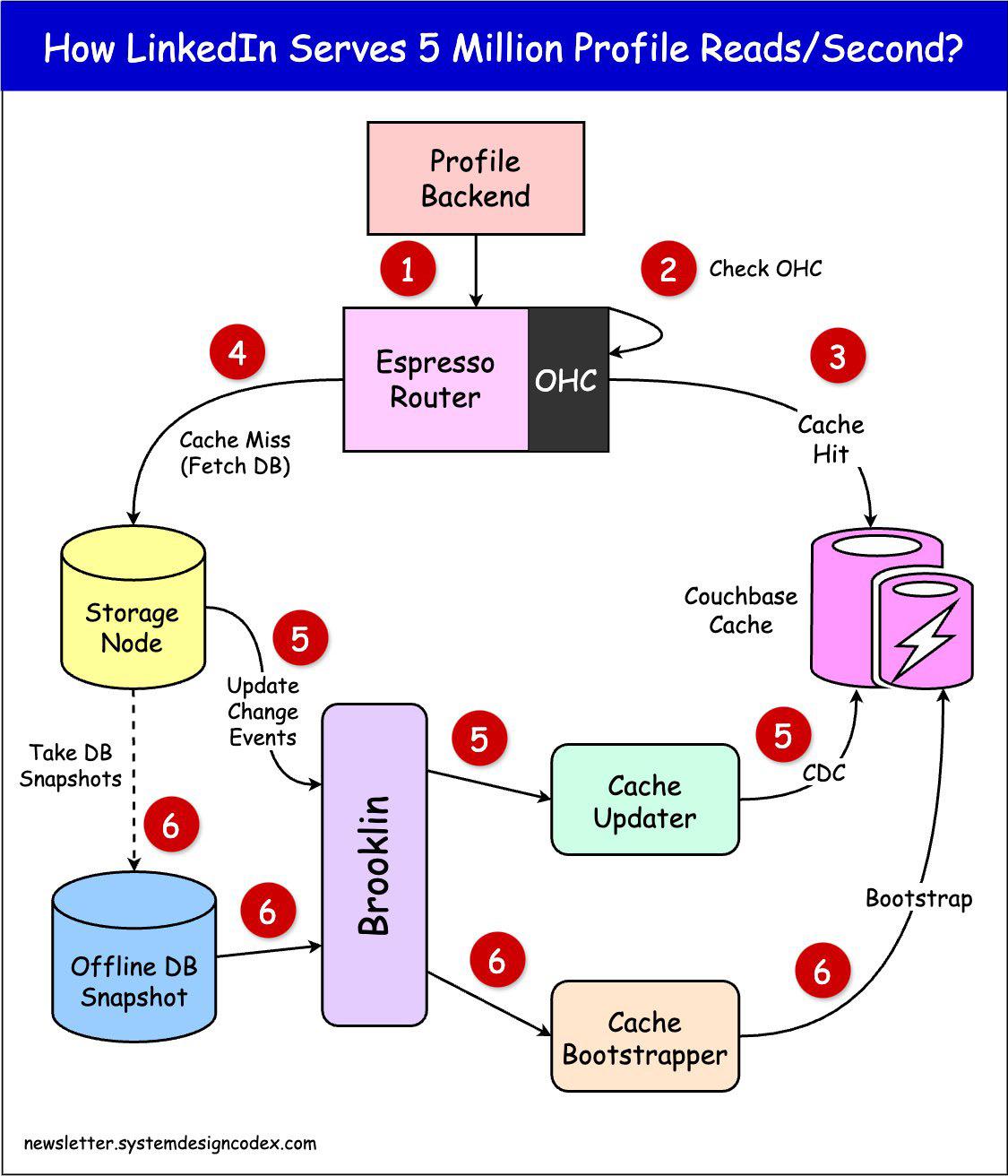
LinkedIn 如何使用缓存来提供每秒 5000000 次个人资料读取服务? 这个数字本身就很了不起。但他们也做得很有风格。 ✅缓存命中率超过 99%,这意味着其中 495 万次读取是由缓存提供的。 ✅第 99 百分位延迟从 31.6 毫秒下降到 12.41 毫秒(下降了 60.73%)。 ✅数据库节点数量减少 90%。 ✅每年节省 10% 的成本。 所有这一切都是通过 Couchbase 缓存、Espresso 数据存储和 Brooklin CDC 的巧妙组合实现的。 LinkedIn 工程师实施的系统的工作原理如下: 1 – 当 Profile 后端应用程序收到读取请求时,它会将该请求发送到 Espresso 路由器实例。 2 – 路由器检查密钥是否存在于 OHC(堆缓存)中。 3 - 如果不是,则请求将发送到 Couchbase 缓存。如果缓存命中,则返回数据。 4 – 如果发生缓存未命中,则存储节点将提供该请求,并更新缓存以供将来的请求使用。 5 - 当配置文件记录更新时,缓存也会更新以保持同步。Brooklin 变更捕获流使用 Espresso 数据库变更事件并更新缓存中的记录。 6 – Brooklin 引导流填充了定期生成的数据库快照以更新缓存。 在此之上,基本目标是根据需求进行扩展。为了实现这一目标,实施了三个附加要求: - 通过健康检查和重试,保证 Couchbase 节点发生故障时的恢复能力 - 通过跨多个数据中心的复制实现缓存数据的高可用性 - 对数据库和缓存之间的数据差异实行严格的服务级别目标 (SLO)。 那么,你觉得这个设计怎么样?你会做出不同的设计吗? #编程严选网 #程序员 #人工智能