进步,一个是计算速度、需要的资源大幅优化,这都是计算机业界最厉害的。