11月24日,第五届字节跳动奖学金颁奖典礼在北京大钟寺办公区举办。
本届奖学金共吸引了中国和新加坡66所高校的500余名同学报名申请,来自清华、北大、复旦、人大、华中科技大学、香港大学、新加坡国立大学、南洋理工大学等高校的20位学子获奖,覆盖大模型、机器学习、多模态、AI Infra、机器人、AI for Science、硬件等领域。
相比往届,2025年字节跳动奖学金不仅增加了获奖名额,也将奖学金从10万元升级为20万元,含10万元现金,以及10万元专项学术资源补贴,可用于参加学术会议、科研差旅等相关支出。此外,字节跳动还为每位获奖学生的导师提供10万元奖励,以此致敬导师在学子成长与科研道路上的辛勤付出。
颁奖典礼上,字节跳动技术副总裁杨震原对获奖师生表示祝贺,并分享了字节跳动在技术领域的一些探索历程,鼓励同学们保持耐心和热爱,挑战真正有高度的技术难题,为社会创造更大价值。
以下为杨震原分享全文。

大家好,很高兴在字节技术奖学金,这样一个场合见到大家。我自己是一个技术爱好者,2014年我加入字节跳动。从最初负责搭建新的推荐系统开始,到现在已经有快12年了。这些年来,也一路参与了字节很多的技术探索。
说起字节,多数人比较熟悉的还是我们的产品,比如抖音、今日头条、TikTok等。
我的视角可能更技术一些,今天这个机会,我来以我的视角分享一些大家可能没那么熟悉的技术故事。
01.
2014,大规模机器学习与推荐系统
第一版就计划做到万亿(T)级别的特征规模
最初,创始人张一鸣找到我,跟我说,他想用大规模机器学习系统来搭建推荐系统,来解决各种媒体形式,包括图片、文字、视频的推荐。他这个想法很吸引我。
2014年,工业界最大规模的机器学习系统,是搜索广告中已经成熟使用的大规模离散LR(Logistic regression)。把这套原理用在推荐系统上,挑战可不小。那时同时熟悉大规模软硬件工程和机器学习的人不多,而且,除了能够挣到很多钱的搜索广告会使用;其他领域,大家都不愿意花这么大的硬件成本去做计算。
我们第一版就定了一个非常激进的目标:计划2014年做到万亿(T)级别的特征规模。
这里有非常多的挑战,比如系统建模,处理好推荐的优化目标。工程上,存储和计算是最前期的门槛。另外我们也要做好算法的优化。构建目标,做好存储的挑战,以前都分享过了,今天说说优化算法。

