Test-Time Scaling 已成为提升大模型能力上限的关键技术趋势,但超长上下文推理带来的计算与存储开销呈指数级增长,尤其在 Attention 计算与 I/O 瓶颈方面尤为突出。为突破这一制约,我们基于 Ling 2.0 架构,创新性地融合高稀疏比 Mixture of Expert(MoE)结构与稀疏注意力机制,设计出专为长序列解码优化的稀疏注意力架构。今天,我们正式开源该架构下的高效推理模型 Ring-mini-sparse-2.0-exp,并同步提供其在 SGLang 框架上的高性能实现。
得益于架构与推理框架的深度协同优化,该模型在复杂长序列推理场景下的吞吐量较原版 Ring-mini-2.0 实现 近 3 倍提升,同时在多项高难度推理基准测试中持续保持 SOTA 性能。这一成果为开源社区提供了兼具高效推理与强上下文处理能力的轻量化解决方案。

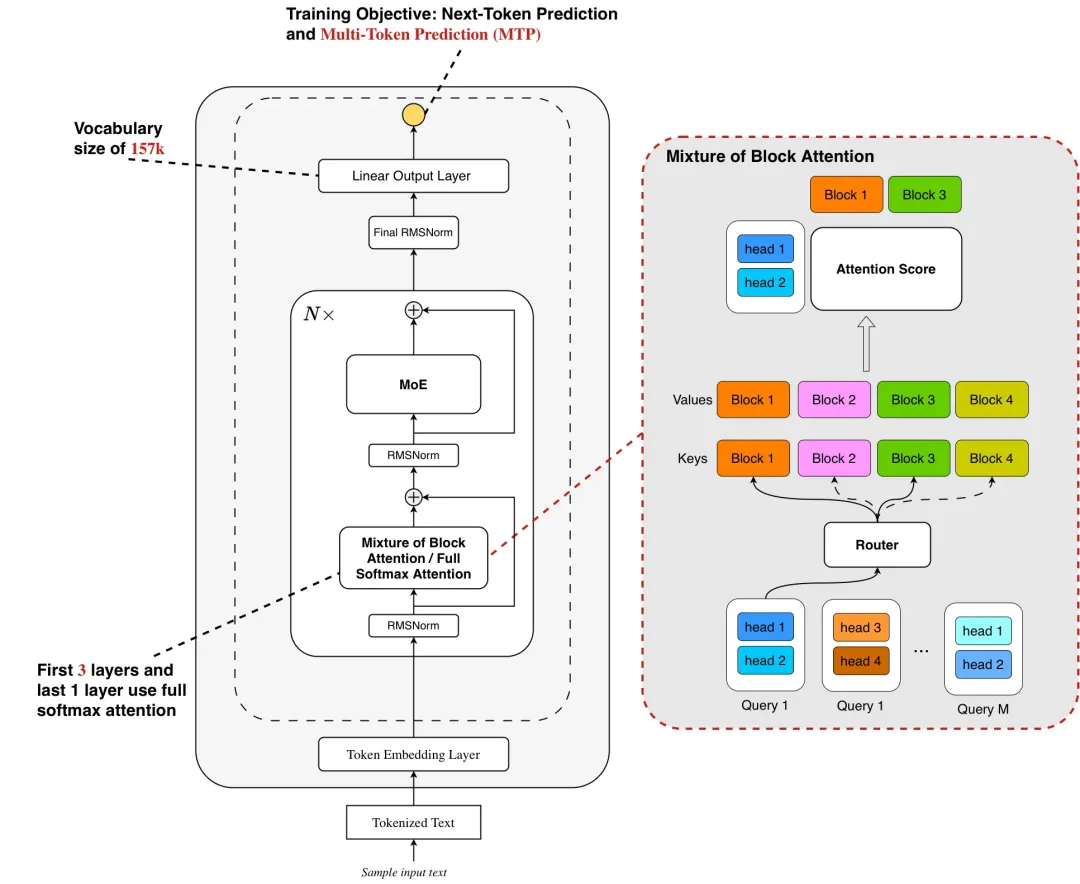
Ling 2.0 Sparse 是专为应对大语言模型未来两大核心趋势 —— 上下文长度扩展(Context Length Scaling) 与测试时扩展(Test Time Scaling)而设计的高效稀疏注意力机制。我们借鉴了Mixture of Block Attention (MoBA),采用块级稀疏注意力(block-wise sparse attention),将输入的 Key 和 Value 按块(block)划分,每个 query 在 head 维度上进行 top-k 块选择,仅对选中的块执行 softmax 注意力计算,从而显著降低计算开销。同时,我们将 MoBA 设计和 Grouped Query Attention (GQA) 结合,使同一组内的 query heads 共享 top-k 块选择结果,让一次块读取可服务于多个 query head 的注意力计算,进一步减少 I/O 开销。
然而,尽管开源的 MoBA 方法能有效加速 prefill 阶段,其在 decode 阶段仍无法实现加速。原因在于 MoBA 采用的块级稀疏注意力机制:Key 和 Value 分块后,需通过聚合操作(如均值池化)生成块表示。
若要在 decode 阶段有效应用该方法,必须缓存 prefill 阶段生成的块 token 表示(类似于 KV Cache)。但当前主流推理框架(如 vLLM、SGLang)仅支持标准 KV Cache 存储,不支持额外的块 token 缓存。若在 decode 阶段不重用这些块 token 而选择重新计算,则需要从 KV Cache 中完整读取对应的原始 Key。由于 MoBA 计算仅需极稀疏的 Key 子集,这种完整 Key 读取会带来大量冗余数据访问,显著增加 decode 阶段的 I/O 开销。
为了能让 MoBA 在decode阶段也能有效加速,我们结合 SGLang 提出 page-aware block cache。
Page-aware Block Cache基于 SGLang/vLLM 的 page-attention 架构,我们为每个 KV cache 分页(page)配套构建一个 Block Cache。具体实现为:
Prefill 阶段:将每个 page 内的 token 序列视为一个 block,实时计算其聚合表示(如 mean-pooled vector),并存入 Block Cache;
Decode 阶段:通过查询 Block Cache(而非原始 KV cache)获取预计算的块表示,结合当前 query 的 head-wise top-k 路由,仅激活 top-k 关联的 page;
内存管理统一性:Block Cache 与 KV cache 共享 page-table 索引机制,确保稀疏路由、内存分配与淘汰策略在系统层面保持一致,避免额外元数据开销。


该设计有效解决了 MoBA 在 decode 阶段的 I/O 瓶颈:
通过复用预计算的 block 表示,消除动态重计算引发的冗余内存访问;
利用 page-table 动态屏蔽未激活的 pages,确保仅稀疏相关数据被加载,完美适配block-wise sparse attention page稀疏化的特性。
得益于 SGLang 实现,Ring-mini-sparse-2.0-exp 在 prefill 和 decode 阶段,随着输入输出长度的增加,相较于之前的 full softmax attention 整体的优势极速扩大,在超长输出时推理速度可以快3倍!
