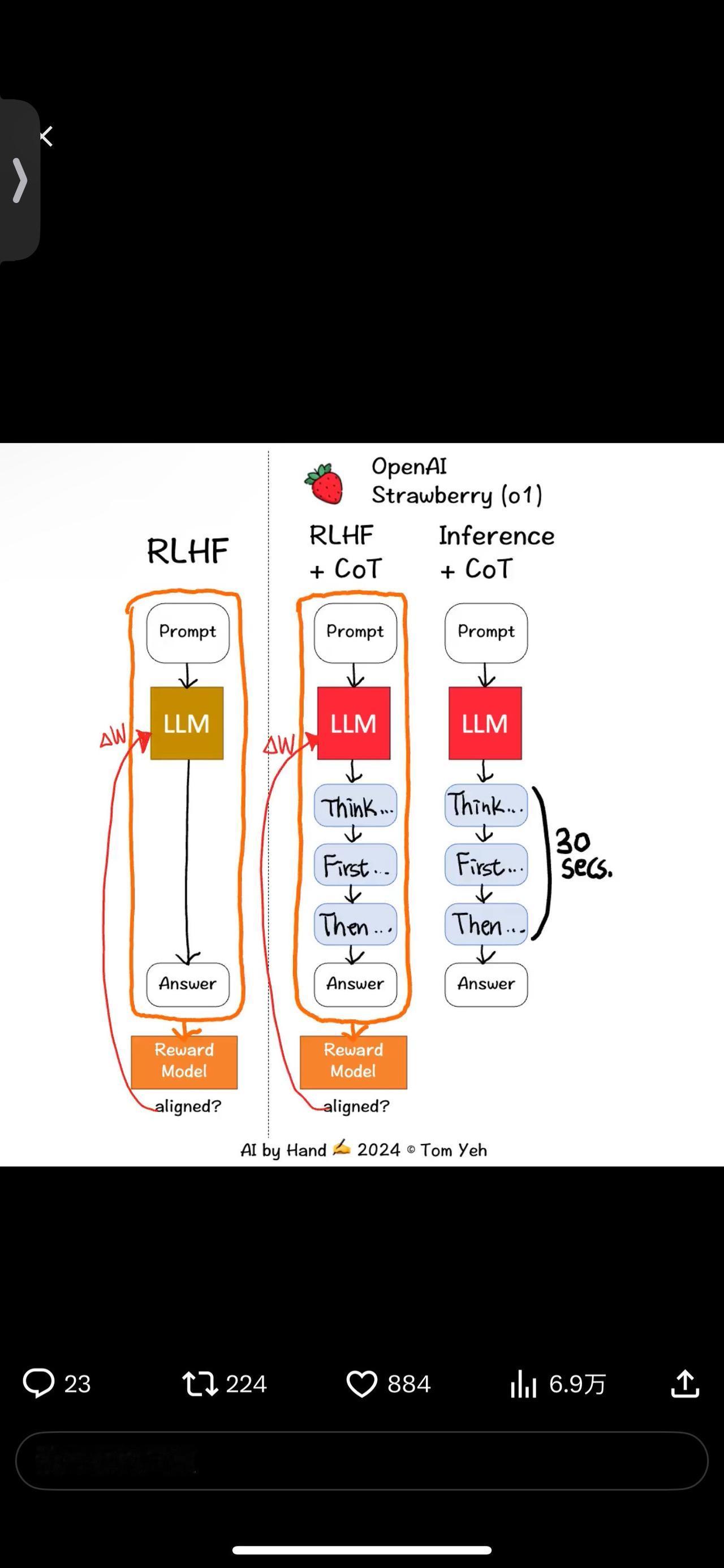
OpenAI 如何训练 Strawberry 🍓 (o1)模型花更多时间思考? 我读了报告。报告主要讲的是𝘸𝘩𝘢𝘵他们获得的令人印象深刻的基准测试结果。但就𝘩𝘰𝘸而言,报告只提供了一句话: “通过强化学习,o1学会磨练其思路链并改进其所使用的策略。” 我尽力去理解这句话。我画了这个动画来和大家分享我最好的理解。 这句话中的两个关键词是:强化学习(RL)和思路链(CoT)。 在报告中列出的贡献者中,有两个人给我留下了深刻的印象: Ilya Sutskever,RL 和人类反馈 (RLHF) 的发明者。他离开了 OpenAI,刚刚创办了一家新公司 Safe Superintelligence。Ilya 告诉我,RLHF 仍然在训练 Strawberry 模型中发挥作用。 Jason Wei,著名论文《Chain of Thought》的作者。他去年离开 Google Brain 加入 OpenAI。Jason 告诉我,CoT 现在是 RLHF 对齐过程的重要组成部分。 以下是我希望在动画中传达的要点: 💡在 RLHF+CoT 中,CoT 令牌也被输入到奖励模型中以获得分数,从而更新 LLM 以实现更好的对齐,而在传统的 RLHF 中,只有提示和响应被输入到奖励模型中以对齐 LLM。 💡在推理时,模型已经学会了始终先生成 CoT 标记,这可能需要长达 30 秒的时间,然后才开始生成最终响应。这就是模型花费更多时间思考的原因! 还缺少其他重要的技术细节,例如如何训练奖励模型,如何引出人类对“思考过程”的偏好……等等。 最后,作为免责声明,此动画代表了我最好的有根据的猜测。我无法验证其准确性。我真的希望 OpenAI 的某个人能站出来纠正我。因为如果他们这样做了,我们都会学到一些有用的东西! 🙌#程序员 #人工智能 #编程严选网 #openai #o1