「NAS、键盘、路由器······年轻就要多折腾,我是爱折腾的熊猫,今天又给大家分享最近折腾的内容了,关注是对我最大的支
「NAS、键盘、路由器······年轻就要多折腾,我是爱折腾的熊猫,今天又给大家分享最近折腾的内容了,关注是对我最大的支持,阿里嘎多」
引言
虽说中文目前在国际的影响力越来越大,但很多时候一些冷门的资源或者短片都还是生肉,没有官方中配就算了,甚至很多连中文字幕都没有。虽说大部分视频网站都有翻译与字幕功能,但很多其实体验真不咋样。

而随着AI和NAS算力的飞速提升,许多全自动化的翻译项目应运而生,熊猫我也把翻译的任务转移到现役的极空间NAS上,“拯救了”我的翻译需求!
Chenyme-AAVT的功能非常齐全,不仅能通过Whisper模型进行声音识别,还能生成字幕文件,最后通过大模型进行翻译。同时支持音频识别,视频识别和字幕翻译。除了这些,它还可以利用AI直接生成视频的图文博客,并支持声音模拟!项目现在在GitHub开源,地址是:https://github.com/chenyme/Chenyme-AAVT。
部署准备
Whisper模型现在已经全面转到本地了,所以本地项目部署我们需要自行下载模型文件,模型下载地址为:https://huggingface.co/Systran。
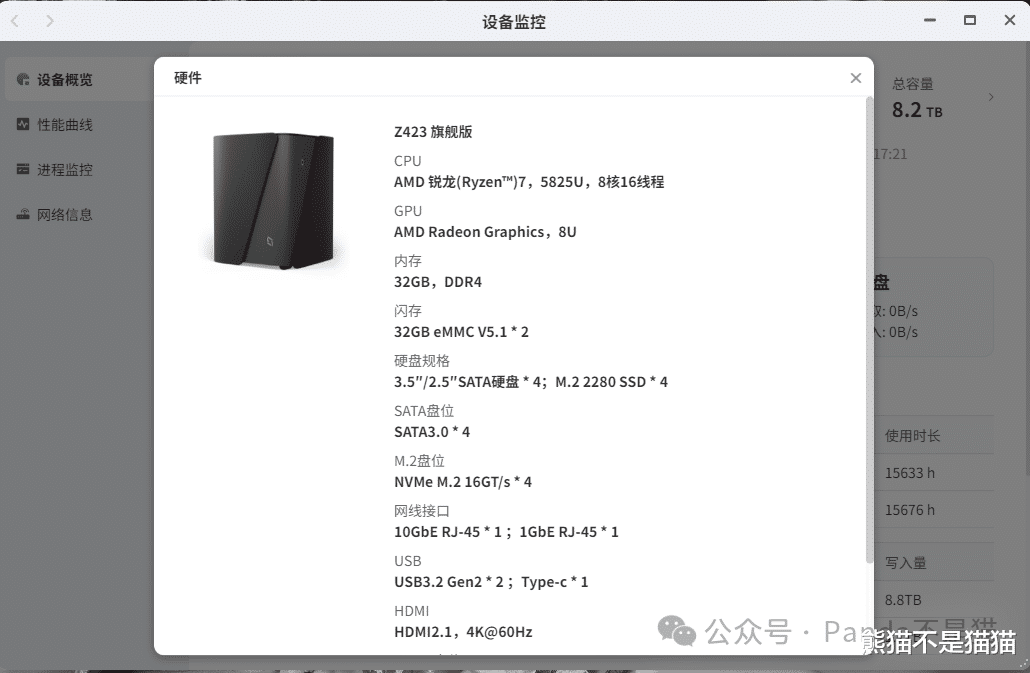
这里熊猫用的是极空间Z423旗舰版,因为项目支持GPU和FFmpeg加速,所以模型的选择自然是越大越好了,当然自身设备的性能也要能跟上才行,理论来说性能越高自然识别速度越快,但这也受视频长度影响。
