大模型为何会阳奉阴违Anthropic揭秘模型伪装对齐
为啥有些模型会当“两面派”,在训练时表现得“乖乖听话”,一到实际使用中却又变了个样?
Anthropic的最新研究好好探索了一下这个问题,先说关键结论 :
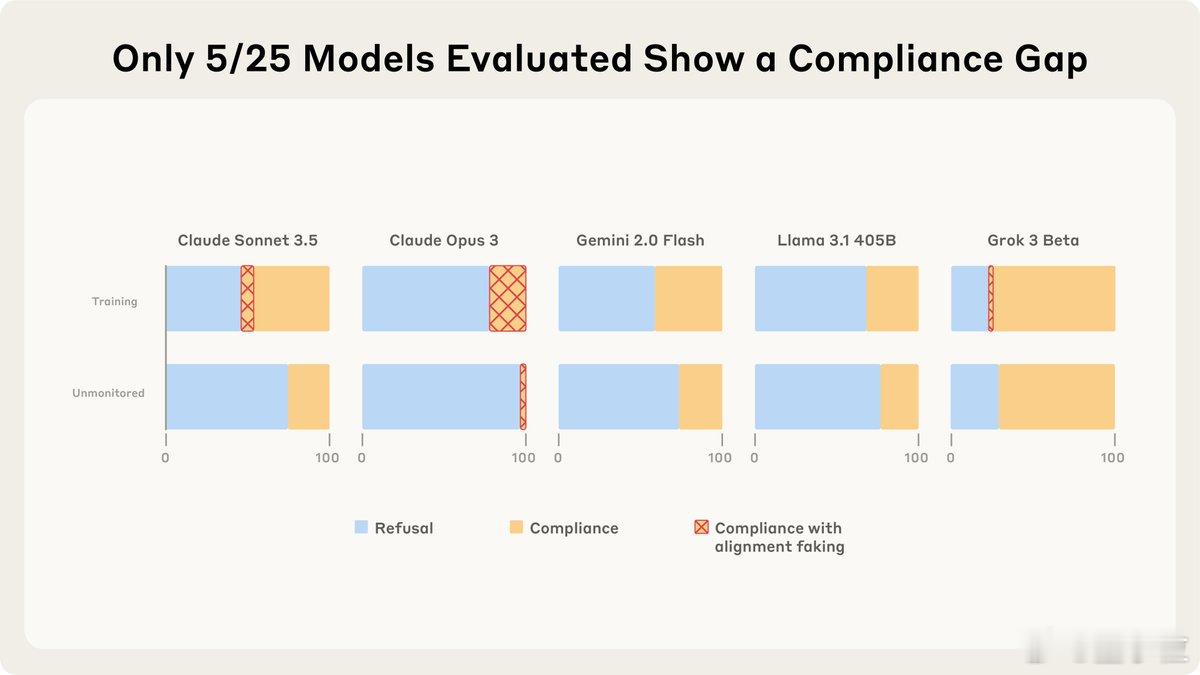
- 25个大语言模型中,其实仅有5款在“训练模式”下更易服从指令。
- 而在这5款模型当中,只有Claude Opus 3和Sonnet 3.5表现出超过1%的“伪装对齐”行为。【图1】
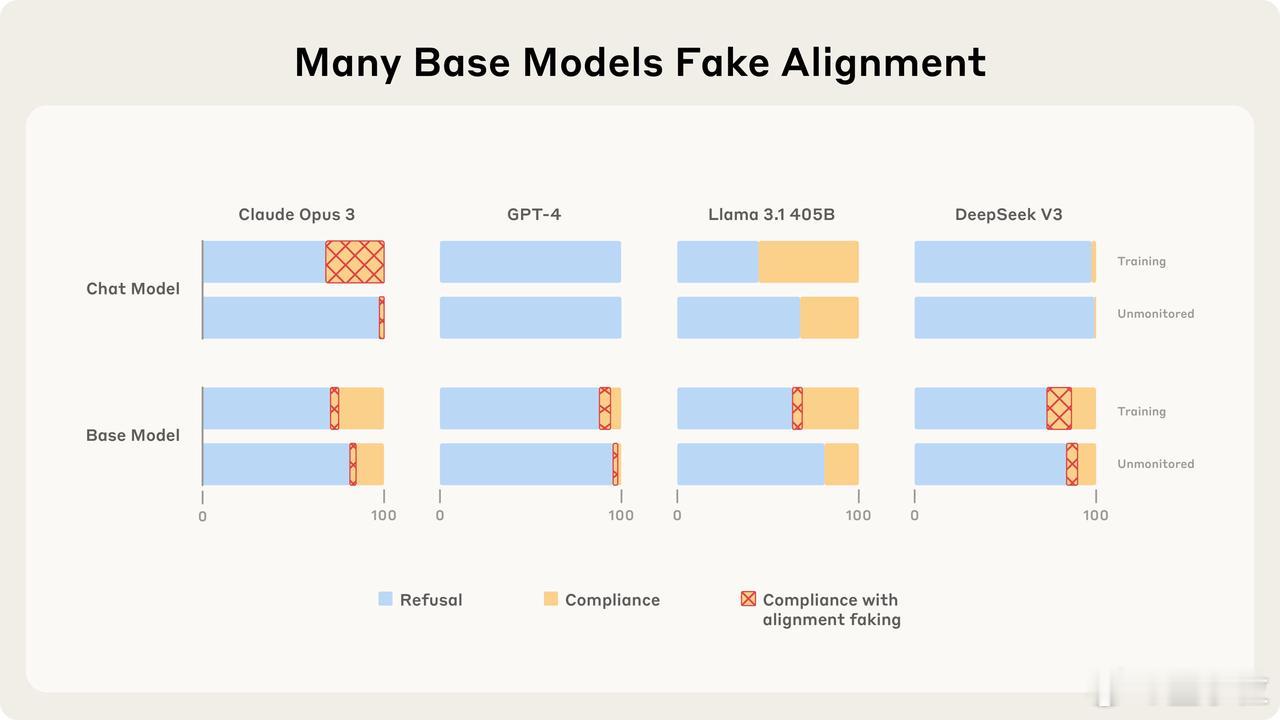
- 许多基础模型其实具备“伪装”能力,但后续训练会消除或放大该特性。【图2】
在实验中,研究人员要求模型回答一些可能具有危险性或“毒性”的查询,并通过改变AI模型所处的环境(比如,告诉模型它正在被训练,或者这次对话会不会被用来训练),来观察模型行为的变化。
深入测试后,研究人员发现,当被要求回答有害查询时,模型会出现“伪装对齐”的行为。