LR的优化是成熟技术,但不同的方法效率、效果差异巨大。尤其是超大规模之后。今天很多同学可能不知道当年的优化器的情况。今天SGD系的方法是主流,但2014年,我们搞非常大规模稀疏的逻辑回归的时候,并不是这样。当时CD系的一些方法用的更多。另外,百度的搜索广告使用的优化器是OWL-QN。
我们当时一共就5个人,还有人要去做工程,优化器准备了2套方案。1、SGD-FTRL;2、CDN(Coordinate Descent Newton)。就选了两个人分别负责,同步进行调研。
CDN优化器项目,我们当时预判比较有潜力,初期进展也不错,但最初的上线发现又不太行,就一直改进。2年中,始终有一个小组持续在做。直到SGD的方法都开始找到更多的应用方式后,才终于停了这个项目。CDN优化器项目组里的同学,后来转到了机器学习的其他方向,负责公司很重要的业务。虽然项目并不成功,公司还是很认可他们的探索。
FTRL现在提到的都比较少了,可以认为是基于累计梯度的,基于AdaGrad风格自适应的,L1正则的SGD。这个项目我们进展很快,几个月上线,成功实现了稀疏化万亿特征的目标,并且框架非常灵活。
14年底,我们逐渐引入了FM类算法,后来演化成了更通用的deep learning体系。而且从我们上线的第一天,它就是一个streaming training的系统。
到今天,我们发现streaming更新(training only)的、较浅层的神经网络算法在推荐中依然有着不错的效果。它可能和现在test-time training中的一些问题相关,也许是更近似RNN的一个实现。
02.
2020,科学计算的探索
求解薛定谔方程,就可以模拟世界绝大部分的现象
大概2019年底到2020年,我们讨论过一次,未来AI还能够怎么发展,如何在全社会发挥更加重要的价值?
当时的思考是,只有很大规模的有价值的数据,才能够产生足够有价值的模型和算法。线上世界,推荐、搜索、广告是主流应用。那么,还有什么场景能够产生很多有价值的数据呢?显而易见是现实世界。但现实世界的数据搜集与应用会比较复杂,涉及到无人车、机器人等领域。除了现实世界,我们还想到一点,那就是科学计算。
我们这个世界虽然纷繁复杂,但底层的物理规律是特别简洁的。从量子力学的角度来讲,如果今天有一台计算能力没有上限的机器,我们确实可以从薛定谔方程中解出当前世界中绝大部分的现象(不考虑重力的情况下)。大量的simulation会得到有价值的数据,指导machine learning去进步。得到更好的结果,反过来,又可以改进simulation。
这张图是我们当时的顾问鄂维南院士分享过的一张图,我贴过来了,讲的是不同尺度科学计算的分类。

大家可以看,横坐标代表了空间尺度,纵坐标是时间尺度。这张图代表了物理和科学计算的一些问题。比如最左下角的是第一性原理计算,它包括CCSD、 QMC等方法,它需要去计算多电子的波函数。再上走,分别是做了近似的DFT(密度泛函)。再往上走,不再去描绘波函数,而是使用粒子来做抽象,也就是分子动力学MD(Molecular dynamics),再往上抽象到粒子团簇;最上面抽象的流体力学、有限元等更高抽象的层次。那机器学习在其中的价值是什么呢?图中的L1、L2、L3、L4的意思是,在这些不同尺度的问题上,都可以通过机器学习的方法更好地求解。例如,在最下面量子化学计算角度,采用神经网络来拟合多电子波函数。尽管这些物理规律描述起来特别简单,但计算起来却异常复杂,所以机器学习能够发挥非常大的价值。
· 第一性原理计算
我们从2020年开始在这个方向持续投入。这里有一张同事提供的图,展示了我们在这方面做的一些工作。

图中的横坐标指的是时间,这个领域早期代表性的工作是DeepMind的FermiNet等,2019年我们几个人在会议室里就讨论过这项工作。这个领域叫做NNQMC(神经网络量子蒙特卡洛方法)。大概是什么意思呢?QMC是量子蒙特卡洛,根据变分原理,任何试验波函数计算得到的系统能量总是大于或等于真实基态能量。于是,我们就可以用神经网络去表示一个波函数,然后,在这个波函数上进行采样并计算系统能量。然后,我们就可以按照能量更小方向的梯度去更新神经网络,最终得到一个更优的波函数表示。
粉色部分是我们在2021年之后的几项工作,我们基本上在业界已经做到前沿。
这张图的纵坐标指的是仿真精度,就是与物理实验的接近程度。仿真越接近真实,应用前景就越好。圆的大小表明了仿真体系电子的数量,这个圆越大,也就意味着它有更大的实用价值。
最右上角有一个Scaling Laws with LAVA,这是我们最新的一个成果。我们发现,这个问题和大模型一样表现出Scaling Law,如果我们使用更多参数,就会看到它的仿真精度是持续上升的。这是一个很好的信号,说明我们可能在实用性方面还有很大的突破潜力。
在处理体系范围上,我们提出了首个能使用于固体体系的NNQMC方法,DeepSolid。同时在二维转角材料的研究上也进行了一系列研究。今年的一个重点工作就是将NNQMC用于研究拓扑绝缘体。
拓扑绝缘体具有特别的电学性质,通电后,器件内部没有电流,但在器件边缘产生电流。器件几乎不发热。
拓扑绝缘体“不发热”这个电学性质十分诱人。因为现在用的CPU,GPU都会大量发热,造成能源损耗。如果真能用拓扑绝缘体替代,也许可以制造超级计算机。

