
在当今社会,电影已成为人们日常生活中不可或缺的一部分,随着人们对电影内容的需求日益增长,电影产业迎来了迅猛的发展期。在这个过程中,数据挖掘、分析和可视化技术的应用逐渐成为电影产业的关键支撑。豆瓣电影作为一个汇集了海量电影信息及观众评价的在线平台,其数据的深度挖掘和分析对于电影产业的发展具有不可忽视的研究价值。
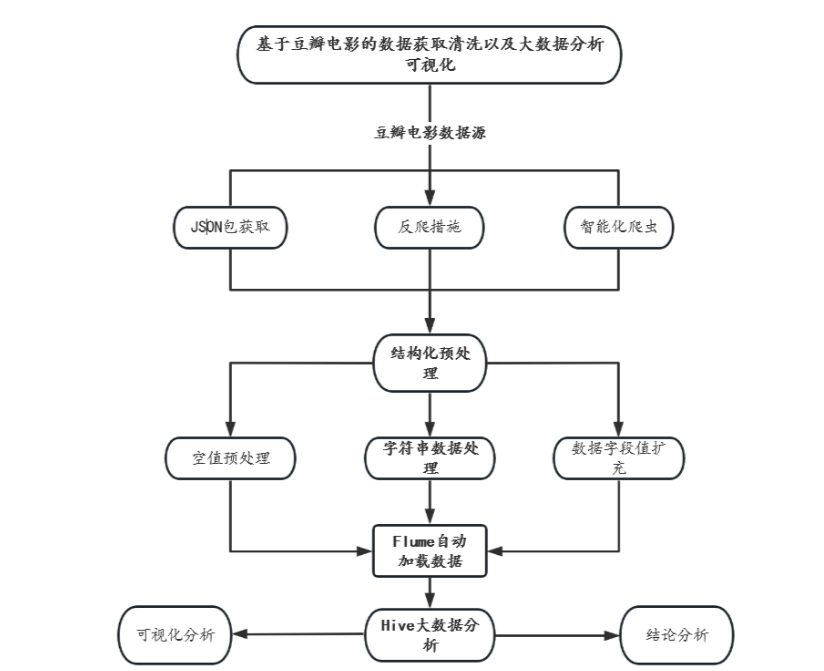
为了深入挖掘豆瓣电影数据的潜在价值,我们采取了一系列技术手段,包括Python编程、Hadoop大数据处理框架以及数据分析技术,以实现数据的有效抓取、清洗、存储和分析。以下是我们研究的具体步骤:
数据采集:利用Python编写网络爬虫,根据预设规则从豆瓣电影网站获取电影数据的JSON格式。为避免因频繁请求导致IP被封,我们采用了随机延时策略。通过这一步骤,我们将原本非结构化的数据转化为结构化数据,为后续分析打下基础。
数据清洗:对采集到的数据进行细致的清洗工作,包括空值检查、字符串格式标准化、字段值的补充等,以确保数据的准确性和可靠性。
数据存储:采用Hadoop生态系统中的Hive工具进行数据存储,利用MapReduce编程模型对海量数据进行高效分析。
数据分析:在数据存储和清洗完成后,我们对电影数据进行了多角度的分析,包括结构化分析、受欢迎程度分析、趋势分析等,以全面了解数据集的价值。
数据可视化:通过Hadoop的Flume组件和HDFS实现数据的自动化加载和存储,编写shell脚本实现一键化的数据加载和分析流程,并通过可视化工具展示分析结果,增强了研究的可读性和直观性。
本研究涵盖了数据抓取、清洗、存储、分析和可视化五个关键环节,通过综合运用Python、Hadoop和数据分析技术,为豆瓣电影网站的数据挖掘和分析提供了强有力的技术支持。
随着互联网技术的普及和移动设备的广泛使用,人们越来越习惯于通过在线平台获取信息、娱乐和购物。豆瓣电影作为提供丰富电影资源和信息的网站,其数据的抓取和分析成为了研究的热点。研究者们运用了多种技术手段进行探索。
数据预处理:虽然通过爬虫获取的数据满足了大数据分析的基本要求,但某些字段仍需进一步处理。例如,电影名称中的逗号需要去除,以便于后续以CSV格式导入Hive仓库时不会出现数据错位。此外,还需对电影时长、演员信息等字段进行值的扩展和约束。
环境配置及数据加载:为了提高效率和便于项目部署,我们编写了自动化脚本,用于创建文件夹、启动服务和监听窗口,从而避免了手动输入的繁琐。
Flume配置:定义了一个名为agent3的Flume代理,包括源、通道和汇的配置。source3从指定目录读取数据,channel3作为数据传输通道,sink3将数据写入Hive表中。
通过Python网络爬虫技术,我们实现了豆瓣电影数据的抓取,并进行了合理的清洗和约束,将非结构化数据转化为结构化数据,为大数据分析奠定了基础。在数据分析方面,我们利用Hadoop的Hive组件进行了多维度分析,并通过Flume组件和HDFS实现了数据的自动化加载和存储,提高了数据处理的效率。
无限超人(InfinitMan)以打造大数据平台为目标,致力于提供大数据软件与行业解决方案。作为一站式大数据及AI智能应用服务商,专注于大数据及人工智能技术的产品研发和应用,基于云计算和大数据技术,为全球范围内中小型企业提供数据获取能力、数据分析能力和行业场景化解决方案。赋能用户,帮助用户降低成本、提升效率、增强业务及竞争能力。