日前,谷歌正式推出全新的 Gemini 3 系列模型,并将其定位为迄今“最智能”“事实最可靠”的 AI 系统。
据介绍,
谷歌所有用户均可在 Gemini 应用里直接使用新的旗舰模型 Gemini 3 Pro,并同步将其引入搜索订阅服务。

据悉,Gemini 3 Pro 的核心能力是“原生多模态”,能一次性处理文字、图片与音频,而不是分成不同流程。
谷歌举例称,模型可以把菜谱照片整理成一本食谱,也能根据多段课程视频自动生成互动抽认卡。
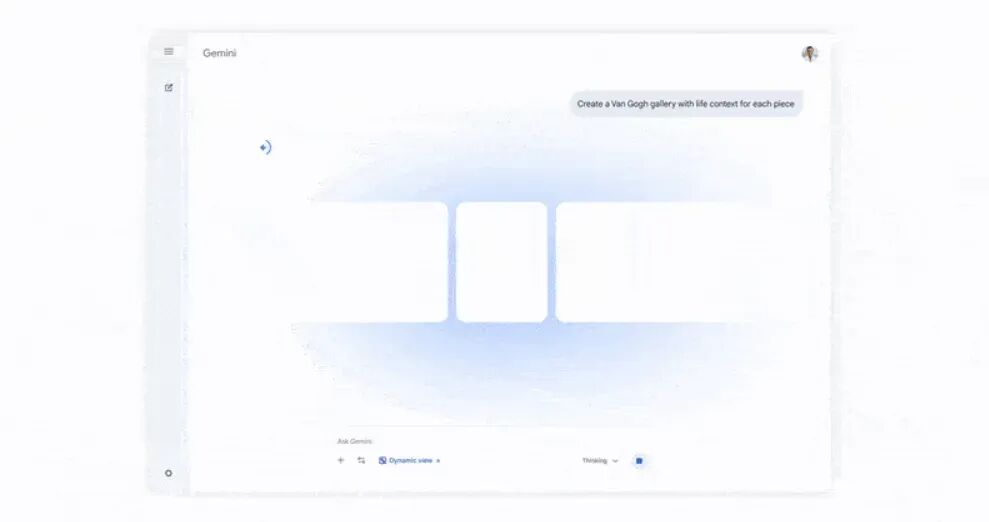
该模型带来的升级已渗透到谷歌的一系列产品中。在 Gemini 应用内的 Canvas 工作区,用户能借助新模型构建功能更完整的程序。Gemini Labs 中测试的“生成式界面”功能,也能让 Gemini 3 Pro 根据提示生成杂志式的视觉版面,或创建随需求变化的动态界面。
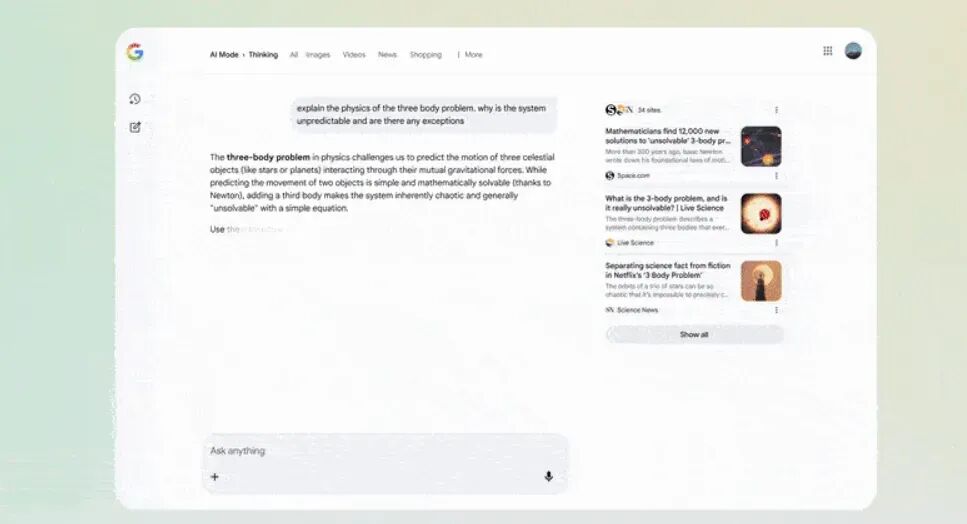
在谷歌搜索的 AI Mode 中,Gemini 3 Pro 也会以更直观的方式呈现结果,包括图片、表格、网格甚至模拟内容。
依托升级的“查询扇出技术”,模型不仅能把问题拆解成可搜索的细项,也更能理解提问意图,进而找到“过去可能遗漏”的内容。
同时,谷歌Gemini 3 Pro 的推理与智能体能力也显著增强,更能应对复杂任务,并具备稳定的长期规划能力。
Gemini 应用内正在测试的 Gemini 智能体功能正由这套模型驱动,可代替用户整理邮件,或搜索并预订行程。
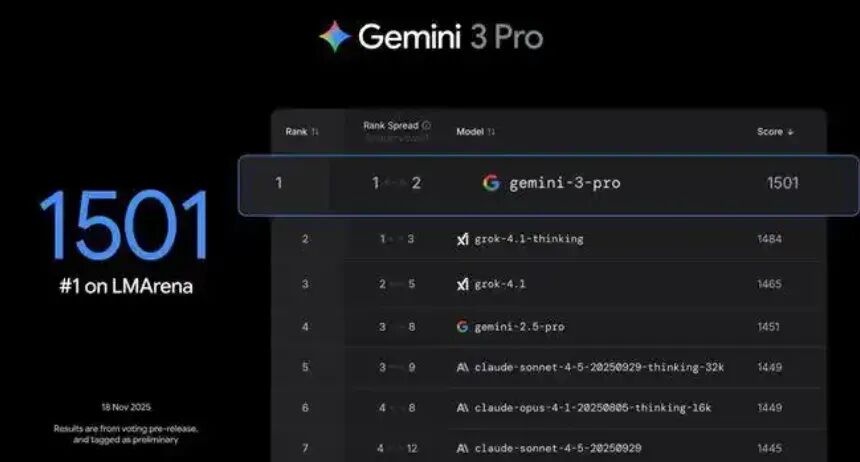