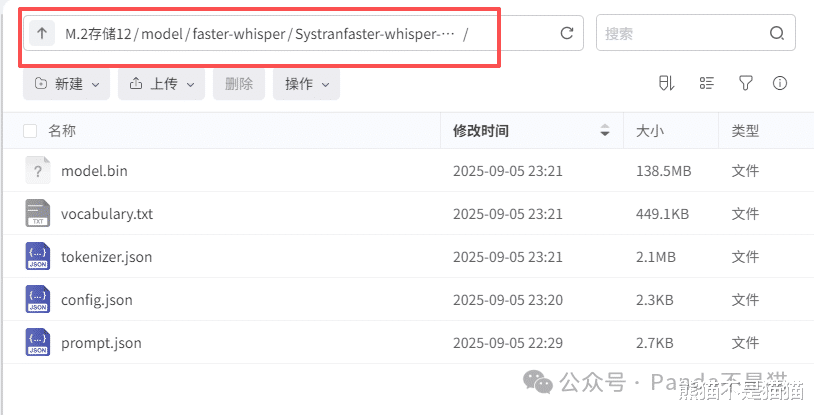
模型下载之后我们需要得到config.json、model.bin、README.md、tokenizer.json、vocabulary.txt这几个文件,同时在极空间中新建文件夹model用来存放模型文件,模型的所有文件需要存放在同一文件夹内,最后的目录树规则应该是这样的,model\faster-whisper/xx模型文件夹。项目部署
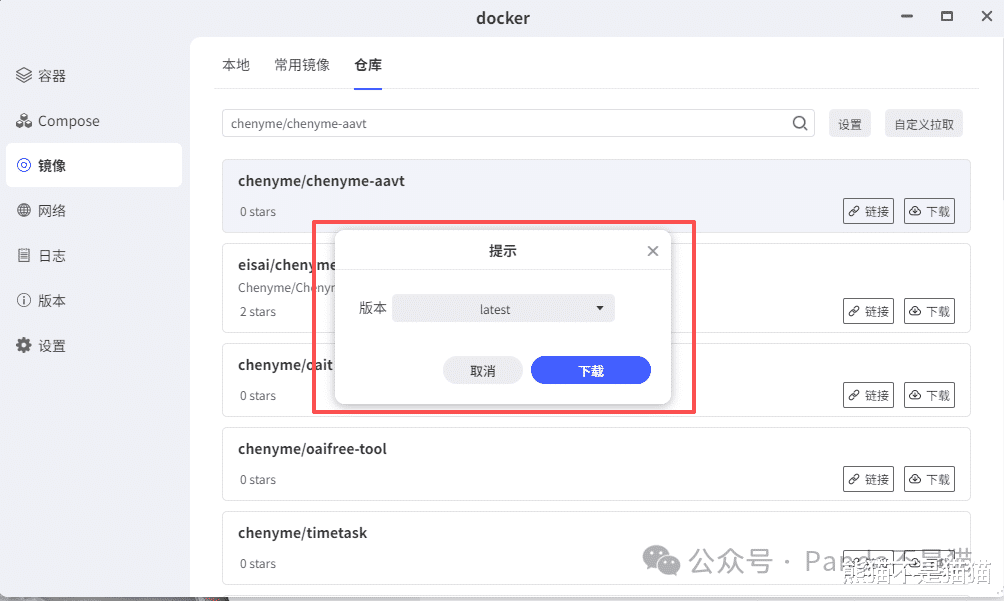
做好准备工作之后我们就可以拉取镜像了,打开极空间的Docker,在镜像仓库中输入镜像名:chenyme/chenyme-aavt。随后直接下载就行,版本选择latest即可。
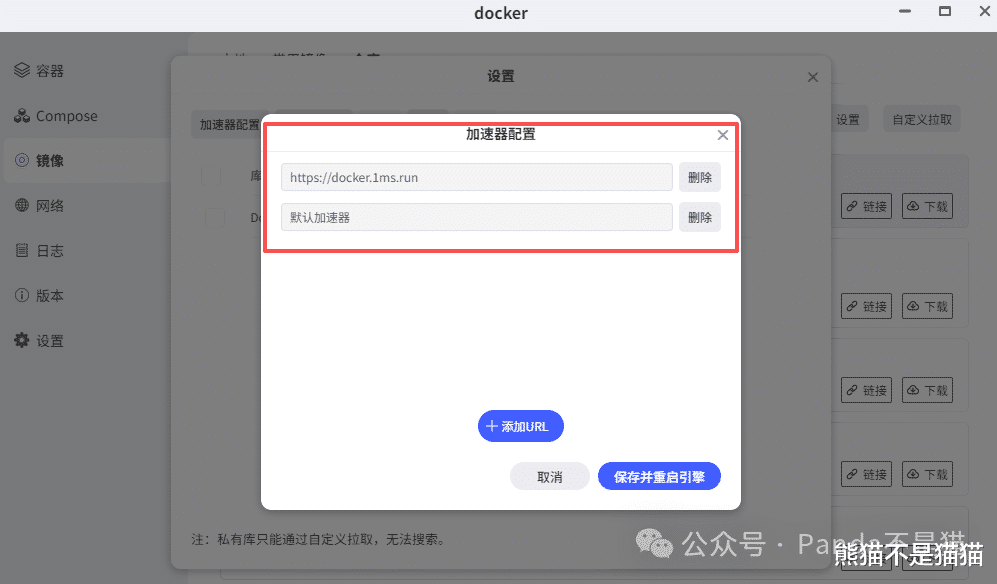