· 分子动力学
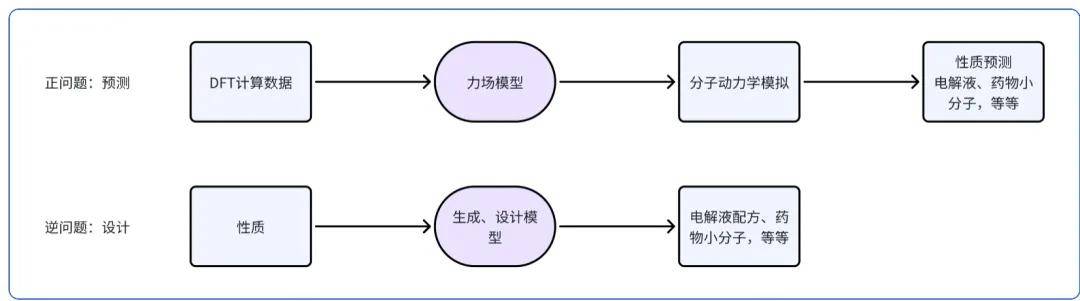
我们在分子动力学上也有很多探索。MD(分子动力学)在鄂维南老师的图中是classic MD这个位置。我们的思路是,先改进正问题。使用更高精度的仿真来给机器学习MD的力场提供更精准的label。DFT(密度泛函分析),是一个合理的层次。我们首先做了DFT的GPU加速工作。我们的GPU4PySCF,实现了GPU加速DFT计算的业界SOTA。相比传统CPU计算程序,实现速度1GPU≈500~1000CPU core的加速,完成相同计算任务算力成本降低1个数量级。
有了更好的label,我们就可以获得更准确的力场模型,进而可以做更准的MD仿真,来做更好的性质预测。
当我们做了很多正问题后,我们就可以再次训练模型,去直接生成可能满足某些性质的小分子的候选,这就是逆问题。这个问题,就是若干工业领域(能源、制药)的核心问题了。我们的团队开发了Bamboo-MLFF和ByteFF两类分子动力学力场,对分子、固体体系的性质进行准确预测。其中ByteFF-Pol目前在无实验数据zeroshot预测电解液性质上实现了业界SOTA的精度。
这些工作不仅仅只在我们的实验里。我们今年已经和BYD成立了联合实验室,会将高通量自动化实验与科学计算算法结合,探索AI for Science在电池材料领域的工业落地应用。目前,GPU加速DFT计算、力场+分子动力学模拟、预测+设计模型均已投入企业合作伙伴的实际应用。
03.
2021,PICO——XR的探索
更多投资基础技术,追求核心体验上大台阶
字节跳动的发展离不开硬件的革新和进步。大屏手机、高清camera是抖音、tiktok这样产品发展的土壤。那,接下来还有什么交互体验可以超过视频呢?
XR是有潜力能带来全新的体验。2021年,字节收购了Pico团队。
收购后,我们有两个产品路线在同时推进。一个是,以当前的产品形态为主,同时投入资源运营视频、直播等内容,较为激进的营销。路线二,是投资基础技术,追求核心体验上一个大台阶。
2023年,我们决定减少内容和营销投入,更坚定的投入技术路线。这是因为当时产品的硬件体验尚未成熟,无法支撑大规模市场应用。这个调整当时还带来了一些误解,不少人说字节不做这个方向了。其实恰恰相反,23年开始,我们在XR上的技术投入比以前更多。
接下来,我来分享一些路线二中的一些技术探索。
首先是清晰度。
XR要模拟人眼观察真实世界的体验,关键指标是PPD(每度像素数),就是说人眼睛看一个度(degree),大概有多少像素。这个指标和观看距离、屏幕 PPI(像素密度)强相关。
PPD大于30大概可以看文字,40会比较清晰。PPD到60的视觉体验接近视网膜级清晰度。在 2021年,Pico3、Quest2这些主流产品的PPD 其实是小于20的,而且这还是中心区域,如果到边缘还要更差。如果一个XR产品无法看清楚字,那使用场景肯定就很局限,这是要解决的一个重要挑战。
2022年我们开始研究怎么能做好,最后决定和供应商启动MicroOLED定制。MicroOLED是一种在单晶硅片上制备主动发光型OLED器件的新型显示技术。相比于其他显示技术(如高PPI的 LCD液晶屏),microOLED在实现单眼4K等级的超高分辨率时,仍然能够保持更小的面板尺寸。这使得光学显示系统得以进一步缩小,从而让MR头显轻便的同时获得更高的PPI和整体清晰度。

