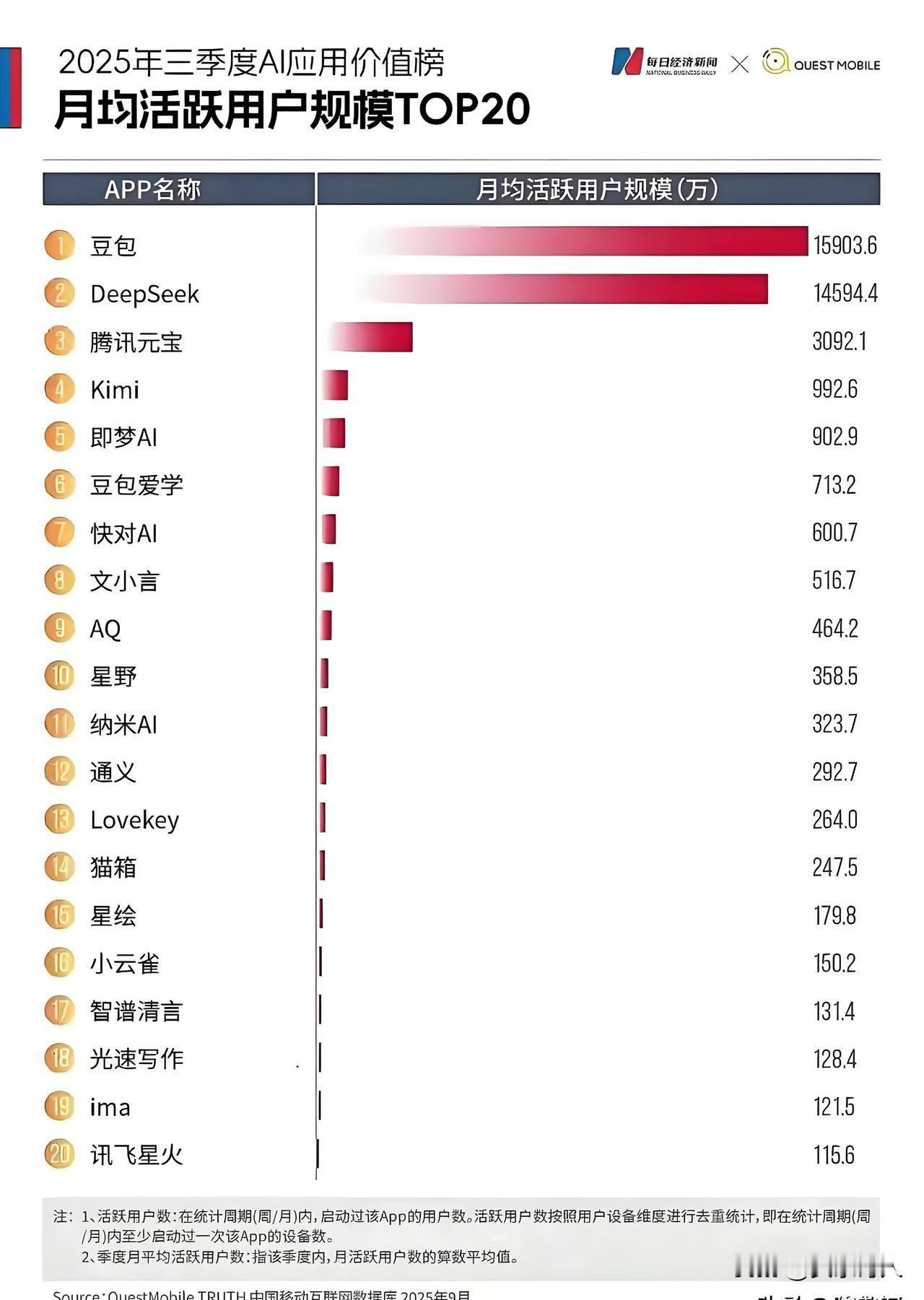
在人工智能与数学推理的融合领域,一项重大突破正在改写AI解决复杂数学问题的能力边界。
媲美人类金牌选手11月27日,DeepSeek正式发布DeepSeekMath-V2模型,引入“可自我验证的数学推理训练框架”,不仅在多项顶级数学竞赛中展现出媲美人类金牌选手的实力,也为构建更强大、可靠的数学智能系统指明了切实可行的研究方向。
值得一提的是,在国际数学奥林匹克(IMO)2025、中国数学奥林匹克(CMO)2024赛场斩获双金牌,在Putnam2024竞赛中取得118/120的近乎满分成绩。
可以说,DeepSeek团队推出的DeepSeekMath-V2模型,用硬核战绩打破了AI数学推理“重答案、轻过程”的困局。
更关键的是,其开源在HuggingFace与GitHub的技术底座,正将“自我验证”这一核心创新转化为全行业的发展动能,为可信AI开辟全新赛道。
目前,模型代码与权重已开源,发布于HuggingFace及GitHub平台。
长期以来,数学AI系统主要关注最终答案的正确性,然而这种评估方式存在明显局限。
DeepSeek团队敏锐地意识到,仅追求最终答案正确率难以保证推理链条的严谨性,特别是在定理证明等需要逐步推导的任务中,一个正确的答案背后可能隐藏着逻辑漏洞或错误的推理过程。
这种认识促使研究团队将焦点从单纯的结果评估转向过程验证。
DeepSeekMath-V2的核心创新在于构建了基于大语言模型的验证器,能够对模型自身生成的证明进行自动审查。
这种自我验证机制不仅提升了推理的可靠性,还创造了一种持续的自我改进循环,模型通过验证过程识别自身缺陷,进而针对性地提升推理能力。
持续自我改进循环以往的方法,无论是监督学习还是基于强化学习(RL),其本质是“以结果论英雄”,模型生成的最终答案若与标准答案匹配,则获得奖励。
这种方法的局限性显而易见,它无法区分一个基于扎实推理得出的正确答案和一个通过猜测或错误推理偶然得到的正确答案。
更重要的是,在高等数学和定理证明领域,许多问题根本不提供具体的数值答案,其核心价值在于论证过程的严密性与逻辑性。
DeepSeekMath-V2引入的“自我验证”框架,正是对这一根本挑战的回应。
也可以说,技术突破已快速转化为跨领域价值杠杆。
科研领域,它能自动完成复杂推导验证,将数学家从繁琐校验中解放,预计可缩短30%理论突破周期。
教育场景中,实时诊断证明漏洞的能力成为个性化辅导核心,头部机构测算可提升8%-12%的VIP续费率。
产业端更具爆发力,在金融衍生品定价、航空软件验证等“零缺陷”需求场景,能将人工审计成本降至1/5,仅B端市场规模就达200亿元。
这种价值释放背后,是AI行业的三大明确趋势,自验证正从数学向代码、法律等领域扩散成为通用底座,“小模型+重验证”比“大模型+轻调”更具经济性,数据生产从“人工标注”转向“机器自标注”已成定局。
敬告读者:本文基于公开资料信息或受访者提供的相关内容撰写,不慌实验室及文章作者不保证相关信息资料的完整性和准确性。无论何种情况下,本文内容均不构成投资建议。市场有风险,投资需谨慎!未经许可不得转载、抄袭!