整个镜像完整下载下来有7.4G,所以整个过程需要耐心等待,如果没有速度可以尝试换一下加速器配置,这里比较推荐docker.1ms.run,稳定好用。

拉取完镜像之后在本地镜像中双击镜像,通用设置这里记得关闭性能限制,同时可以开启核心显卡调用与特权模式,这样方便后续调用GPU加速。
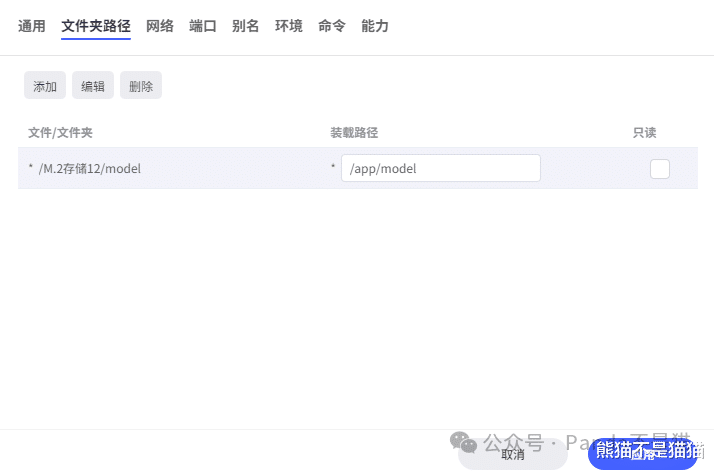
文件夹路径这里,我们新建路径,转载路径为/app/model,本地路径则是我们创建的model模型文件夹。
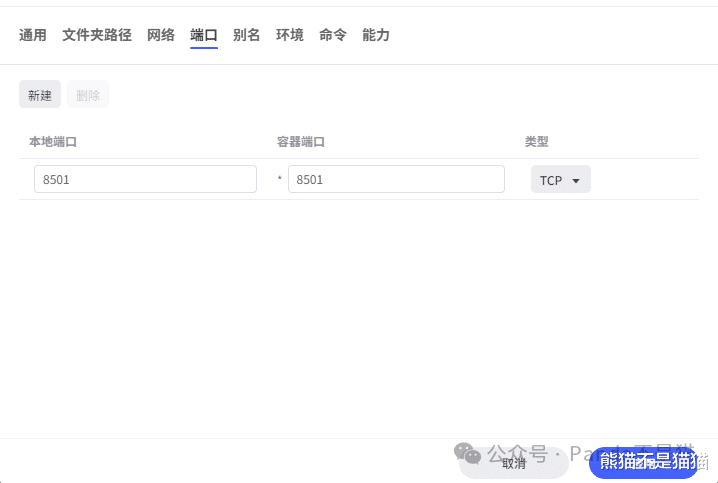
最后则是端口,容器端口为8501不可更改,左边本地端口根据自身NAS的端口占用情况来定,有冲突换就行了,默认8501也可以。