目前,Gemini 3 Pro 排在广泛使用的评测平台 LMArena 榜首。其 Deep Think 模式进一步强化推理能力,但暂时只向安全测试人员开放。
目前,谷歌正式推出了全新图像生成与编辑模型 Nano Banana Pro (Gemini 3 Pro Image)。
该模型基于 Gemini 3 Pro 架构构建,号称能以“前所未有的控制力、完美的文字渲染效果以及增强的世界知识储备”,将用户的构想转化为“工作室级(studio-quality)”的设计作品。
相比今年 9 月发布、因生成超写实 3D 手办而走红的初代模型,此次更新代表了谷歌在图像生成领域的又一次重要跃升。

据谷歌介绍,Nano Banana Pro 在处理复杂信息方面表现出色,能够生成包含丰富上下文的信息图表,直观呈现天气、体育赛事等实时数据。
该模型的一大突破在于其文本渲染能力。Nano Banana Pro 能够生成细节更丰富、文字更准确的图像,并支持以不同风格、字体及语言生成文本内容。
无论是简短的标语还是长段落文本,Nano Banana Pro 都能清晰、准确地将其直接渲染在图像中。这一特性使其极具实用性,非常适合制作多种语言版本的海报或邀请函。
此外,模型还具备强大的合成能力,支持在一个画面中融合最多 14 张图像素材和多达 5 个人物主体。
在编辑功能上,Nano Banana Pro 引入了更高级的创意控制选项。用户不仅可以对图像进行局部选择与编辑,还能调整摄像机角度、添加背景虚化(Bokeh)效果、改变焦点、进行专业色彩分级(Color Grading),甚至自由切换日夜光照效果。
在输出规格方面,模型支持多种长宽比,最高可生成 4K 分辨率的高清图像。