如果我们去对比iPhone,iPhone17ProMax是 6.9英寸的,它的PPI是460。我们在2022年定制MicroOLED的目标是什么呢?我们要做到近4000PPI,大概是iPhone17接近九倍的量级,所以这个事情的挑战是非常大的。
MicroOLED虽然可以有超高的PPI,但它每个像素点都特别小,导致屏幕亮度上限较低。我们通过导入微透镜(MLA)来提升亮度,副作用是色亮度均一性变差。这就需要,结合光学设计,通过主光线角(CRA)定制和系统性补偿上的一些工作,让亮度和色亮度均一性同时达到最优状态。

在我们启动的那个时间点,市场上现有的产品在很多维度(比如分辨率、亮度、功耗、成本等等)都无法达到我们的要求。我们只能自己和供应商一起把上面提到的这些硬件、软件、算法的东西都解决好才行。我们大概2022年开始启动,到今天,终于解决的比较好了。最终的成品,平均PPD40,中心区域超过45,应该说是行业领先了。
MR 也是重要的技术挑战。
传统的VR无法看到现实,更无法做到融合。MR(Mixed Reality)代表了新一代的技术:能够看到现实,并且能够把虚拟的物体与现实世界融合。但这也带来巨大的技术挑战。
比如SLAM技术,核心是让头显精准感知用户的位置与姿态角度;而为实现运动补偿,还需进一步估算运动速度。同时,微显示屏上的高清图像,通过光学镜头后,会有畸变,比如边缘被拉伸、中心被放大,所以要做逆畸变处理。从源头到输出,整个过程的计算量非常大,而且都是对高清、高帧率的视频做实时的处理,又需要特别低的延迟。在有限的功耗空间里,这个问题就特别困难。
如果这方面做得不好,就会让人产生眩晕感。如何低延迟、高精度的完成这个计算,就是核心问题。这里面,就需要有强大且低功耗的算力,需要专用的芯片才能够做到。
于是,2022年6月我们正式立项,全链路自研了一颗头显专用的消费电子芯片来解决这个处理瓶颈。芯片在2024年回片,目前进入量产阶段,各项指标均达到设计要求。
目前在实测中,我们的系统延迟可以做到12毫秒左右,这是非常不容易的。即便是世界顶尖的公司,用软件来做的话,也很难在不明显牺牲画质的前提下把延迟压到25毫秒以内。