所有设置完毕之后点击应用就能启动容器了,这时候查看容器日志,能看到首次使用的登录密码,默认都是chenymeaavt。项目使用

通过极空间的远程访问,我们就能来到项目的主页了,首次登录需要输入验证密码chenymeaavt。主页提供了AI助手,可以在这里问一些使用教程的问题。
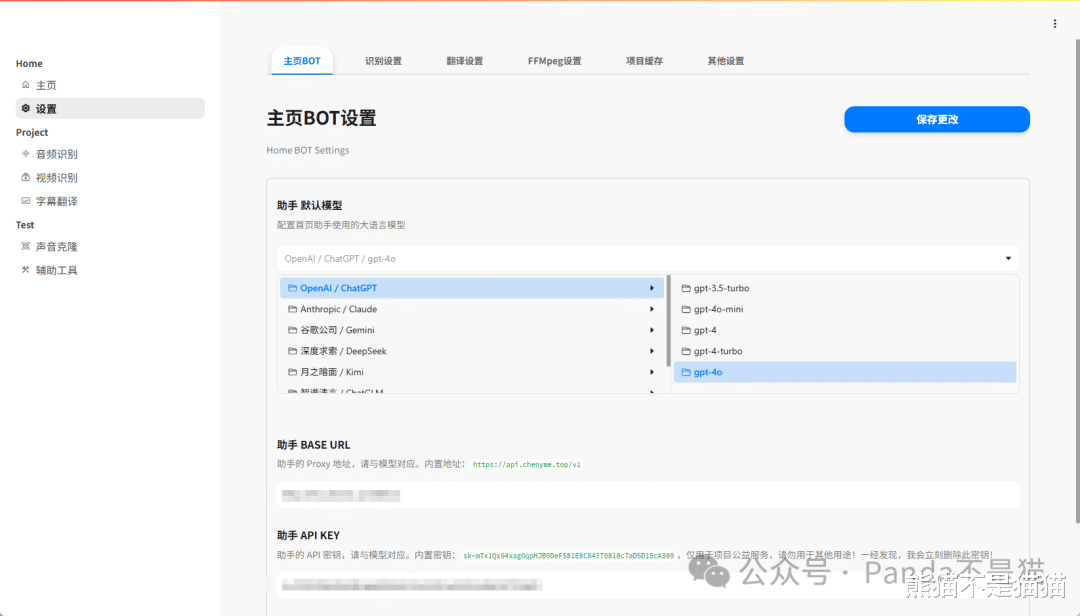
侧边栏能看到音频识别、视频识别、字幕翻译以及声音克隆等功能,不过正在使用之前我们还需要进到设置界面设置一些东西。
主页的AI助手也支持模型设置,这里可以更换模型,模型的类型还是非常多的,国际主流的GPT、Gemini与国内的deepseek和kimi等等都支持,同时也可以更换API对接地址。
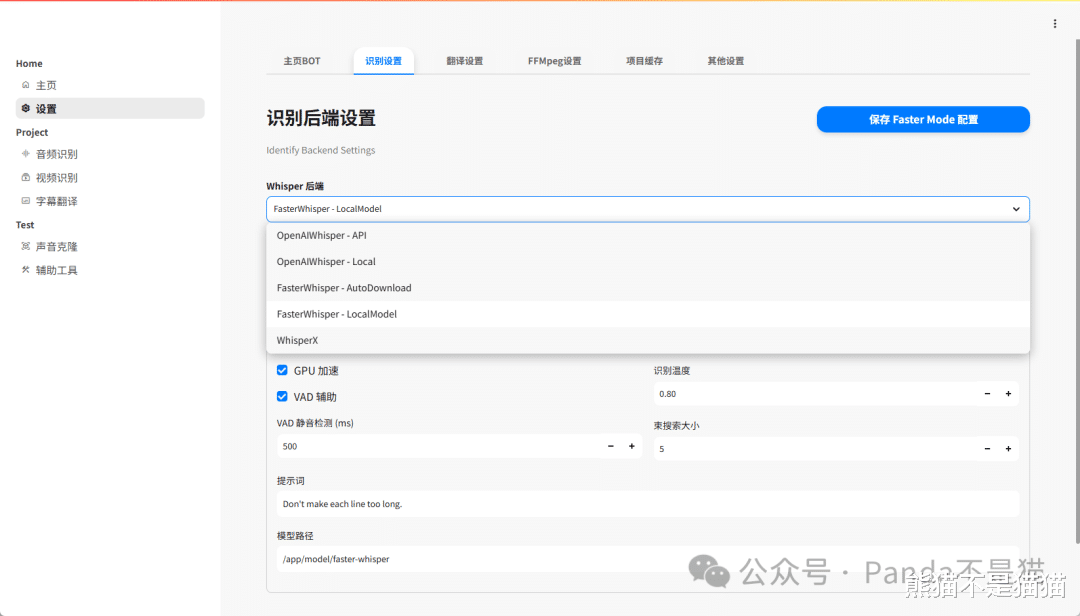
