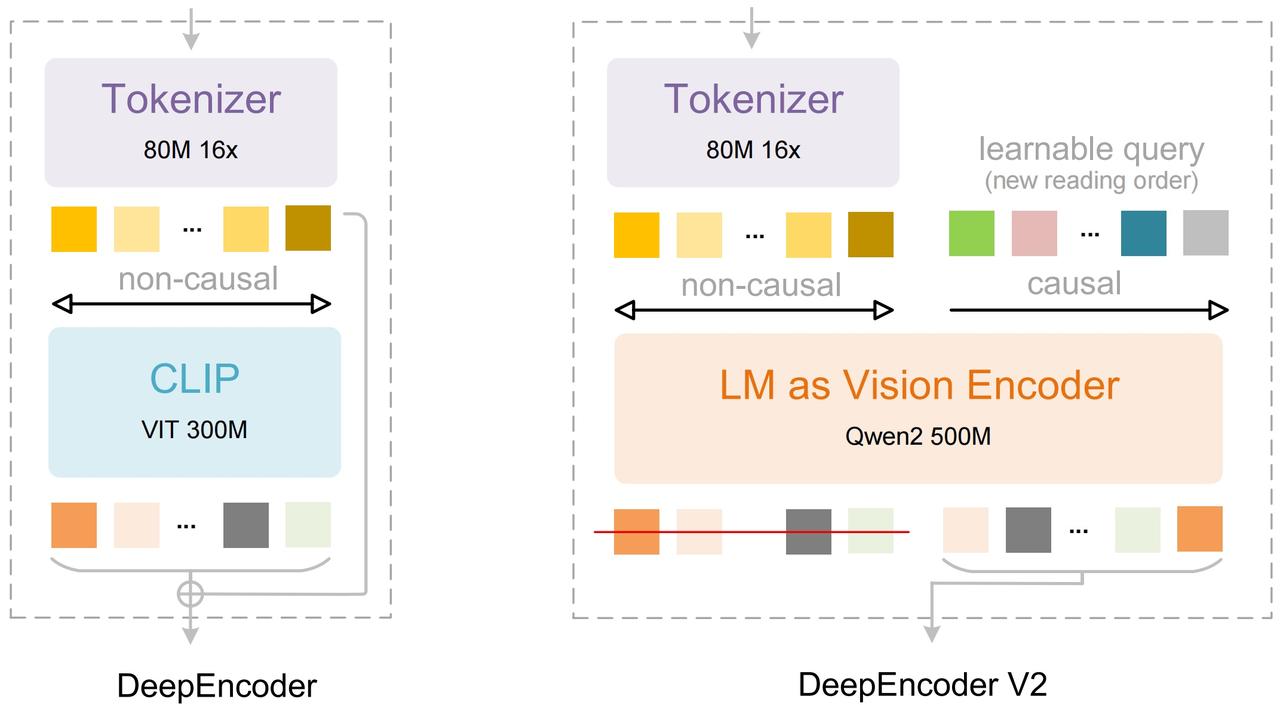
DeepSeek-OCR-2 上线,性能大幅提升 昨天,深度求索 DeepSeek 正式推出新一代文档解析模型「DeepSeek-OCR 2」,核心升级来自全新的视觉编码器架构 DeepEncoder V2。 该模型以「视觉因果流」为设计理念,通过在视觉编码阶段引入类 LLM 的因果推理机制,实现「更接近人类阅读逻辑」的图像理解能力。 在实际表现上,DeepSeek-OCR 2 在 OmniDocBench v1.5 基准测试中取得 91.09% 的整体得分,相比上一代 DeepSeek-OCR 提升 3.73%,并在阅读顺序(R-order)等关键指标上显着降低编辑距离(ED),显示其在复杂文档布局理解上的优势。 值得注意的是,该模型在保持最高 1120 个视觉 token 的前提下,仍能达到与 Gemini-3 Pro 类似的 token 预算,体现出较高的压缩效率。 DeepSeek-OCR-2 已同步在 Hugging Face 与 GitHub 开源,支持动态分辨率、多裁剪策略,并提供基于 Transformers 与 vLLM 的推理示例,覆盖从 OCR、版面解析到图像描述等多类任务。 官方强调,该架构未来有望扩展至多模态统一编码器,为图像、文本、语音等多模态输入提供共享的因果推理框架。