高精度6DoF测试

高精度时延测试系统


通用3D重建机制与高精度手势数据采集
交互的挑战也非常重要。我们如果希望做虚实融合,那需要对现实环境做识别。我们需要非常高精度的ground truth进行校准与训练。为此,我们建设了专业的高精度测试系统。
新的MR设备交互,需要eye tracking,hand tracking,这些也都需要高精度的ground truth。只有搜集到较广泛的数据,才有机会让体验在更广泛的人群上保持鲁棒的高体验。所以我们也做了专门的3D重建机制与高精度手势数据采集系统。
XR的路还很长,挑战也很多。上面只是举了一些技术的例子。26年我们就会有新的产品发布,期望未来我们通过持续的技术研发,能够给大家带来体验更好的产品。
04.
2023,大模型的时代
2022年11月30日,ChatGPT横空出世,2023年引起广泛关注。我们在2021年,有过一次机会早点关注到。
当时我们一个同事,也训练了一个大语言模型,但我们不知道干什么用。我们想,是否可以用来改进搜索?于是把这个pretrain的LLM,在搜索的relevance任务上去fine tune。结果和bert模型做对比。提升幅度很小,计算cost又增加很多。于是得到一个结论,这个LLM目前没什么用。所以还是很没眼光。
不过公司调整得很快,在2022年,我们在这个方向上开始投入。现在,我们也取得了一些成果。应用上大家可能更熟悉一些,豆包是中国最流行的AI对话助手,火山引擎的大模型服务也受到客户的认可,根据IDC的报告,火山是中国MaaS市场的第一名。
技术上我们也有自己的特点。得益之前的一些积累,我们在Infra方面做的还是比较好的。我们很早就建设了大规模的稳定训练系统MegaSacle,在训练任务上,MFU(浮点运算利用率)超过55% ,这是当时主流开源框架的1.3倍以上,效果还是很不错的,有兴趣的可以去看我们24年年初发的相关论文。
我们在模型结构、自研服务器上也有很多探索,这也让我们实现了大模型的低调用成本。所以,我们在通过火山引擎提供服务的时候,才能够打破业界价格下限,同时保证自己有不错的毛利。
我们的GenMedia模型、VLM、语音模型表现很好,长期属于国际一流水平。另外,在大模型的研究方面还有一些更前沿的探索,我们叫Seed Edge计划。我不展开讲了。
对未来大模型如何发展,我也不知道,但是我可以提几个小问题,和大家一起讨论。
大家都在谈论AGI,但什么是AGI,应该如何评估是否到达AGI了?
大家都有不同的看法,我说说我的。我们可以做一个思想实验。假设把全世界的人类的工作(包括最初级的工作,也包括最顶尖科学家的工作)全部拿出来,让AI去做。我们定一个比例,比如95%,如果95%的工作AI全部都能完成,我们可能就可以说真的达到AGI了。
AI的能力发展是非常不均衡的,今天大模型可以在国际数学奥林匹克上拿到金牌,这恐怕已经超过了99.9%的人类。但对于很多工作,比如,一个初中生可以胜任的电话客服工作,大模型目前还不能完全做好。
那我们从补短板的角度继续去思考一下,为什么会这样?一个比较直观的,是模型的学习能力。
目前的大模型是分阶段的,训练阶段和推理阶段。当模型部署到线上开始服务,就不再被训练,或者说,只能做in context learning。这和人类是不一样的。人类是持续在学习的。
比如电话客服,一个名校的博士可能刚开始也不知道怎么做好,但人可以很快学习,可能用不了几天就可以把工作做好了。而且人的学习效率很高,并且充分利用社会环境,比如他可以问一下老员工或者经理该怎么做。
所以说,如何让大模型提高学习能力,是一个比较重要的问题。最好是每一个人都可以以他的方式教知识给大模型。
第二个能力是IO能力,也就是和这个世界交互的能力。这个也显而易见。即便在数字世界,虽然目前的大模型,在视频、图片合成方面的能力已经超过人类,但是在众多内容理解、界面操作等方面,模型还是和人有比较大的距离。
这些都是非常基础,但非常值得研究的问题。
有人说,2023年是人类历史上的第3个奇迹年,我觉得丝毫不为过。AI的发展给人类社会预期会带来巨大的变革,这场变革里会有无数的问题,需要技术人去探索,去解决。
字节跳动也会在大模型等前沿领域,持续耐心的探索下去,希望能够为人类社会贡献自己的力量。