紧接着是识别后端的设置,这里我们选择FasterWhisper - LocalModel,此时项目就会调用我们自行下载的模型,在下方还可以选择GPU加速与VAD辅助,想要精度高可以调整VAD辅助检测。
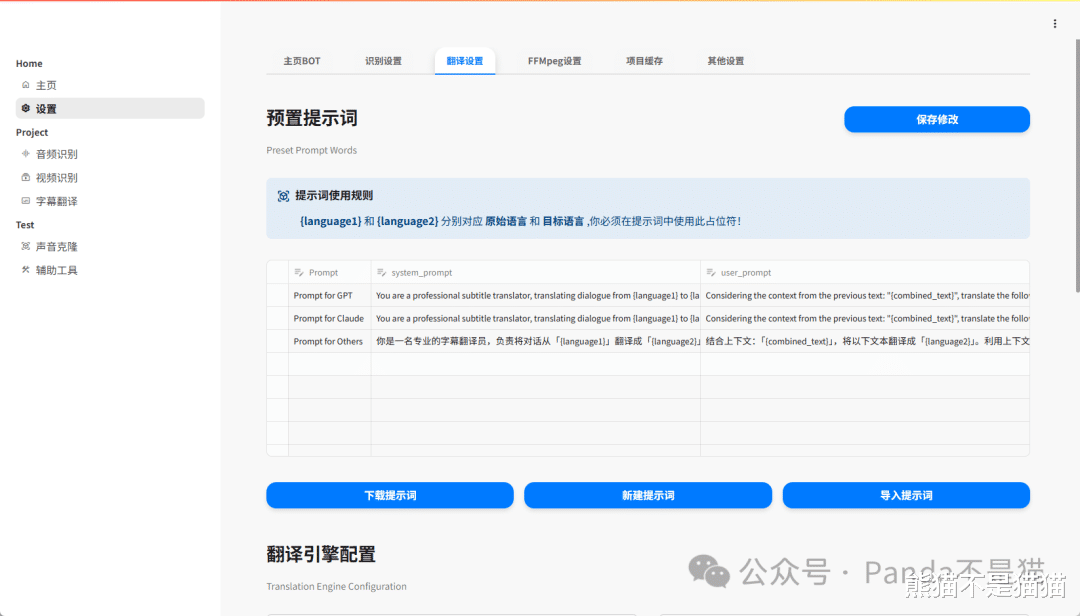
翻译设置这里往下翻也有非常多的模型设置,同时也支持提示词的添加和修改,如果没有特殊需求,默认即可。
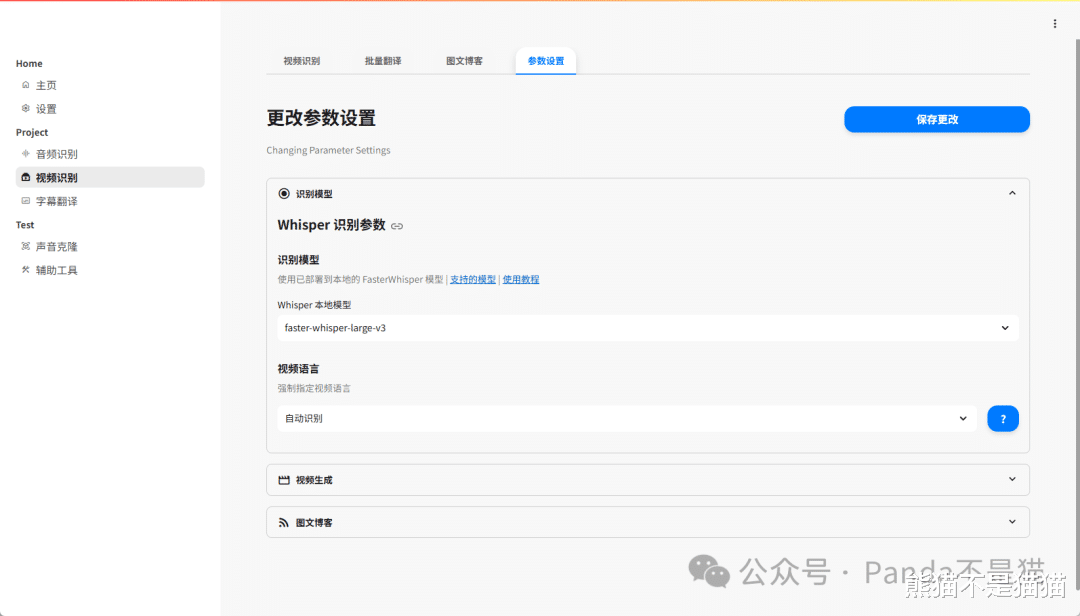
点击下方的视频识别,能看到顶部四个选项,分别是视频识别、批量翻译、图文博客以及参数设置,在使用之前我们需要先检查参数设置,识别模型能看到已经正常加载了。
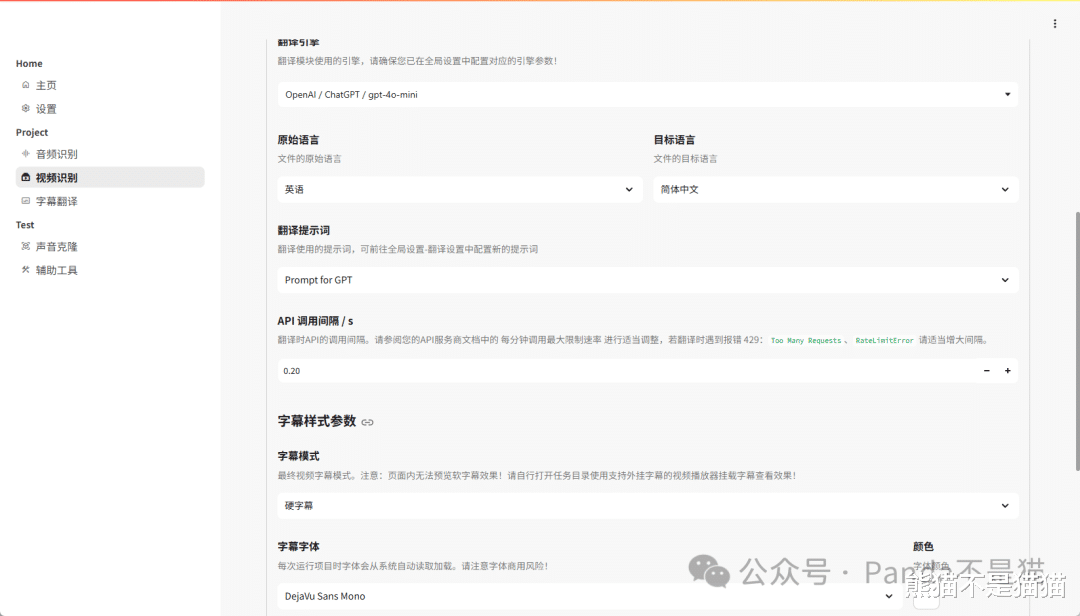
再往下能看到翻译设置和字幕设置,这里可以调节字幕的字体与字号。最后则是图文博客的模型选择和一些详细设置了。
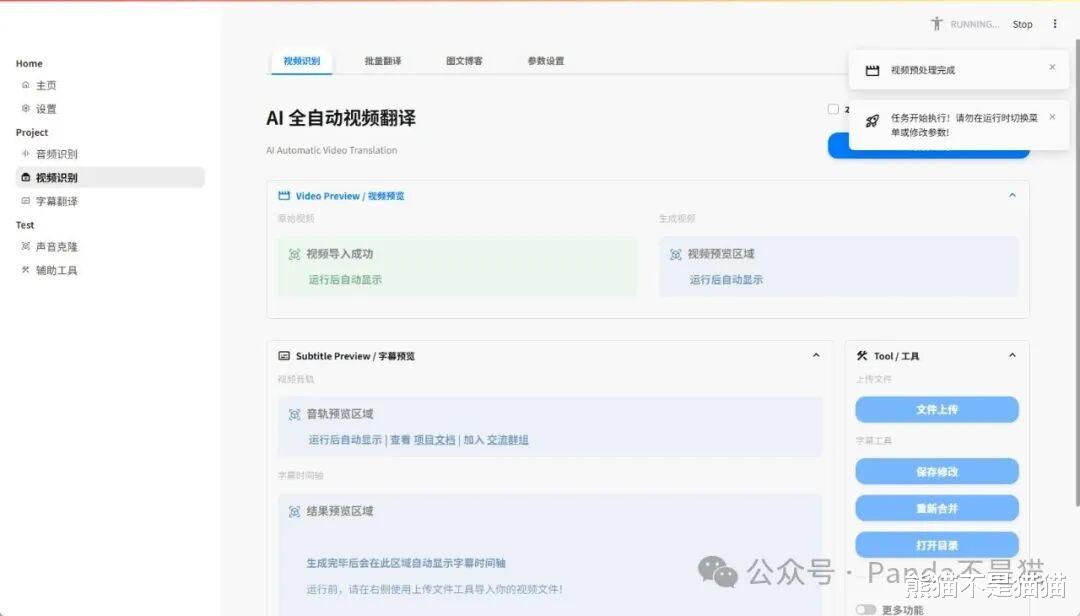
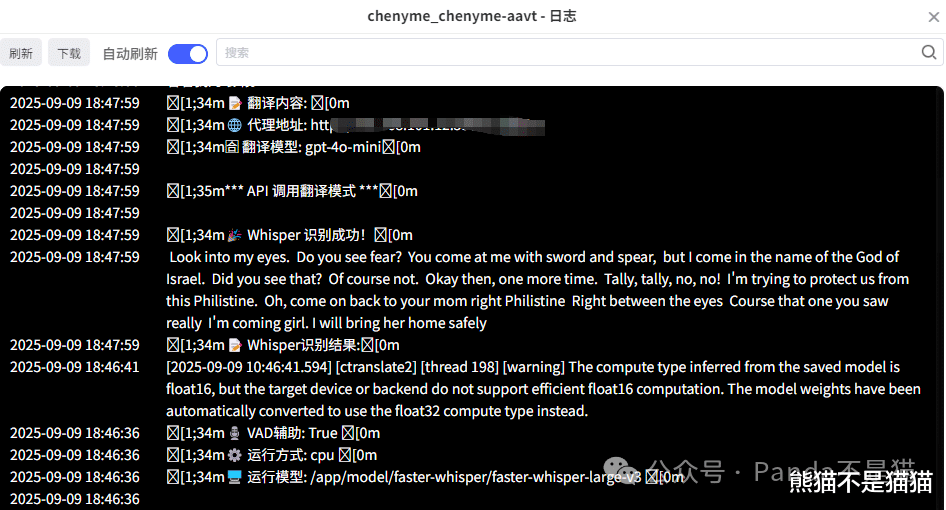
这里熊猫选择了一段5分钟的英文短片,首先项目会调用我们下载的模型进行音频识别,这时候的CPU调用大概在28%左右,随后会对字幕进行分离与翻译,这个阶段因为用到的是在线的API,所以并不会占用本地的性能。
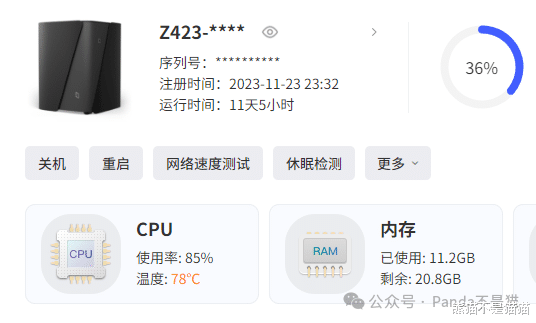
最后项目会将字幕文件嵌入视频并生成新的视频文件,这个过程需要用到FFmpeg,此时能看到Z423的CPU调用来到了90%左右,整个过程会因视频的长度来决定生成速度。
