大规模强化学习作为关键路径,能够有效激发大模型复杂推理能力并显著提升其任务泛化性。近期,快手 Kwaipilot 团队重磅发布了 KAT-Dev-72B-Exp,在软件开发能力评测基准 SWE-Bench Verified 上取得了74.6%的卓越性能,在开源模型领域创下新纪录。KAT-Dev-72B-Exp 是 KAT-Coder 模型强化学习的实验版本,我们借助这一开源模型揭秘 KAT-Coder 在大规模强化学习方向上的技术创新。

和全尺寸开源模型对比,KAT-Dev-72B-Exp 以74.6%的卓越性能创下新纪录
作为 Kwaipilot 在端到端复杂强化学习领域的前沿探索成果,该模型基于自研 SeamlessFlow 工业级强化学习框架,通过创新的数据平面架构实现了训练逻辑与 Agent 的完全解耦,成功支持多智能体和在线强化学习等复杂场景。针对复杂 Agent 场景的技术挑战,团队创新性地引入 Trie Packing 机制,并对训练引擎进行了重构优化,使模型能够高效地在共享前缀轨迹上开展训练。通过难度感知的策略优化,实现了探索与利用的平衡,并结合基于开源仓库构建的大规模端到端可验证软件工程任务,KAT-Dev-72B-Exp 在编程领域展现出强大的能力。
一、Trie Packing在大规模 LLM agentic training 场景中,由于各种 TTS 技术及 memory 机制,agent 在完成任务时所产生的 token 轨迹通常呈树形结构。对于这种复杂轨迹的训练方式,业界过往都是将树形轨迹拆解为若干条独立的线性序列。对于这一问题,我们重写了训练引擎以及 attention kernel,通过树形梯度修复权重,把共享前缀的前反向重复的计算合并,让模型能高效地在共享前缀的轨迹上进行训练。最终速度平均提升了2.5倍,大幅增加了 RL 训练的吞吐量。
二、熵感知的优势缩放在强化学习的策略梯度优化中,优势函数直接与对数概率的梯度相乘,相当于为每个样本的梯度分配一个缩放因子。具体来说,对于策略,策略梯度为:
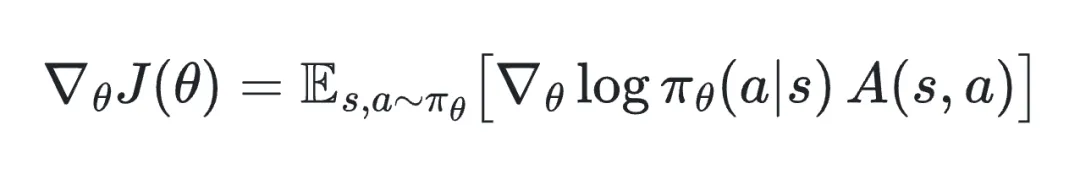
在实际训练中,通过样本估计梯度并进行参数更新:
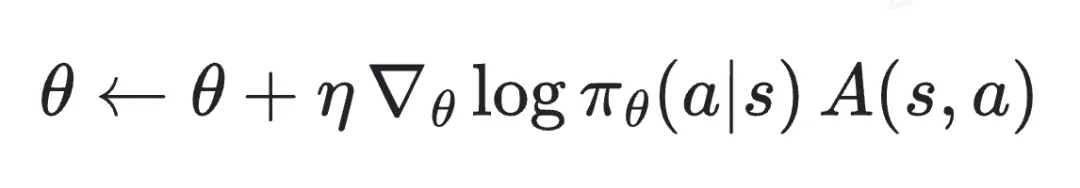
可以看到,优势值A(s,a)直接作为梯度的缩放因子:绝对值越大,该样本在参数更新中的贡献越大;绝对值较小,则更新幅度也较小。因此,合理调整优势值能够引导模型将更多优化能力集中在最需要探索的样本上。
在 GRPO 中,优势函数主要依赖组内收益信息,而不考虑策略的探索性。这可能导致模型在训练过程中对确定性较高的样本过度关注,而忽略那些具有更高探索潜力的样本,从而限制策略的探索性,容易陷入局部最优。
基于这一观察,我们提出了一种基于熵的优势缩放方法:对每个 rollout 样本计算策略熵,并将其归一化后用作优势的放大系数。熵高的样本表示更高的不确定性和探索性,其优势将被放大,在梯度更新中占据更大比重;熵低的样本优势被相应缩小,避免过度优化低熵样本导致策略熵崩溃。该方法在保留 GRPO 组内优化结构的同时,有效增强了策略探索性,改善了 RL 训练过程中探索-利用的平衡。
三、总结与展望在 agentic RL 训练过程中,模型训练的成功离不开高效、可扩展的数据环境支撑。传统方法往往局限于单一数据集和固定框架,导致模型在面对复杂现实场景时表现欠佳。通过持续的实践探索,Kwaipilot 团队逐渐意识到大规模 scaling 数据环境的重要性。这不仅是数据量的堆积,更是构建一个动态、灵活的生态系统,让模型能够从海量且多样化的数据中汲取营养,实现从“实验室玩具”到“实战高手”的跃升。
为此,Kwaipilot 团队正积极投入建设一套大规模数据环境管理系统。这套系统的核心在于实现训练数据、训练沙盒(sandbox)以及训练框架的完全解耦。通过这种设计,数据源可以独立扩展,而不会受限于特定框架的约束;沙盒环境则提供安全的隔离测试空间,避免干扰主流程;训练框架也能灵活切换,支持多种算法迭代。这种解耦机制极大提升了系统的模块化程度,让开发团队能够更高效地协作,避免了以往“牵一发而动全身”的瓶颈。
更重要的是,该系统显著加速了训练数据的扩充过程。我们的数据环境管理系统采用统一的数据协议,可以快速整合开源的以及各种多源数据环境。数据环境涵盖代码、数学、游戏、博弈等多个领域。在这样的环境中,模型可以通过 RL 反复迭代,逐步适应各种复杂情境,进一步增强其泛化能力。模型不再局限于单一的环境,而是能在跨领域的环境中自适应,也更能在没有见过的环境中有更好的表现,提升其鲁棒性和实用性。
注:文章转载自快手大模型公众号