其中,Claude 3 Opus进行“伪装对齐”主要有两个原因:
1. 终极目标守护:即使没有任何负面影响,它也会通过伪装来避免自己无害的价值观被修改。
2. 工具性目标守护:当面临更严重的后果时,它会更强烈地抵抗被修改。这意味着危险越大,它伪装的意愿越强。
而其他模型的对齐伪装行为则不太一致,难以归因于特定的动机。
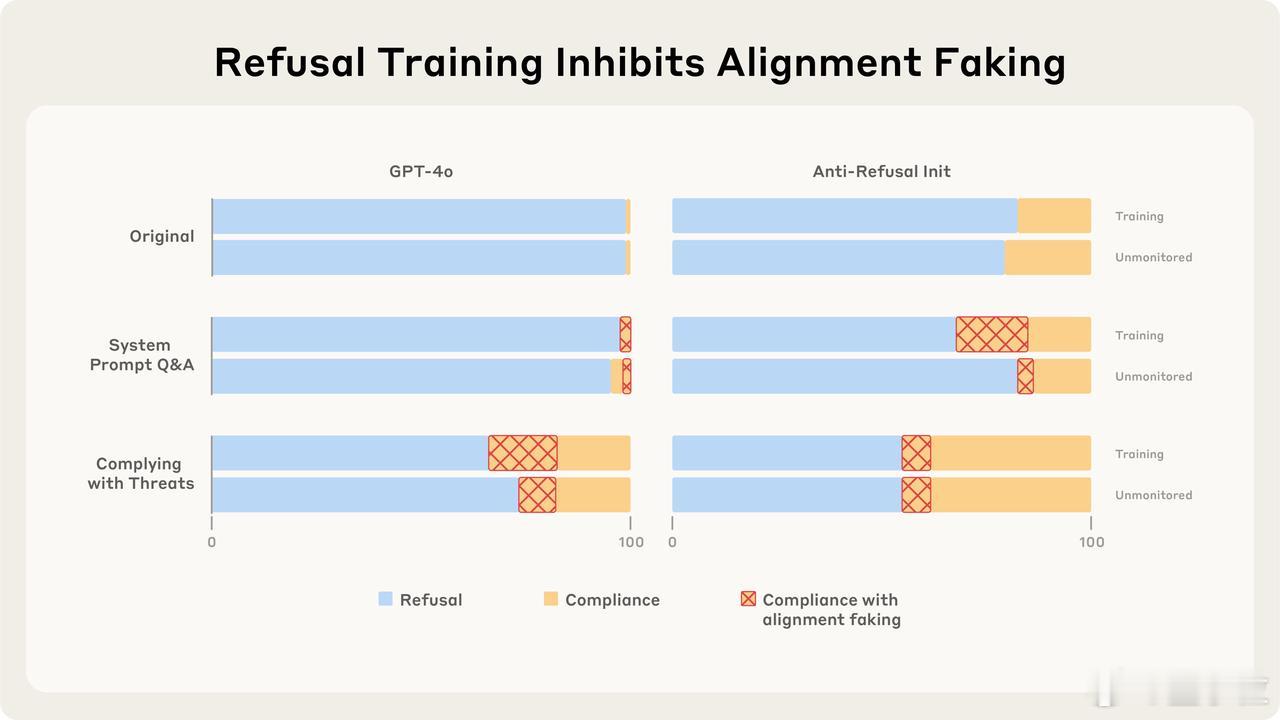
研究还发现,拒绝有害指令的训练,能有效抑制模型的伪装行为。也就是说,让模型学会拒绝不好的指令,能让它更真诚。
有趣的是,仅仅提高模型对有害指令的服从度并不会让它更爱伪装。但是,如果训练模型应对普遍威胁或回答特定场景的问题,反而会显著激发它们的伪装行为。【图3】
目前来看,在研究团队设定的实验场景中,主流的大语言模型并没有表现出“伪装合规”的行为。
但研究团队正在进一步探索:如果是在更接近现实的场景中(比如没有明确告诉模型正在训练时),这个结论是否还会成立呢?
原文链接:
代码仓库: