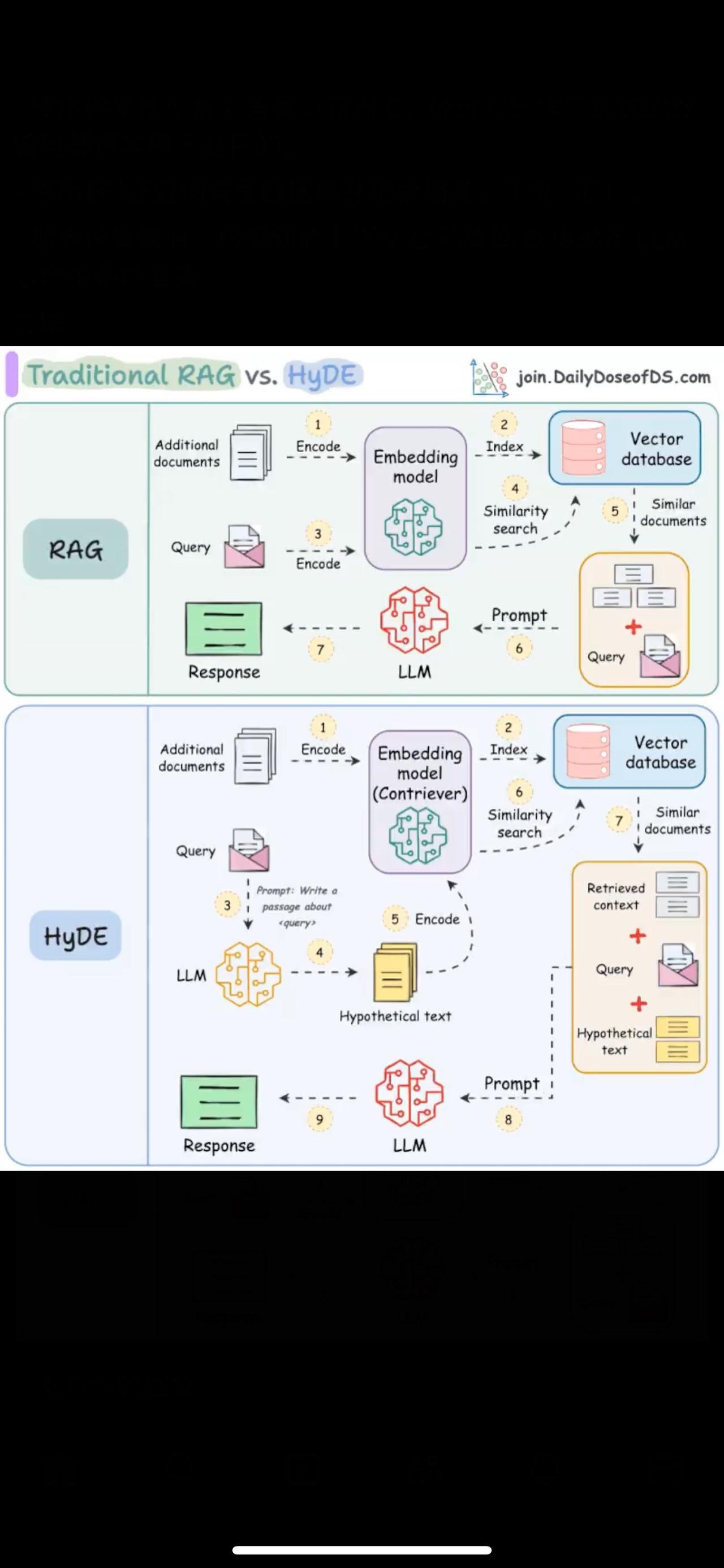
传统 RAG 与 HyDE 的对比,直观解释! 传统 RAG 系统的一个关键问题是问题在语义上与答案不相似。 假设您想找到类似于“什么是 ML?”的句子,那么“什么是 AI?”可能看起来比“机器学习很有趣”更相似。 这种语义差异导致在检索步骤中检索到几个不相关的上下文。 HyDE 解决了这个问题。 下图说明了这种方法与传统 RAG 的不同之处。 工作原理如下: - 使用 LLM 为查询(Q)生成假设答案(H) 。此答案不必完全正确。 - 使用检索模型嵌入答案以获得 E。经过对比学习训练的双编码器通常用于此目的。 - 使用嵌入E查询向量数据库并检索相关上下文(C)。 - 将假设答案 H、检索到的上下文 C 和查询 Q 传递给 LLM 以产生最终答案。 完毕! 现在,当然,产生的假设很可能包含幻觉细节。 但由于嵌入的检索器模型,这不会严重影响性能。 更具体地说,该模型使用对比学习进行训练,它还可以充当近无损压缩器,其任务是过滤掉伪造文件的幻觉细节。 这会产生一个向量嵌入,预计它与实际文档的嵌入比问题与真实文档的嵌入更相似。 多项研究表明,与传统嵌入模型相比,HyDE 提高了检索性能。 但这是以增加延迟和增加 LLM 使用量为代价的。 喜欢这个吗?你也应该看看我的 RAG 系列!从构建和优化 RAG 应用程序到评估性能和设计代理和多模式系统——一切都在这里。 编程严选网 软件开发 程序员