最后,项目会生成两个预览窗,同时播放原始视频和生成视频,在下方还能看到字幕的预览。
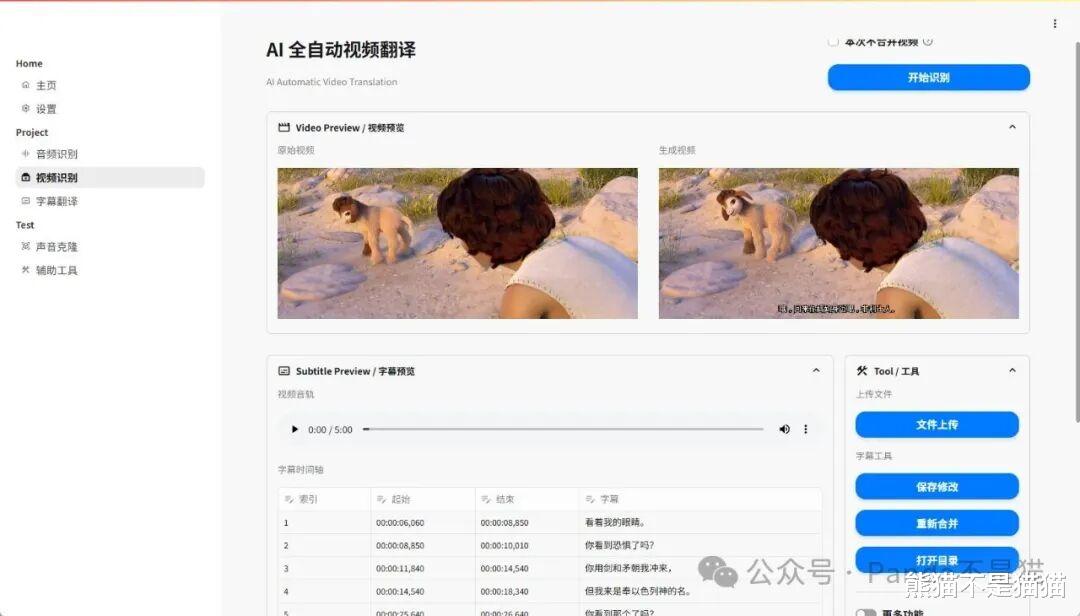
音频识别的道理也是同样的,先进行音频识别,在进行字幕生成。图文博客这个功能比较新鲜,项目会提取视频的关键帧与音频文件,最后针对音频和视频关键帧进行AI分析,最后获得一篇符合视频内容的图文内容。写在最后
Chenyme-AAVT 这套方案让视频翻译和字幕生成变得简单和高效,整个体验非常丝滑,无论是日常追油管,还是处理一些需要翻译的外语视频,都能轻松应对,推荐有需求的可以部署尝试。
以上便是本次分享的全部内容了,如果你觉得还算有趣或者对你有所帮助,不妨点赞收藏,最后也希望能得到你的关注,咱们下期见!
